pdftohtml Command in Linux
The pdftohtml command in Linux converts a PDF file to HTML, XML, and PNG images. It is part of the poppler-utils package, which provides various utilities for handling PDF files. This tool can generate either a simple HTML file with embedded images or a more detailed HTML representation that preserves the layout of the PDF.
Table of Contents
Here is a comprehensive guide to the options available with the pdftohtml command −
Syntax of pdftohtml Command
The syntax of the pdftohtml command is as follows −
pdftohtml [options] [PDF-file] [<html-file> <xml-file>]
In the above syntax −
- [options] − To customize the output
- [PDF-file] − The input PDF file that needs to be converted. Provide the full path or the filename if it is in the current directory.
- [<html-file> <xml-file>] − These are the output filenames. Note that pdftohtml auto-generates filenames based on the PDF unless explicitly specified.
pdftohtml Command Options
The options of the pdftohtml command are listed below −
| Options | Description |
|---|---|
| -f <int> | Specifies the first page to convert |
| -l <int> | Specifies the last page to convert |
| -q | Suppresses output messages and errors |
| -p | Replaces .pdf links with .html links |
| -c | Generates a complex document |
| -s | Generates a single document that includes all pages |
| -dataurls | Embeds images as data URLs in the HTML |
| -i | Ignores images during the conversion |
| -noframes | Generates HTML without frames |
| -stdout | Outputs the result to the standard output |
| -zoom <fp> | Zooms the PDF document (default is 1.5) |
| -xml | Generates XML output for post-processing |
| -noroundcoord | Disables coordinate rounding (XML output only) |
| -hidden | Includes hidden text in the output |
| -nomerge | Prevents merging of paragraphs |
| -enc <string> | Specifies the text encoding for the output |
| -fmt <string> | Defines the image file format (png or jpg) |
| -opw <string> | Specifies the owner password for encrypted files |
| -upw <string> | Specifies the user password for encrypted files |
| -nodrm | Overrides DRM restrictions in the document |
| -wbt <fp> | Sets the word break threshold (default is 10%) |
| -fontfullname | Outputs the full name of fonts used |
| -v | Displays copyright and version information |
| -h, -?, -help, --help | Displays usage information |
Examples of pdftohtml Command in Linux
This section demonstrates the usage of the pdftohtml command in Linux with examples −
Converting a PDF to HTML
To convert a PDF file to HTML, use the following command −
pdftohtml document.pdf
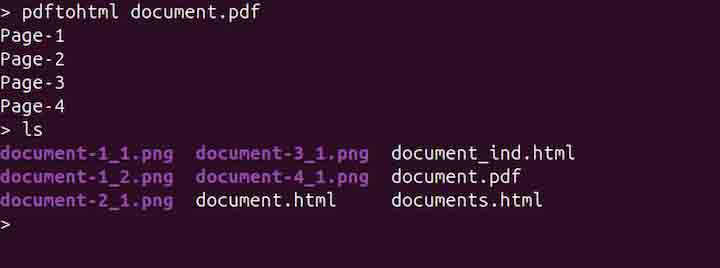
The command generates HTML files and images in the current working directory. To define the output image formats, use the -fmt option. By default, images are saved in PNG format, to save them as JPG, use the following command −
pdftohtml -fmt jpg document.pdf
To prevent the merging of paragraphs, use the -nomerge option −
pdftohtml -nomerge document.pdf
Converting a PDF to XML
To convert a PDF to XML, use the -xml option −
pdftohtml -xml document.pdf
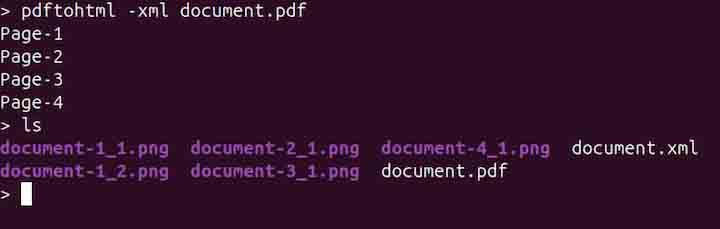
Converting Specific Pages of a PDF to HTML
To convert specific pages of a PDF file to HTML, use the -f and -l options. For example, to generate the HTML of a PDF document from pages 2 to 3, use the following command −
pdftohtml -f 2 -l 3 document.pdf
Converting a PDF to a Single Page HTML
By default, the pdftohtml command converts a PDF to HTML on multiple pages. To convert it into a single page, use the -s option −
pdftohtml -s document.pdf
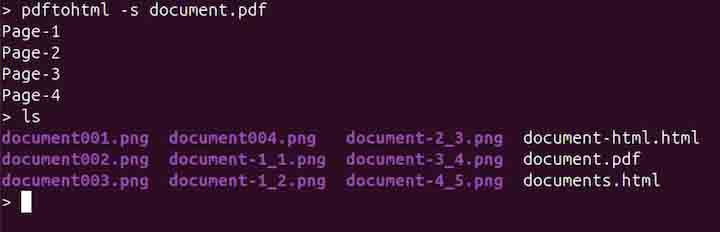
Converting a PDF to HTML with a Different Zoom-Level
By default, the pdftohtml command zooms the PDF document to 1.5. To change it, use -zoom option −
pdftohtml -zoom 2.0 document.pdf
The above command converts a PDF file into an HTML file with a zoom level of 200%. Similarly, to scale the content to 50%, use 0.5.
Converting a PDF to HTML with Encoded Images
By default, the pdftohtml command saves the images as separate files. Instead of saving images as separate files, to encode them directly within the HTML as base64 data strings use the -dataurls option.
pdftohtml -dataurls document.pdf
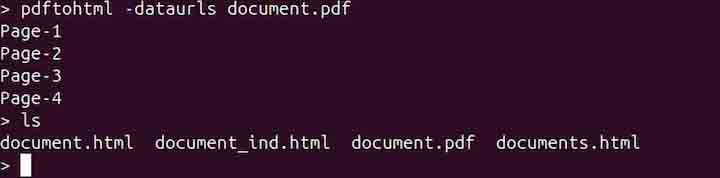
Converting a PDF to HTML without Images
To ignore the images while conversion, use the -i option −
pdftohtml -i document.pdf
Converting an Encrypted PDF to HTML
The PDF file may be locked through a user password or owner password. The use the user password, use the -upw option −
pdftohtml -upw user-password document.pdf
To use the owner's password, use the -owp option −
pdftohtml -opw owner-password document.pdf
Including the Hidden Text while Conversion
To include the hidden text of the PDF in the output, use the -hidden option −
pdftohtml -hidden document.pdf
Hidden text is text that exists within the PDF but is not visible to the user under normal viewing conditions. This text might include metadata, annotations, or layers of content that are hidden in the default PDF view.
Displaying Help
To display help about the pdftohtml command, use any option from -h, -help, --help or -? −
pdftohtml -?
Conclusion
The pdftohtml command in Linux is a versatile tool for converting PDF files into HTML, or XML. It provides various options to customize the output, such as defining page ranges, embedding images as data URLs, converting to a single-page HTML, or excluding images. Additionally, it can handle encrypted files and hidden text while offering features like zoom adjustment and encoding control.
In this tutorial, we explained the pdftohtml command, its syntax, options, and usage in Linux with examples.
