psed Command in Linux
The psed command in Linux is a stream editor similar to sed. It processes text line by line as it reads from input files or standard input if no files are provided. It applies a set of editing commands (a script) to each line and then writes the modified output to standard output.
Note that the psed command is no longer available as a standard tool; use sed or perl as alternatives for stream editing and inline text processing.
Table of Contents
Here is a comprehensive guide to the options available with the psed command −
- Alternatives of psed Command in Linux
- Syntax of psed Command
- psed Command Options
- Examples of psed Command in Linux
Note − The psed command is not commonly preinstalled but may still be found in specific distributions or legacy systems.
Alternatives of psed Command in Linux
Since psed is no longer commonly available, the following alternatives are recommended −
1. sed (Stream Editor) − A lightweight and widely available tool for text processing.
echo "Hello World" | sed 's/World/Linux/'

2. perl -pe (Perl One-Liner for Stream Editing) − Similar to psed, as it leverages Perl's regular expressions.
echo "Hello World" | perl -pe 's/World/Linux/'

Syntax of psed Command
The syntax of the Linux psed command is as follows −
psed [options] [file ...]
The [options] field in the above syntax is used to specify different options while the [file…] field is used to specify the input file that needs to be modified.
psed Command Options
The options of the psed command are listed below −
| Option | Description |
|---|---|
| -a | Delays opening a file specified with the w command until the first write operation. |
| -e script | Appends editing commands from the specified script. Multiple commands must be newline-separated. |
| -f script-file | Reads and appends editing commands from a script file. |
| -n | Suppresses automatic printing of lines after script execution. |
Examples of psed Command in Linux
In this section, examples of the psed command in Linux will be discussed, along with equivalent examples using sed and perl.
- Deleting Lines
- Replacing Words
- Changing File Contents
- Adding Prefix
Deleting Lines
To delete lines from a file, use the following command with psed −
psed '/error/d' file.txt
To perform the same functionality using sed, run the following command −
sed '/error/d' file.txt

And using perl command −
perl -ne 'print unless /error/' file.txt
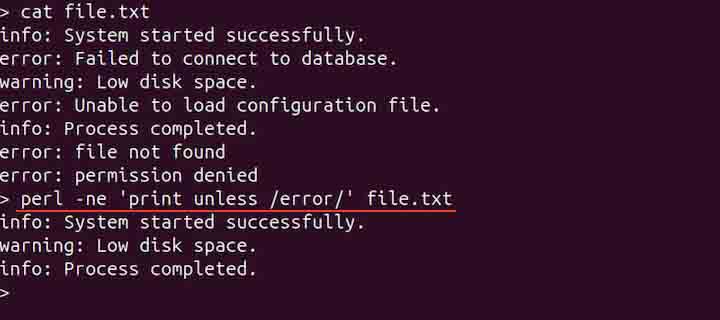
The above command removes the lines that contain errors and prints the remaining.
Replacing Words
To substitute words, use the psed command in the following command −
echo "ubuntu fedora linux" | psed 's/ubuntu/centos/; s/fedora/rhel/'
The sed command −
echo "ubuntu fedora linux" | sed -e 's/ubuntu/centos/' -e 's/fedora/rhel/'

Using the perl command −
echo "ubuntu fedora linux" | perl -pe 's/ubuntu/centos/; s/fedora/rhel/'

Changing File Contents
To replace the words in the entire file, use the following commands −
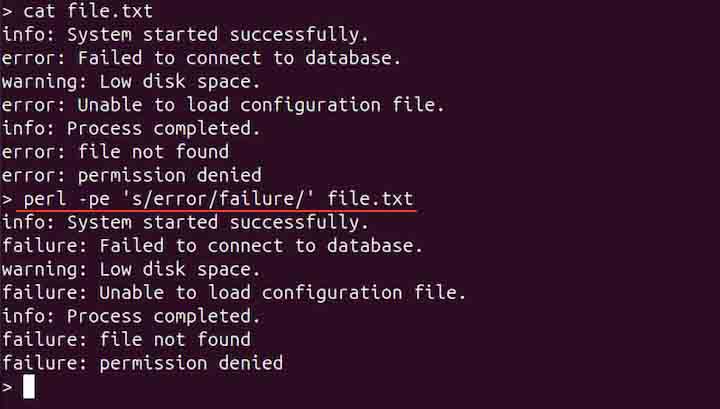
psed 's/error/failure/' file.txt
Use the sed command in the following way −
sed 's/error/failure/' file.txt

Perform the same operation, use the perl command in the following way −
perl -pe 's/error/failure/' file.txt
Adding Prefix
To add a prefix to each line of the file, use the psed command in the following manner −
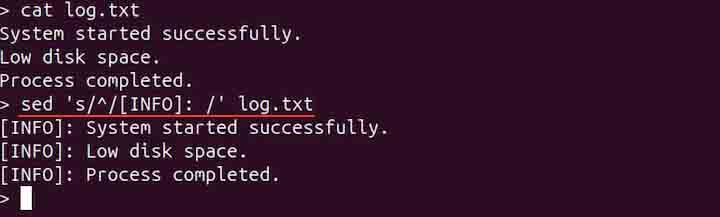
psed 's/^/[INFO]: /' log.txt
Using the sed command −
sed 's/^/[INFO]: /' log.txt
Using the perl command −
perl -pe 's/^/[INFO]: /' log.txt
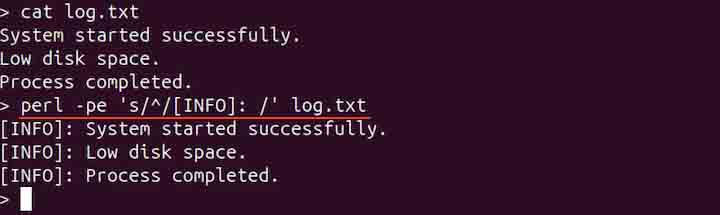
The above commands add [INFO] − as a prefix to each line in the file.
Conclusion
The psed command was a stream editor used for text processing but is no longer commonly available. Alternatives include sed, a lightweight and widely available tool, and perl -pe, which offers full Perl regex support. Both can perform similar text transformations, such as substitution, deletion, and in-place editing.
While sed is faster and available by default on Linux, perl -pe provides more powerful regex capabilities. Various examples in this guide illustrate how to replace psed with these alternatives for tasks like modifying file content and adding prefixes.
