hexdump Command in Linux
hexdump is a robust command-line utility in Linux that converts the contents of a file into a readable format. It supports multiple formats, such as −
- Hexadecimal − Base-16 representation
- ASCII − Character representation
- Octal − Base-8 representation
- Decimal − Base-10 representation
Developers often deal with binary data, which is not easily readable. Converting this data into a format that humans can understand (like hexadecimal or ASCII) makes it easier to analyze and debug.
- The hexdump command-line utility is commonly used by professionals who need to inspect and analyze binary data, such as programmers and system administrators.
- hexdump is versatile and can be used in various scenarios, such as inspecting the contents of files stored on disk, reading and analyzing the structure of disk partitions or filesystems.
- In addition, you can also use this hexdump to analyze data captured from network traffic or serial communication and examine memory dumps' contents for debugging or forensic purposes.
- To use hexdump, you need to provide a file or standard input. The command will then convert the input data into the specified format.
- Other commands like xxd and od can also convert binary data into readable formats. These tools offer similar functionality and can be used as alternatives to hexdump.
- hexdump is typically included by default in most Linux distributions. On Ubuntu, it is part of the bsdmainutils
Table of Contents
Here is a comprehensive guide to the options available with the hexdump command −
- Syntax for the hexdump Command
- Options Available for the hexdump Command
- Examples of hexdum Command in Linux
Syntax for the hexdump Command
The following is the basic syntax for the hexdump command −
hexdump [OPTIONS] [FILE]
Options Available for the hexdump Command
The following is a list of options alongside their descriptions for hexdump or hd commands −
| Tag | Description |
|---|---|
| -b (One-byte octal display) | Displays the input offset (address) in hexadecimal format, followed by sixteen space-separated, three-column, zero-filled bytes of input data in octal per line. |
| -c (One-byte character display) | Displays the input offset in hexadecimal, followed by sixteen space-separated, three-column, space-filled characters of input data per line. |
| -C (Canonical hex+ASCII display) | Displays the input offset in hexadecimal, followed by sixteen space-separated, two-column hexadecimal bytes, and the same sixteen bytes in ASCII format enclosed in | characters. |
| -d (Two-byte decimal display) | Displays the input offset in hexadecimal, followed by eight space-separated, five-column, zero-filled, two-byte units of input data in unsigned decimal per line. |
| -e format_string | Specifies a format string to be used for displaying data. |
| -f format_file | Specifies a file that contains one or more newline-separated format strings. Empty lines and lines starting with a hash mark (#) are ignored. |
| -n length | Interprets only the specified number of bytes (length) of input. |
| -o (Two-byte octal display) | Displays the input offset in hexadecimal, followed by eight space-separated, six-column, zero-filled, two-byte quantities of input data in octal per line. |
| -s offset | Skips the specified number of bytes (offset) from the beginning of the input. The offset can be specified in decimal, hexadecimal (with 0x or 0X), or octal (with a leading 0). Appending b, k, or m to the offset interprets it as a multiple of 512, 1024, or 1048576, respectively. |
| -v | Causes hexdump to display all input data. Without this option, identical groups of output lines are replaced with a single asterisk (*). |
| -x (Two-byte hexadecimal display) | Displays the input offset in hexadecimal, followed by eight space-separated, four-column, zero-filled, two-byte quantities of input data in hexadecimal per line. |
Examples of hexdum Command in Linux
In this section, we'll explore various examples that should help you get started with using the hexdump command −
Basic Hex Dump
To display the contents of a file in a hexadecimal format, you can simply run the following command −
hexdump samplefile.txt
This command outputs the contents of samplefile.txt in hexadecimal format.
Where −
- The first column shows the offset in the file.
- The subsequent columns display the hexadecimal representation of the file's contents.

One-byte Octal Display
You can use the "-b" option with the hexdump command to display a file's contents in a one-byte octal format. This is useful for examining the raw data in a file byte by byte.
To achieve this, you can simply run the following command −
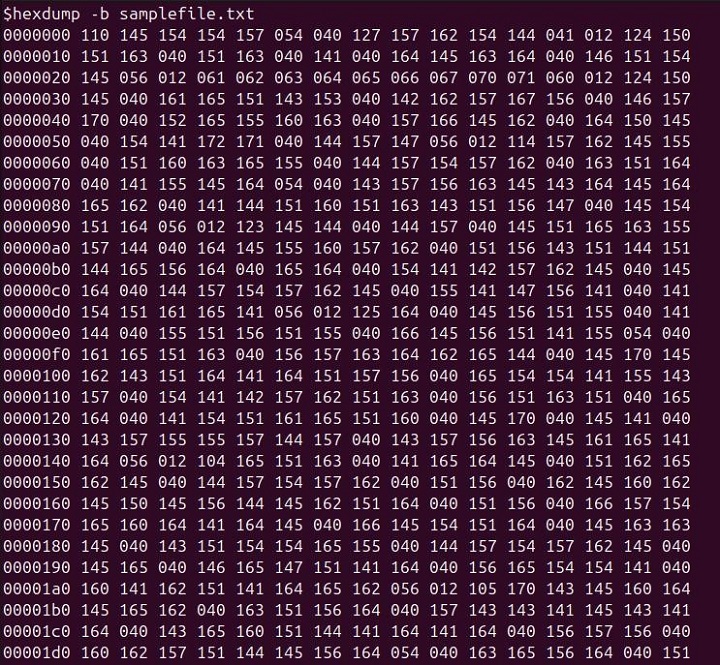
hexdump -b samplefile.txt
This command outputs each byte of samplefile.txt in octal format.
In this output −
- The first column shows the offset in the file.
- The subsequent columns display the octal representation of each byte in the file.
One-byte Character Display
You can use the hexdump command with the "-c" flag to display the contents of a file in a one-byte character format. This means each byte is shown as an ASCII character, which is useful for visualizing text data.
hexdump -c samplefile.txt
This command outputs each byte of samplefile.txt as an ASCII character.
In this output −
- The first column shows the offset in the file.
- The subsequent columns display the ASCII representation of each byte in the file.

Two-byte Decimal Display
To display the contents of a file in a two-byte decimal format, you can use the "-d" option with the hexdump command −
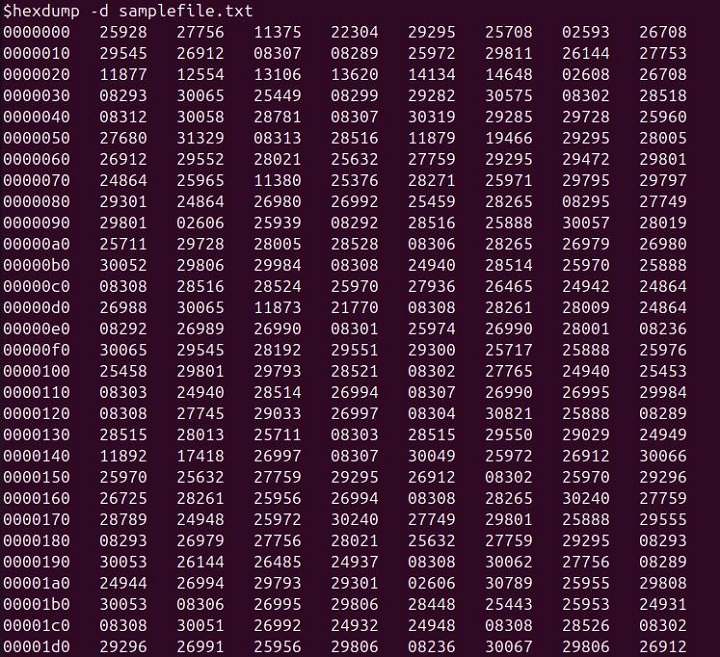
hexdump -d samplefile.txt
This is useful for examining data in a more human-readable numeric form. This command outputs each two-byte chunk of samplefile.txt in decimal format.
In this output −
- The first column shows the offset in the file.
- The subsequent columns display the decimal representation of each two-byte chunk in the file.
Limit Output Length
You can use the "-n" option with the hexdump command to limit the output to a specified number of bytes. This can be useful when you only need to inspect a small portion of a file.
hexdump -n 16 samplefile.txt
This command outputs the first 16 bytes of samplefile.txt.
In this output −
- The first column shows the offset in the file.
- The subsequent columns display the hexadecimal representation of the first 16 bytes.

Skip Bytes
To skip a specified number of bytes from the beginning of the file before starting the dump, you can simply use the "-s" option with the hexdump command −
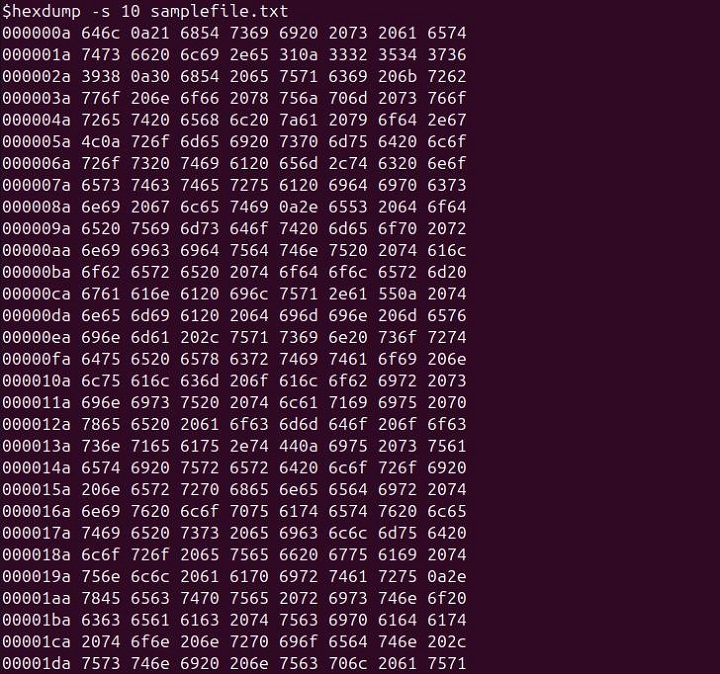
hexdump -s 10 samplefile.txt
This command skips the first 10 bytes of samplefile.txt and then displays the hexadecimal representation of the remaining content.
Two-byte Hexadecimal Display
To display the file content in two-byte hexadecimal format, you run the following command −
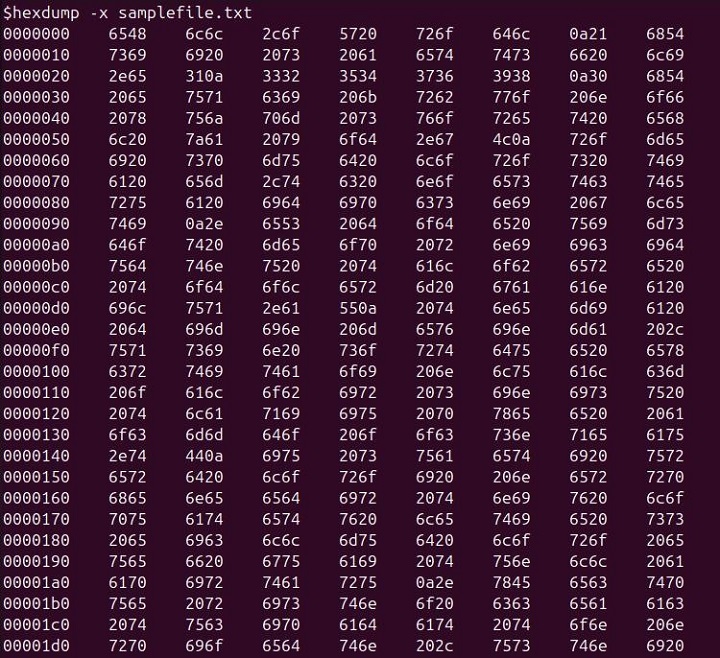
hexdump -x samplefile.txt
This command outputs the contents of samplefile.txt in hexadecimal, grouping the data into two-byte (16-bit) words.
Specify Format String
To specify a custom format string for the output, you can use the "-e" flag with the hexdump command −
hexdump -e '16/1 "%02x "' samplefile.txt
This command displays the contents of samplefile.txt in a specific format:
In this command −
- 16/1 means to display 16 bytes per line, with each byte being processed individually.
- "%02x" specifies the format for each byte: a two-digit hexadecimal number (%02x) followed by a space.

Conclusion
The hexdump command in Linux is an invaluable tool for anyone working with binary data, offering a straightforward way to visualize file contents in various formats such as hexadecimal, ASCII, and more.
Whether you're examining disk partitions, analyzing network traffic, or debugging memory dumps, mastering the hexdump command can significantly streamline your workflow.
