- Graph Theory - Home
- Graph Theory - Introduction
- Graph Theory - History
- Graph Theory - Fundamentals
- Graph Theory - Applications
- Types of Graphs
- Graph Theory - Types of Graphs
- Graph Theory - Simple Graphs
- Graph Theory - Multi-graphs
- Graph Theory - Directed Graphs
- Graph Theory - Weighted Graphs
- Graph Theory - Bipartite Graphs
- Graph Theory - Complete Graphs
- Graph Theory - Subgraphs
- Graph Theory - Trees
- Graph Theory - Forests
- Graph Theory - Planar Graphs
- Graph Theory - Hypergraphs
- Graph Theory - Infinite Graphs
- Graph Theory - Random Graphs
- Graph Representation
- Graph Theory - Graph Representation
- Graph Theory - Adjacency Matrix
- Graph Theory - Adjacency List
- Graph Theory - Incidence Matrix
- Graph Theory - Edge List
- Graph Theory - Compact Representation
- Graph Theory - Incidence Structure
- Graph Theory - Matrix-Tree Theorem
- Graph Properties
- Graph Theory - Basic Properties
- Graph Theory - Coverings
- Graph Theory - Matchings
- Graph Theory - Independent Sets
- Graph Theory - Traversability
- Graph Theory Connectivity
- Graph Theory - Connectivity
- Graph Theory - Vertex Connectivity
- Graph Theory - Edge Connectivity
- Graph Theory - k-Connected Graphs
- Graph Theory - 2-Vertex-Connected Graphs
- Graph Theory - 2-Edge-Connected Graphs
- Graph Theory - Strongly Connected Graphs
- Graph Theory - Weakly Connected Graphs
- Graph Theory - Connectivity in Planar Graphs
- Graph Theory - Connectivity in Dynamic Graphs
- Special Graphs
- Graph Theory - Regular Graphs
- Graph Theory - Complete Bipartite Graphs
- Graph Theory - Chordal Graphs
- Graph Theory - Line Graphs
- Graph Theory - Complement Graphs
- Graph Theory - Graph Products
- Graph Theory - Petersen Graph
- Graph Theory - Cayley Graphs
- Graph Theory - De Bruijn Graphs
- Graph Algorithms
- Graph Theory - Graph Algorithms
- Graph Theory - Breadth-First Search
- Graph Theory - Depth-First Search (DFS)
- Graph Theory - Dijkstra's Algorithm
- Graph Theory - Bellman-Ford Algorithm
- Graph Theory - Floyd-Warshall Algorithm
- Graph Theory - Johnson's Algorithm
- Graph Theory - A* Search Algorithm
- Graph Theory - Kruskal's Algorithm
- Graph Theory - Prim's Algorithm
- Graph Theory - Borůvka's Algorithm
- Graph Theory - Ford-Fulkerson Algorithm
- Graph Theory - Edmonds-Karp Algorithm
- Graph Theory - Push-Relabel Algorithm
- Graph Theory - Dinic's Algorithm
- Graph Theory - Hopcroft-Karp Algorithm
- Graph Theory - Tarjan's Algorithm
- Graph Theory - Kosaraju's Algorithm
- Graph Theory - Karger's Algorithm
- Graph Coloring
- Graph Theory - Coloring
- Graph Theory - Edge Coloring
- Graph Theory - Total Coloring
- Graph Theory - Greedy Coloring
- Graph Theory - Four Color Theorem
- Graph Theory - Coloring Bipartite Graphs
- Graph Theory - List Coloring
- Advanced Topics of Graph Theory
- Graph Theory - Chromatic Number
- Graph Theory - Chromatic Polynomial
- Graph Theory - Graph Labeling
- Graph Theory - Planarity & Kuratowski's Theorem
- Graph Theory - Planarity Testing Algorithms
- Graph Theory - Graph Embedding
- Graph Theory - Graph Minors
- Graph Theory - Isomorphism
- Spectral Graph Theory
- Graph Theory - Graph Laplacians
- Graph Theory - Cheeger's Inequality
- Graph Theory - Graph Clustering
- Graph Theory - Graph Partitioning
- Graph Theory - Tree Decomposition
- Graph Theory - Treewidth
- Graph Theory - Branchwidth
- Graph Theory - Graph Drawings
- Graph Theory - Force-Directed Methods
- Graph Theory - Layered Graph Drawing
- Graph Theory - Orthogonal Graph Drawing
- Graph Theory - Examples
- Computational Complexity of Graph
- Graph Theory - Time Complexity
- Graph Theory - Space Complexity
- Graph Theory - NP-Complete Problems
- Graph Theory - Approximation Algorithms
- Graph Theory - Parallel & Distributed Algorithms
- Graph Theory - Algorithm Optimization
- Graphs in Computer Science
- Graph Theory - Data Structures for Graphs
- Graph Theory - Graph Implementations
- Graph Theory - Graph Databases
- Graph Theory - Query Languages
- Graph Algorithms in Machine Learning
- Graph Neural Networks
- Graph Theory - Link Prediction
- Graph-Based Clustering
- Graph Theory - PageRank Algorithm
- Graph Theory - HITS Algorithm
- Graph Theory - Social Network Analysis
- Graph Theory - Centrality Measures
- Graph Theory - Community Detection
- Graph Theory - Influence Maximization
- Graph Theory - Graph Compression
- Graph Theory Real-World Applications
- Graph Theory - Network Routing
- Graph Theory - Traffic Flow
- Graph Theory - Web Crawling Data Structures
- Graph Theory - Computer Vision
- Graph Theory - Recommendation Systems
- Graph Theory - Biological Networks
- Graph Theory - Social Networks
- Graph Theory - Smart Grids
- Graph Theory - Telecommunications
- Graph Theory - Knowledge Graphs
- Graph Theory - Game Theory
- Graph Theory - Urban Planning
- Graph Theory Useful Resources
- Graph Theory - Quick Guide
- Graph Theory - Useful Resources
- Graph Theory - Discussion
Graph Theory - Forests
Forests in Graph Theory
A Forest is a collection of one or more disjoint trees. In graph theory, a forest is a set of trees that do not have any edges connecting them. Each tree within the forest is a separate, connected, acyclic graph.
A forest is essentially a group of trees that share a common property of being acyclic and connected, but they are not necessarily connected to each other.
Key characteristics of a Forest are −
- Disjoint Trees: Each tree in a forest is separate from the others; there are no edges connecting vertices in different trees.
- Acyclic: Like trees, each tree in a forest does not contain any cycles, meaning there is no closed loop of edges.
- Collection of Trees: A forest can have one or more trees. A single tree can be considered a forest by itself.
Forests are important in graph theory because they provide a natural generalization of trees and are used in algorithms and data structures where maintaining multiple disjoint sets is necessary. Examples include disjoint set data structures and various algorithms in graph theory.
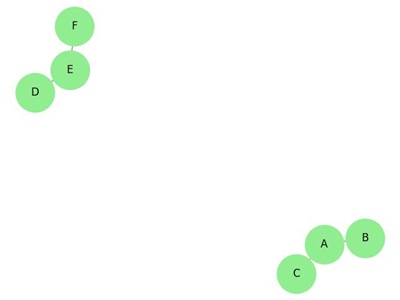
Properties of Forests
Forests have several important properties that distinguish them from other types of graphs. These properties are important for understanding their structure and behavior in graph-related problems −
Disjoint Trees
A forest is a collection of disjoint trees. This means that the vertices of each tree in the forest do not share any common vertices or edges with other trees in the forest.
Acyclicity
Just like trees, a forest is acyclic, meaning it contains no cycles. However, unlike trees, a forest can have more than one disconnected component, each of which is a tree.
Connectivity of Components
Each component of a forest is a connected tree. A tree is defined as a connected graph with no cycles, and since forests are made up of trees, each connected component of a forest will also have no cycles.
Number of Edges
If a forest consists of k disjoint trees and has a total of n vertices, then the forest will have n - k edges. This is because each tree with m vertices has m - 1 edges, and when you sum up the edges across all trees, the total number of edges will be the number of vertices minus the number of trees.
Spanning Trees of Graphs
In the context of connected graphs, a spanning tree is a tree that includes all the vertices of the graph. A forest can be viewed as a collection of spanning trees for each connected component of a graph. Thus, a forest can be a natural representation of a disconnected graph's spanning tree decomposition.
Forest as a Subgraph
A forest can be considered as a subgraph of a graph, where the subgraph consists of trees formed by a subset of the vertices and edges of the original graph. This is especially useful in scenarios where only certain subgraphs of a graph need to be analyzed.
Forest and Degree of Vertices
In a forest, the degree of a vertex is the number of edges incident to it within a tree in the forest. The sum of the degrees of all vertices in a forest is equal to twice the number of edges in the forest, as each edge is counted twiceonce at each endpoint.
Traversal in Forests
Traversing a forest involves traversing each tree individually. Standard tree traversal techniques, such as depth-first search (DFS) or breadth-first search (BFS), can be applied to each tree in the forest.
Types of Forests
There are various types of forests that differ in their structure, properties, and applications. Some of the most common types are −
Spanning Forest
A Spanning Forest is a collection of spanning trees for a graph, but unlike a spanning tree, it applies to disconnected graphs. In other words, a spanning forest is a set of trees such that each tree is a spanning tree for a connected component of the graph.
It includes all the vertices of the graph, but only the edges that connect vertices within each connected component, ensuring no cycles are formed within each tree.

Minimal Spanning Forest
A Minimal Spanning Forest is a collection of spanning trees that connects all the vertices of a disconnected graph with the minimum possible total edge weight, where each tree in the forest spans a connected component of the graph.
It is an extension of the concept of a Minimum Spanning Tree (MST) to graphs that are not fully connected.
Key characteristics of a Minimal Spanning Forest are −
- Minimum Edge Weights: The spanning trees in a minimal spanning forest are chosen in such a way that the total sum of the edge weights is minimized for each connected component of the graph.
- Multiple Trees: Since the graph is disconnected, the minimal spanning forest consists of one minimum spanning tree for each connected component of the graph.
- No Cycles: Each tree in the forest is a spanning tree, meaning there are no cycles within any of the trees.
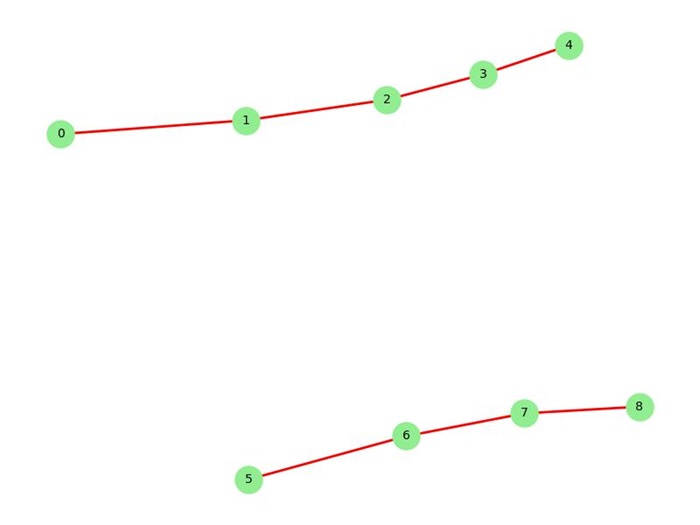
Disjoint Set Forest
A Disjoint Set Forest is used to represent a collection of disjoint (non-overlapping) sets and is primarily used to manage and merge these sets.
This data structure supports two main operations: Find, which determines the set a particular element belongs to, and Union, which merges two sets into one. Disjoint Set Forests are implemented using a forest of trees where each tree represents a set, and each node points to its parent, with the root node being the representative of the set.
Key characteristics of a Disjoint Set Forest include:
- Union by Rank: This optimization ensures that the smaller tree is always attached under the root of the larger tree, keeping the overall tree shallow and improving efficiency.
- Path Compression: This optimization flattens the structure of the tree whenever Find is called, by making nodes point directly to the root, further speeding up future operations.
- Efficient Operations: Both Find and Union operations are very efficient, nearly constant time, effectively O((n)), where is the inverse Ackermann function, which grows very slowly.
Forest with Balanced Trees
A Forest with Balanced Trees is a collection of balanced trees where each tree in the forest maintains a balanced structure, ensuring that the height of the tree remains logarithmic relative to the number of nodes.
Balanced trees are designed to provide operations such as insertion, deletion, and lookup by maintaining a balanced height, which prevents the tree from becoming skewed and degrading performance.
Key characteristics of a Forest with Balanced Trees are −
- Multiple Balanced Trees: The forest consists of multiple balanced trees, each representing a separate, connected, acyclic subgraph.
- Efficient Operations: Operations such as insertion, deletion, and lookup are performed efficiently due to the balanced nature of the trees.
Random Forest
In machine learning, a random forest refers to an ensemble learning method that uses multiple decision trees to improve the accuracy and performance of classification or regression tasks.
A random forest can be thought of as a collection of decision trees, where each tree is built using a random subset of the data, and the final prediction is based on the majority vote or averaging of the predictions from all the trees in the forest.

Applications of Forests
Forests are used in various applications in graph theory, computer science, machine learning, and other fields. Here are some key applications −
Graph Partitioning
Forests can be used to partition a graph into smaller subgraphs or components. Each component can be analyzed independently as a tree. This is especially useful in problems involving large, disconnected graphs that need to be broken down into manageable subgraphs.
Minimum Spanning Tree Algorithms
Forests play an essential role in algorithms that find the minimum spanning tree of a graph. Algorithms like Kruskal's algorithm and Prim's algorithm use the concept of a spanning forest to find the minimal spanning tree by connecting the vertices with the least total edge weight.
Cycle Detection in Graphs
In graph theory, detecting cycles is a fundamental problem. A forest is useful in cycle detection algorithms. If the graph is a forest, then it is guaranteed to contain no cycles. Algorithms that use union-find or depth-first search (DFS) can use the concept of forests to detect cycles in a graph.
Network Design and Analysis
Forests are used in network design and analysis, where the goal is to find the most efficient ways to connect nodes. For example, a minimum spanning forest can be used to design the least-cost network connection for a set of locations or nodes in a disconnected network.
Hierarchical Data Representation
Forests are used to represent hierarchical data, where each tree in the forest represents a different hierarchy or structure. This can be useful in representing organizational structures, file systems, or any scenario where data is naturally divided into disconnected groups.
Machine Learning: Random Forests
Random forests, as mentioned earlier, are an ensemble learning method that constructs multiple decision trees. Random forests are widely used in machine learning for classification and regression tasks. The technique combines the predictions from multiple trees to produce a more accurate and stable result compared to a single decision tree.
Data Clustering
Forests can be used in clustering algorithms, where each tree represents a cluster of similar data points. The structure of the forest helps to visualize and analyze the relationships between different clusters, and various algorithms rely on this concept to partition data efficiently.
Tree Traversals in Forests
When traversing a forest, each tree is visited individually, using standard tree traversal methods. Common traversal techniques are −
Depth-First Search (DFS)
DFS is a tree traversal method where the graph is explored as deeply as possible along each branch before backtracking. For forests, DFS can be applied to each tree, starting from the root of each tree.
Breadth-First Search (BFS)
BFS explores a graph level by level, visiting all the vertices at the present depth before moving on to the vertices at the next level. For forests, BFS can be applied to each tree to traverse its vertices in a level-order manner.
Algorithms on Forests
There are several major algorithms that involve forests in their operation. These algorithms often deal with problems like minimum spanning trees, cycle detection, or graph connectivity −
Kruskal's Algorithm
Kruskal's algorithm is an algorithm used to find the minimum spanning tree of a graph. It uses a forest to represent the subgraphs and iterates through the edges of the graph, merging trees in the forest until the entire graph is connected.
Prim's Algorithm
Prim's algorithm is another algorithm used to find the minimum spanning tree. Unlike Kruskal's algorithm, which starts with a forest, Prim's algorithm starts with a single vertex and grows the spanning tree by adding edges one at a time.
Union-Find Algorithm
The union-find algorithm is used for cycle detection and graph connectivity. It uses a disjoint-set forest data structure to merge sets of vertices and find whether two vertices are in the same component.
