rsync Command in Linux
rsync command is a Linux command line utility used for transferring and synchronizing files and directories. This command is known for its speed and flexibility and is widely used by system administrators, developers, and anyone needing efficient backup, remote synchronization, or mirroring of data. It minimizes data transfer by only copying the differences between source and destination files, making it a preferred tool for network and local file operations.
Table of Contents
Here is a comprehensive guide to the options available with the rsync command −
Syntax of rsync Command
The basic syntax for the Linux rsync command is as follows −
rsync [options] source destination
Where −
- [options] − These are optional flags that modify the behavior of the rsync command.
- source − The path to the directory or files you want to transfer or synchronize.
- destination − The path where the files will be copied to.
rsync Command Options
Here's a rundown of some notable options you can use with the command rsync −
| Option | Description |
|---|---|
| --archive, -a | Enables archive mode, which recursively copies files while preserving symbolic links, file permissions, user & group ownership, and timestamps. |
| --recursive, -r | Allows rsync to traverse directories and transfer their contents recursively. |
| --checksum, -c | Uses checksum comparison instead of mod-time and size to decide if the files need to be synchronized. |
| --progress | Displays the progress of the file transfer, providing a real-time view of the remaining data to be synced. |
| --compress, -z | Compresses file data during transfer to reduce transfer time, especially useful for slow network connections. |
| --delete | Deletes files in the destination directory that do not exist in the source directory, helping to maintain an exact mirror. |
| --links, -l | Ensures that symlinks in the source are copied as symlinks in the destination. |
| --exclude | Excludes files matching a specified pattern from being transferred. |
| --include | Includes files matching a specified pattern, even if they are excluded by other filter rules. |
| --backup, -b | Makes backups of existing files before transferring new versions. This option helps in preserving old copies. |
| --suffix=SUFFIX | Specifies a directory to store backup files, used in conjunction with --backup. |
| --times, -t | Preserves modification times. |
| --perms, -p | Preserves file permissions. |
Examples of rsync Command in Linux
Here are some practical examples to demonstrate how to use rsync with the options discussed −
- Using Archive Mode
- Synchronising with Checksum
- Compressing Data During Transfer
- Deleting Extraneous Files
- Copying Symlinks
- Excluding Specific Files
- Setting Backup Suffix
Using Archive Mode
If you need to perform a comprehensive backup, preserving all attributes like symbolic links, file permissions, and timestamps, you can use −
rsync -a source/ destination/
This command enables archive mode, ensuring that the entire directory structure and file attributes are preserved during the transfer.

Synchronizing with Checksum
To ensure accurate synchronization by comparing checksums instead of modification times and file sizes, you can use −
rsync -c source/ destination/
This command uses checksum comparison to determine if files need to be synchronized, providing a higher level of accuracy.

Compressing Data During Transfer
If you want to compress the file data during transfer to save bandwidth, especially useful for slow network connections, you can use −
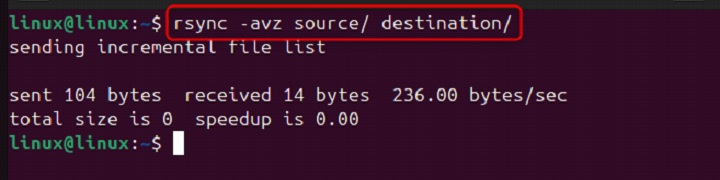
rsync -avz source/ destination/
This command compresses the file data during the transfer, reducing transfer time and bandwidth usage.
Deleting Extraneous Files
To maintain an exact mirror by deleting files in the destination directory that are not present in the source directory, you can use −
rsync -av --delete source/ destination/
This command deletes files in the destination that do not exist in the source, ensuring an exact mirror.

Copying Symlinks
When you need to ensure that symlinks in the source are copied as symlinks in the destination, you can use −
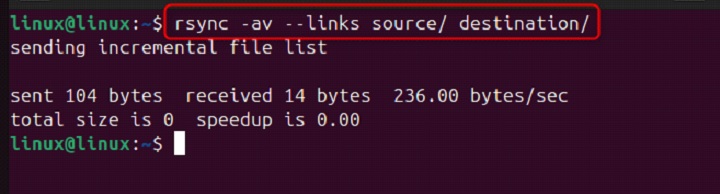
rsync -av --links source/ destination/
This command ensures that symbolic links in the source directory are preserved in the destination directory.
Excluding Specific Files
If you need to exclude files matching a specific pattern during the transfer, you can use −
rsync -av --exclude '*.tmp' source/ destination/
This command excludes files with the .tmp extension from being transferred, focusing only on the relevant files.

Setting Backup Suffix
If you want to specify a suffix for backup files, you can use −
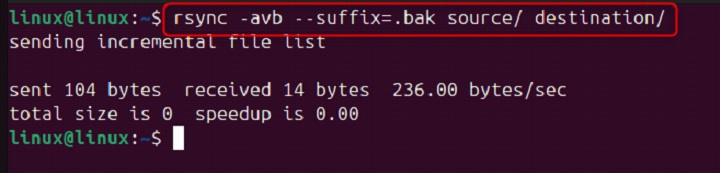
rsync -avb --suffix=.bak source/ destination/
This command backs up existing files with the .bak suffix before transferring new versions.
Conclusion
The rsync command stands as a quintessential tool for file synchronization and transfer in Linux environments. Whether you're looking to back up data, mirror directories, or synchronize files across remote systems, rsync offers an array of options to tailor the process to your specific needs. Its efficiency lies in transferring only the changed portions of files, conserving bandwidth and time.
By mastering the syntax and options of rsync, users can streamline their data management tasks, ensuring reliable and up-to-date backups.
