pdfimages Command in Linux
The pdfimages command on Linux extracts the images from a PDF file. It extracts images from a PDF file without altering their original format or quality. It is particularly useful for obtaining embedded images directly from PDFs.
The pdfimages extracts images from a PDF file and saves them in their original format as PPM, PGM, PBM, or JPEG files. It scans the specified pages of the PDF and outputs each image as a separate file named image-root-nnnn.xxx, where nnnn is the image number and xxx is the file type. The tool preserves the raw image data without applying transformations like rotation, cropping, or color adjustments.
Table of Contents
Here is a comprehensive guide to the options available with the pdfimages command −
Syntax of pdfimages Command
The syntax of the Linux pdfimages command is as follows −
pdfimages [options] [PDF-file] [image-root]
In the above syntax −
- [options] − To specify the various options to change the command's behavior.
- [PDF-file] − To specify the PDF file or file path from which images need to be extracted.
- [image-root] − The prefix for the output image files. Extracted images will be named <image-root>-0001.xxx, <image-root>-0002.xxx, and so on. Where .xxx is the image's original format, such as .jpg, or .ppm.
pdfimages Command Options
The options of the pdfimages command are listed below −
| Options | Description |
|---|---|
| -f <int> | The first page to convert |
| -l <int> | The last page to convert |
| -png | Change the default output format to PNG |
| -tiff | Change the default output format to TIFF |
| -j | Write JPEG images as JPEG files |
| -jp2 | Write JPEG2000 images as JP2 files |
| -jbig2 | Write JBIG2 images as JBIG2 files |
| -ccitt | Write CCITT images as CCITT files |
| -all | Equivalent to -png -tiff -j -jp2 -jbig2 -ccitt |
| -list | Print a list of images instead of saving |
| -opw <string> | Owner password (for encrypted files) |
| -upw <string> | User password (for encrypted files) |
| -p | Include page numbers in output file names |
| -q | Don't print any messages or errors |
| -v | Display copyright and version info |
| -h, -help, --help, ? | Display usage information |
Examples of pdfimages Command in Linux
This section demonstrates the usage of the pdfimages command in Linux with examples −
Extracting all Images from a PDF File
To extract all the images from a PDF file, use the following command −
pdfimages input.pdf image
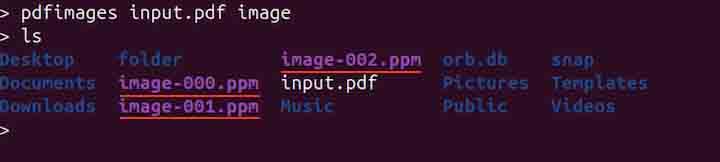
In the above command, the input.pdf is the PDF file from which images will be extracted, and the image is the prefix for the extracted image files. The files will be saved as image-0001.xxx, image-0002.xxx, etc., where .xxx is the original image format.
Listing Images in a PDF File
To list details of all the images in a PDF file, use the -list option −
pdfimages -list input.pdf

Extracting Images from Specific Pages
Use the -f and -l options to extract images from pages 1 to 3 of a PDF file.
pdfimages -f 1 -l 3 input.pdf image
Extracting Images from a PDF File and Saving them as PNG or TIFF
To extract images from a PDF file and save them as PDG, use the -png option −
pdfimages -png input.pdf image

Similarly, to save the extracted images in TIFF format, use the -tiff option −
pdfimages -tiff input.pdf image
Extracting Images from a PDF File and Saving them as JPEG Images Directly
The -j option in the pdfimages command ensures that images stored in DCT format (commonly used for JPEG compression) within a PDF are extracted and saved directly as JPEG files, without conversion or re-encoding.
pdfimages -j input.pdf image

If a PDF file contains a mix of JPEG and other image types, JPEG images will be saved as image-001.jpg, image-002.jpg, and so on. Non-JPEG images, such as PPM or PGM, will be saved with corresponding names like image-003.ppm, image-004.pgm, etc.
Extracting Images from a Password-Protected PDF Files
To extract images from a password-protected PDF file, use the -opw or -upw option with the pdfimages command. To specify the user password, use the -upw option −
pdfimages -upw userpassword input.pdf image
Note that using a user password the image extraction may still fail if permissions are strictly enforced.
To use the owner password, use the -opw option −
pdfimages -opw ownerpassword input.pdf image
This will bypass all the restrictions on a PDF file.
Including Page Numbers with the Image File Names
To include the PDF file page number from which the image is extracted, use the -p option −
pdfimages -p input.pdf image
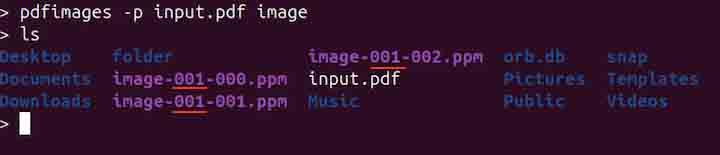
The output shows three images: image-001-000.ppm, image-001-001.ppm, and image-001-002.ppm. Here, 001 after the image indicates the page number, meaning all the extracted images are from the first page of the PDF file.
Suppressing Errors while Extracting Images from a PDF File
To suppress all the errors while extracting the images from a PDF file, use the -q option −
pdfimages -q input.pdf image
The -q enables the quiet mode. Note that it only suppresses the non-critical errors, critical errors such as file permission, still appear.
Displaying Help
To display help related to the pdfimages command, use any option from the -h, -help, --help, or ? −
pdfimages ?
Conclusion
The pdfimages command on Linux extracts images from PDF files without altering their original format or quality. It supports formats like PPM, PGM, PBM, JPEG, PNG, and TIFF, preserving raw image data and offering options to specify page ranges, output formats, passwords for encrypted PDFs, and quiet mode to suppress errors.
The tool also lists embedded image details, includes page numbers in filenames, and bypasses restrictions on password-protected files.
