pdftotext Command in Linux
The pdftotext command in Linux reads a PDF file and converts its content into a text file. The pdftotext reads a PDF file and converts its content into a text file. If no text file is specified, it creates one with the same name as the PDF but with a .txt extension. Using a dash (-) as the text file name displays the output directly in the terminal instead of saving it.
Table of Contents
Here is a comprehensive guide to the options available with the pdftotext command −
Syntax of pdftotext Command
The syntax of the pdftotext command is as follows −
pdftotext [options] [PDF-file [text-file]]
In the above syntax, the [options] field is used to specify optional flags that modify how the command works. The [PDF-file] is the input file that needs to be converted. The [text-file] is the output text file where the extracted content will be saved. If omitted, the output file will have the same name as the input PDF but with a .txt extension.
pdftotext Command Options
The options of the Linux pdftotext command are listed below −
| Option | Description |
|---|---|
| -f <int> | First page to convert |
| -l <int> | Last page to convert |
| -r <fp> | Resolution, in DPI (default is 72) |
| -x <int> | X-coordinate of the crop area top-left corner |
| -y <int> | Y-coordinate of the crop area top-left corner |
| -W <int> | Width of crop area in pixels (default is 0) |
| -H <int> | Height of crop area in pixels (default is 0) |
| -layout | Maintain original physical layout |
| -fixed <fp> | Assume fixed-pitch (or tabular) text |
| -raw | Keep strings in content stream order |
| -nodiag | Discard diagonal text |
| -htmlmeta | Generate a simple HTML file, including the meta information |
| -tsv | Generate a simple TSV file, including the meta information for bounding boxes |
| -enc <string> | Output text encoding name |
| -listenc | List available encodings |
| -eol <string> | Output end-of-line convention (unix, dos, or mac) |
| -nopgbrk | Don't insert page breaks between pages |
| -bbox | Output bounding box for each word and page size to HTML. Sets -htmlmeta |
| -bbox-layout | Like -bbox but with extra layout bounding box data. Sets -htmlmeta |
| -cropbox | Use the crop box rather than media box |
| -colspacing <fp> | Spacing allowed after a word before considering adjacent text to be a new column, as a fraction of the font size (default is 0.7) |
| -opw <string> | Owner password (for encrypted files) |
| -upw <string> | User password (for encrypted files) |
| -q | Don't print any messages or errors |
| -v | Print copyright and version info |
| -h, -help, --help, -? | Print usage information |
Examples of pdftotext Command in Linux
This section explains the usage of the pdftotext command with examples −
Converting a PDF to a Text File
To convert a PDF to a text file, use the following command −
pdftotext sample.pdf

The above command converts the sample.pdf file to a text file and saves it in the current working directory with the name of sample.txt.
Converting Specific Pages of a PDF File
To convert the specific pages of a PDF file, use the -f or -l options. For example, to convert page 2 to page 4 of a PDF file to a text file, use the following command −
pdftotext -f 2 -l 4 sample.pdf
Preserving the Text Layout of a PDF File
The -layout option in pdftotext is used to preserve the physical appearance of the text as closely as possible to how it is laid out in the original PDF.
pdftotext -layout sample.pdf
By default, the pdftotext tries to output the text in reading order. This means text is extracted in a logical flow, ignoring the physical structure, such as columns or specific text alignment.
Displaying Text Directly in the Terminal
To display the text directly in the terminal, use the dash (-) with the pdftotext command in the following way −
pdftotext sample.pdf -

Cropping a Specific Area of the PDF
To extract text from a specific area of the PDF file, use the -x, -y, -W, and -H options.
pdftotext -x 100 -y 50 -W 300 -H 200 sample.pdf

Using Specific Encoding for Text Output
Use the -enc option to use specific encoding for the text output. To list all the supported encodings, use the following command −
pdftotext -listenc
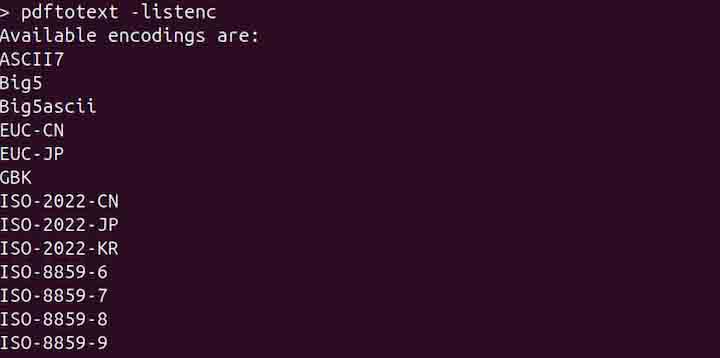
To set encoding, use the command given below −
pdftotext -enc UTF-16 sample.pdf
Excluding Diagonal Text from the Output
To exclude the diagonal text from the output, use the -nodiag option −
pdftotext -nodiag sample.pdf
The diagonal text is specifically used for watermarks.
Skipping Page Breaks
To skip the page breaks between the pages, use the -nopgbrk option −
pdftotext -nopgbrk sample.pdf
Setting DPI
The default Dots Per Inch (DPI) is 72. To set a different DPI, use the -r option. For example, to set DPI as 150, use the pdftotext command in the following way −
pdftotext -r 150 sample.pdf
Setting End of Line (EOL)
The -eol option in pdftotext specifies the end-of-line (EOL) convention used in the output text file. Depending on the target operating system or user preference it determines how line breaks are represented in the extracted text.
pdftotext -eol unix sample.pdf
The above command produces a file with \n as line breaks. Other types are dos and mac.
Note that the default EOL style depends on the system where pdftotext is running. Specifying -eol ensures the desired format is used, regardless of the system default.
Generating a Tab Separated Values (TSV) File
To generate a TSV file, use the -tsv option −
pdftotext -tsv sample.pdf
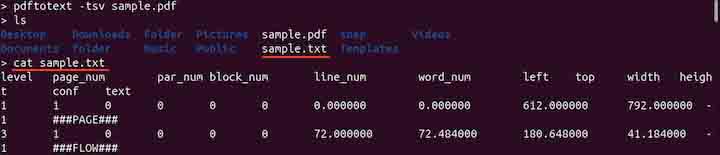
This format is particularly useful for structured data, such as tables, where each table cell is separated by a tab character (\t), making it easy to import into spreadsheet software like Excel or to process with data tools.
Displaying Help
To display help about the pdftotext command, use any option from -h, -help, --help, or -? −
pdftotext -?
Conclusion
The pdftotext command in Linux provides a handy way to convert PDF files into text files. Using various flags, specific pages can be extracted, the original layout preserved, areas cropped, and different text encodings applied, among other features. It is a versatile tool for converting PDF content into a text format that can be easily manipulated or analyzed.
