pcregrep Command in Linux
The pcregrep command in Linux searches files using Perl-compatible regular expressions (PCRE). It offers more advanced pattern-matching capabilities than standard grep. Note that the patterns follow Perl 5 regular expression syntax and are written without delimiters.
Table of Contents
Here is a comprehensive guide to the options available with the pcregrep command in Linux with examples −
- Installation pcregrep Command
- Syntax of pcregrep Command
- pcregrep Command Options
- Examples of pcregrep Command in Linux
Installation pcregrep Command
By default, the pcregrep command may not be available on Linux. To install it on Ubuntu, Raspberry Pi OS, Kali Linux, Debian, and other Debian-based distributions, use the following command −
sudo apt install pcregrep
To install it on Arch Linux, use −
sudo pacman -S pcregrep
To install it on CentOS, use the following command −
sudo yum install pcregrep
To install the pcregrep command on Fedora, use the following command −
sudo dnf install pcregrep
For verification of installation, check the version of pcregrep command −
pcregrep -V

Syntax of pcregrep Command
The syntax of the pcregrep command is as follows −
pcregrep [options] [pattern] [file…]
In the above syntax, the [options] field is used to specify the various options to change the command's behavior. The [pattern] field is used to specify the Perl 5 pattern and [file...] is used to specify one or more files.
pcregrep Command Options
The options of the pcregrep command are listed below −
| Flags | Option | Description |
|---|---|---|
| -- | Terminates the list of options (Useful for handling patterns and filenames starting with hyphens) | |
| -A number | --after-context=number | Outputs number lines of context after each matching line |
| -a | --text | Treats binary files as text, equivalent to --binary-files=text |
| -B number | --before-context=number | Outputs number lines of context before each matching line |
| --binary-files=word | Specifies processing for binary files: binary to process as binary, text to treat as text, or without-match to skip | |
| --buffer-size=number | Sets the memory buffer size for scanning files | |
| -C number | --context=number | Outputs number lines of context before and after each matching line |
| -c | --count | Outputs the count of matching lines instead of the lines themselves |
| --colour, --color | Specifies when to use colored output: never, always, or auto | |
| -D action | --devices=action | Specifies how to process non-regular files: read or skip |
| -d action | --directories=action | Specifies how to process directories: read, recurse, or skip |
| -e pattern | --regex=pattern | Defines a pattern to match, allowing multiple patterns |
| --exclude=pattern | Skips files with names matching the given pattern | |
| --exclude-from=filename | Uses patterns from the specified file to exclude files | |
| --exclude-dir=pattern | Skips directories with names matching the given pattern | |
| -F | --fixed-strings | Interprets patterns as fixed strings rather than regular expressions |
| -f filename | --file=filename | Reads patterns from a file to match against input lines |
| --file-list=filename | Reads file and directory names to scan from the specified file | |
| --file-offsets | Displays match offsets and lengths instead of the matching lines | |
| -H | --with-filename | Includes filenames in output when searching a single file |
| -h | --no-filename | Suppresses filenames in output when searching multiple files |
| --help | Outputs a help message with brief command option details and exits | |
| -I | --binary-files | Treat binary files as never matching |
| -i | --ignore-case | Ignore upper/lower case distinctions |
| --include | Process files matching the pattern, excluding those matching --exclude | |
| --include-from | Read include patterns from a file | |
| --include-dir | Process directories matching the pattern, excluding those matching --exclude-dir | |
| -L | --files-without-match | List files without matching lines |
| -l | --files-with-matches | List files with matching lines |
| --label | Specify a name for standard input when outputting filenames | |
| --line-buffered | Process input line by line, flushing output after each write | |
| --line-offsets | Show match as line number, offset, and length | |
| --locale | Set a specific locale for pattern matching | |
| --match-limit | Limit memory usage for certain patterns with many matching possibilities | |
| -M | --multiline | Allow patterns to match across multiple lines |
| -N | --newline | Specify line ending type to handle different conventions |
| -n | --line-number | Precede each output line by its line number |
| --no-jit | Disable Just-In-Time compilation for matching | |
| -o | --only-matching | Show only the part of the line that matched |
| -onumber | --only-matching=number | Show only the part of the line that matched specific capturing group |
| --om-separator | Set separator for multiple occurrences of -o | |
| -q | --quiet | Suppress output, only show error messages |
| -r | --recursive | Recursively scan directories for files |
| --recursion-limit | Limit recursion depth for matching | |
| -s | --no-messages | Suppress error messages for unreadable files |
| -u | --utf-8 | Enable UTF-8 mode for pattern matching |
| -V | --version | Show version information and exit |
| -v | --invert-match | Invert match to find non-matching lines |
Examples of pcregrep Command in Linux
This section demonstrates the usage of the pcregrep command in Linux with examples −
Searching for a Pattern in a File
To search for lines containing a specific pattern, use the pcregrep command with the pattern and file name. For example, to search lines with INFO in them, use the following command −
pcregrep 'INFO' log.txt

The above command displays the lines in the log.txt file exactly containing the INFO pattern in them as shown in the output image.
Searching for a Pattern in a File Ignoring the Case Sensitivity
To ignore the case, use the -i or --ignore-case options −
pcregrep -i 'info' log.txt

The above command displays the lines in the log.txt file containing the info pattern, whether in small or capital cases, as shown in the output image.
Searching with Regular Expression
To match lines where a number follows the pattern, use the pcregrep command with the regex −
pcregrep -i 'error\d+' log.txt

In the above command, error\d+ is a Perl-compatible regular expression (PCRE). It matches the literal string error followed by one or more digits, where \d matches a digit (0-9) and + ensures one or more digits.
Searching for Lines not Matching the Specified Pattern
To search the lines not matching the mentioned pattern, use the -v or --invert-match option −
pcregrep -v 'ERROR' log.txt
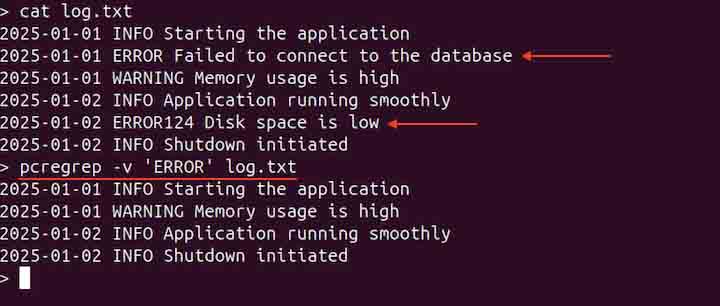
The output does not contain lines with the ERROR in them.
Highlighting the Pattern in the Output
To highlight the pattern in the output, use the --color option with auto −
pcregrep --color=auto -i 'error' log.txt

Matching Across Multiple Lines
To search for a multiline pattern, such as an opening and closing HTML tag, use the -M or --multiline option −
pcregrep -M '(?s)<div>.*?</div>' file.html
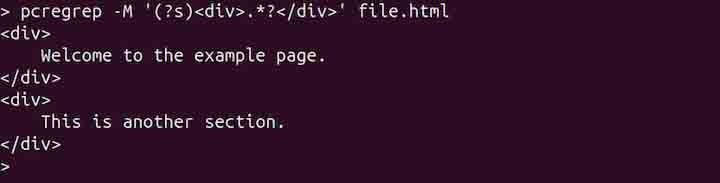
Displaying only Matching Parts instead of Lines
To display only the matching parts of the lines instead of complete lines, use the -o or --onlymatching option −
pcregrep -o '\d{3}-\d{2}-\d{4}' file.txt
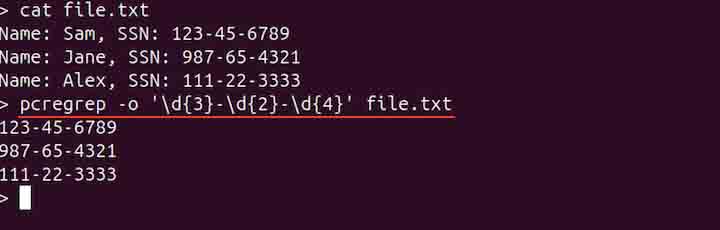
Displaying the Count of Matching Lines
To display the count of matching lines instead of lines, use the -c or --count option −
pcregrep -c 'INFO' log.txt

Searching for Multiple Patterns
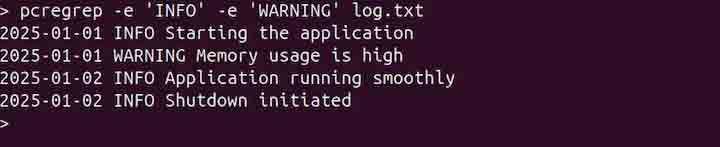
To search for multiple patterns, use the -e or --regex option with the pcregrep command −
pcregrep -e 'INFO' -e 'WARNING' log.txt
Displaying Usage Help
To display the usage help about pcregrep tool, use the -h or --help option −
pcregrep -h
Conclusion
The pcregrep command in Linux is used for searching files using Perl-compatible regular expressions (PCRE), offering advanced pattern-matching features beyond standard grep. It supports options for context, case sensitivity, multiline patterns, and more, making it versatile for complex text-processing tasks.
