uniq Command in Linux
The uniq command in Linux is a powerful utility designed to filter out duplicate lines from text files or standard input. It is commonly used to simplify data, analyze logs, and clean up repetitive entries in text-based files. By isolating unique lines or counting occurrences of duplicates, the uniq command helps users manage and process text efficiently.
The uniq command works best when used in conjunction with the sort command, as uniq only identifies adjacent duplicate lines. Sorting the input ensures that all duplicates are grouped together, allowing uniq to perform its task effectively.
Table of Contents
Here is a comprehensive guide to the options available with the uniq command −
- What is uniq Command in Linux?
- Syntax of uniq Command
- uniq Command Options
- Examples of uniq Command in Linux
What is uniq Command in Linux?
The uniq command helps you manage text files or input streams by handling duplicate lines. You can use it to see which lines are unique, find out how many times a line is repeated, or display only the repeated lines. This tool is very useful for analyzing logs, cleaning up data, and processing text efficiently.
Syntax of uniq Command
The basic syntax of the uniq command is −
uniq [OPTION]... [INPUT [OUTPUT]]
Where,
- [OPTION] − Flags that modify the behavior of the command.
- [INPUT] − Specifies the input file to process. If no file is provided, uniq reads from standard input (STDIN).
uniq Command Options
The uniq command includes several options that allow users to customize its functionality −
| Options | Description |
|---|---|
| -c, --count | Adds a prefix to each line indicating how many times it appears in the input file, including duplicate lines. |
| -d, --repeated | Outputs only the lines that are repeated in the input. |
| -D | Outputs all occurrences of duplicate lines, preserving their original count in the input. |
| --all-repeated[=METHOD] | Similar to -D, but introduces the option to separate groups of duplicates with an empty line. The METHOD parameter can be −
|
| -f N, --skip-fields=N | Skips the first N fields (words) in each line when comparing for duplicates. |
| --group[=METHOD] | Shows all lines in the input file and uses an empty line to separate groups of repeated and unique lines. The available METHOD values are −
|
| -i, --ignore-case | Makes the comparison case-insensitive, treating lines such as "Hello" and "hello" as duplicates. |
| -s N, --skip-chars=N | Ignores the first N characters of each line during comparison. |
| -u, --unique | Filters the output to include only lines that appear once in the input, excluding all duplicate lines. |
| -z, --zero-terminated | Changes the line delimiter from a newline (\n) to a null character (\0), making it suitable for null-terminated input streams. |
| -w N, --check-chars=N | Compares only the first N characters of each line, ignoring the rest. |
| --help | Displays a help menu with brief descriptions of all the command's options and exits. |
| --version | Outputs the current version of the uniq command installed on the system and exits. |
Examples of uniq Command in Linux
Here are few practical examples of uniq command on Linux environment −
- Filtering Duplicate Lines in a Sorted File
- Counting the Occurrences of Each Line
- Displaying Only Repeated Lines
- Grouping Repeated and Unique Lines
- Ignoring Case Sensitivity in Comparison
Filtering Duplicate Lines in a Sorted File
When processing large log files, duplicate entries can clutter the data. To remove duplicate lines −
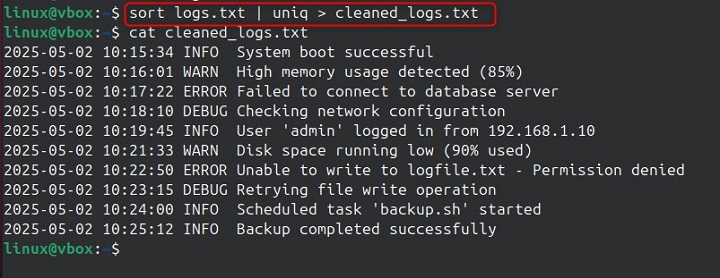
sort logs.txt | uniq > cleaned_logs.txt
This command organizes logs.txt by sorting similar lines together and then removing duplicates right next to each other with uniq. The cleaned result is saved as cleaned_logs.txt, which contains only one copy of each line. This process makes it easier to review and analyze the log files.
Counting the Occurrences of Each Line
To count how many times each line appears in a file −
sort logs.txt | uniq -c > counted_data.txt
The -c option prefixes each line with the number of times it occurs in the input file after sorting. For example −
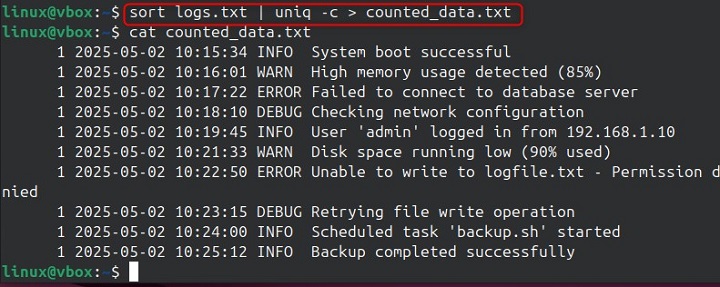
This output is helpful for identifying the frequency of specific events or values in logs or datasets.
Displaying Only Repeated Lines
To extract lines that are duplicated in the input file −
sort logs.txt | uniq -d > duplicate_transactions.txt
The -d option isolates lines that appear more than once in the file. These repeated entries are written to duplicate_transactions.txt. This is useful for detecting duplicate transactions or repeated log entries in a dataset.

Grouping Repeated and Unique Lines
To display all lines from the input file with groups separated by blank lines −
sort logs.txt | uniq --group=separate > grouped_records.txt
The --group=separate option adds empty lines between groups of repeated and unique lines, making the output more readable. This approach is ideal for categorizing large datasets or organizing repetitive data.
Ignoring Case Sensitivity in Comparison
To treat lines with different cases (e.g., "Linux" and "linux") as duplicates −
sort -f mixed_case.txt | uniq -i > normalized.txt
The -i option enables case-insensitive comparison, making entries like "HELLO" and "hello" identical. This is useful for normalizing text data from diverse sources while filtering duplicates.
Conclusion
The uniq command in Linux is an essential tool for simplifying data analysis and processing repetitive text. By removing duplicate lines, counting occurrences, or isolating unique entries, it allows users to clean up datasets and streamline workflows effectively.
When paired with the sort command, uniq becomes even more powerful, enabling accurate handling of adjacent duplicates and providing highly customizable output.
For anyone managing large text files or analyzing complex data, mastering the uniq command is crucial for efficient and optimized Linux operations.
