- Automata Theory - Applications
- Automata Terminology
- Basics of String in Automata
- Set Theory for Automata
- Finite Sets and Infinite Sets
- Algebraic Operations on Sets
- Relations Sets in Automata Theory
- Graph and Tree in Automata Theory
- Transition Table in Automata
- What is Queue Automata?
- Compound Finite Automata
- Complementation Process in DFA
- Closure Properties in Automata
- Concatenation Process in DFA
- Language and Grammars
- Language and Grammar
- Grammars in Theory of Computation
- Language Generated by a Grammar
- Chomsky Classification of Grammars
- Context-Sensitive Languages
- Finite Automata
- What is Finite Automata?
- Finite Automata Types
- Applications of Finite Automata
- Limitations of Finite Automata
- Two-way Deterministic Finite Automata
- Deterministic Finite Automaton (DFA)
- Non-deterministic Finite Automaton (NFA)
- NDFA to DFA Conversion
- Equivalence of NFA and DFA
- Dead State in Finite Automata
- Minimization of DFA
- Automata Moore Machine
- Automata Mealy Machine
- Moore vs Mealy Machines
- Moore to Mealy Machine
- Mealy to Moore Machine
- Myhill–Nerode Theorem
- Mealy Machine for 1’s Complement
- Finite Automata Exercises
- Complement of DFA
- Regular Expressions
- Regular Expression in Automata
- Regular Expression Identities
- Applications of Regular Expression
- Regular Expressions vs Regular Grammar
- Kleene Closure in Automata
- Arden’s Theorem in Automata
- Convert Regular Expression to Finite Automata
- Conversion of Regular Expression to DFA
- Equivalence of Two Finite Automata
- Equivalence of Two Regular Expressions
- Convert Regular Expression to Regular Grammar
- Convert Regular Grammar to Finite Automata
- Pumping Lemma in Theory of Computation
- Pumping Lemma for Regular Grammar
- Pumping Lemma for Regular Expression
- Pumping Lemma for Regular Languages
- Applications of Pumping Lemma
- Closure Properties of Regular Set
- Closure Properties of Regular Language
- Decision Problems for Regular Languages
- Decision Problems for Automata and Grammars
- Conversion of Epsilon-NFA to DFA
- Regular Sets in Theory of Computation
- Context-Free Grammars
- Context-Free Grammars (CFG)
- Derivation Tree
- Parse Tree
- Ambiguity in Context-Free Grammar
- CFG vs Regular Grammar
- Applications of Context-Free Grammar
- Left Recursion and Left Factoring
- Closure Properties of Context Free Languages
- Simplifying Context Free Grammars
- Removal of Useless Symbols in CFG
- Removal Unit Production in CFG
- Removal of Null Productions in CFG
- Linear Grammar
- Chomsky Normal Form (CNF)
- Greibach Normal Form (GNF)
- Pumping Lemma for Context-Free Grammars
- Decision Problems of CFG
- Pushdown Automata
- Pushdown Automata (PDA)
- Pushdown Automata Acceptance
- Deterministic Pushdown Automata
- Non-deterministic Pushdown Automata
- Construction of PDA from CFG
- CFG Equivalent to PDA Conversion
- Pushdown Automata Graphical Notation
- Pushdown Automata and Parsing
- Two-stack Pushdown Automata
- Turing Machines
- Basics of Turing Machine (TM)
- Representation of Turing Machine
- Examples of Turing Machine
- Turing Machine Accepted Languages
- Variations of Turing Machine
- Multi-tape Turing Machine
- Multi-head Turing Machine
- Multitrack Turing Machine
- Non-Deterministic Turing Machine
- Semi-Infinite Tape Turing Machine
- K-dimensional Turing Machine
- Enumerator Turing Machine
- Universal Turing Machine
- Restricted Turing Machine
- Convert Regular Expression to Turing Machine
- Two-stack PDA and Turing Machine
- Turing Machine as Integer Function
- Post–Turing Machine
- Turing Machine for Addition
- Turing Machine for Copying Data
- Turing Machine as Comparator
- Turing Machine for Multiplication
- Turing Machine for Subtraction
- Modifications to Standard Turing Machine
- Linear-Bounded Automata (LBA)
- Church's Thesis for Turing Machine
- Recursively Enumerable Language
- Computability & Undecidability
- Turing Language Decidability
- Undecidable Languages
- Turing Machine and Grammar
- Kuroda Normal Form
- Converting Grammar to Kuroda Normal Form
- Decidability
- Undecidability
- Reducibility
- Halting Problem
- Turing Machine Halting Problem
- Rice's Theorem in Theory of Computation
- Post’s Correspondence Problem (PCP)
- Types of Functions
- Recursive Functions
- Injective Functions
- Surjective Function
- Bijective Function
- Partial Recursive Function
- Total Recursive Function
- Primitive Recursive Function
- μ Recursive Function
- Ackermann’s Function
- Russell’s Paradox
- Gödel Numbering
- Recursive Enumerations
- Kleene's Theorem
- Kleene's Recursion Theorem
- Advanced Concepts
- Matrix Grammars
- Probabilistic Finite Automata
- Cellular Automata
- Reduction of CFG
- Reduction Theorem
- Regular expression to ∈-NFA
- Quotient Operation
- Parikh’s Theorem
- Ladner’s Theorem
Two-stack Pushdown Automata
So far, in this tutorial, we have come across context-free grammars (CFG) and pushdown automata (PDA) to accept the CFG. But PDA or CFG have certain limitations; they cannot handle any type of language. For that reason, we jump to more advanced machines.
A little complex and advanced machine than pushdown automata is two-stack pushdown automata. In this chapter, we will have a look at two-stack pushdown automata with examples for a better understanding.
Why Do We Need Complex Machines over One-stack Pushdown Automata
We are very much familiar with this concept.
- Finite automata can recognize regular languages. An example is $\mathrm{\{a^{n}\:|\: n \: \geq \:0\}}$
- Pushdown automata (PDA) can recognize context-free languages. An example $\mathrm{\{a^{n}b^{n}\:|\: n \: \geq \:0\}}$.
- But what about more complex languages like $\mathrm{\{a^{n}b^{n}c^{n}\:|\: n \: \geq \:0\}?}$ Our regular PDA gets stuck here.
This is where our two-stack PDA comes to the consideration.
What is a Two-stack Pushdown Automata?
A two-stack PDA is like a more powerful version of PDA. The properties are written below −
- It has not one, but two stacks for storage.
- It can be deterministic, meaning it always knows what to do next.
- It can recognize all context-free languages, whether they're deterministic or not.
- It can even handle some context-sensitive languages, like $\mathrm{\{a^{n}b^{n}c^{n}\:|\: n \: \geq \:0\}}$
Components of Two-stack Pushdown Automata
A two-stack PDA is defined by a 9-tuple: M = (Q, Σ, Γ, Γ', δ, q0, z1, z2, F)
- Q − All the states the PDA can be in
- Σ − The input alphabet (symbols it can read)
- Γ − The alphabet for the first stack
- Γ' − The alphabet for the second stack
- δ − Rules for moving between states and using the stacks
- q0 − The starting state
- z1 − The bottom symbol for the first stack
- z2 − The bottom symbol for the second stack
- F − The final or accepting states
How Does a Two-stack Pushdown Automata Work?
The transition function δ is the main thing in automata. Here for two-stack PDA as well. It looks like this −
$$\mathrm{Q\:\times\:(\Sigma\:\cup\:\{\lambda\})\:\times\:\Gamma\:\times\:\Gamma'\:\rightarrow\:(Q,\:\Gamma,\:\Gamma')}$$
This indicates −
- It considers the current state, the input symbol (or for no input), and the top symbols of both stacks.
- Based on these, it decides the next state and what to do with both stacks.
Let us see examples for a better understanding −
Example: Recognizing $\mathrm{\{a^{n}b^{n}c^{n}\:|\: n \: \geq \:0\}}$
Let's see how a two-stack PDA can handle the $\mathrm{\{a^{n}b^{n}c^{n}\:|\: n \: \geq \:0\}}$. This language has equal numbers of a's, b's, and c's in that order.
Strategy
Here's how we'll use our two stacks −
- While reading 'a', we'll push 'X' into stack 1.
- While reading 'b', we'll push 'Y' into stack 2.
- While reading 'c', we'll pop 'X' from stack 1 and 'Y' from stack 2.
- If both stacks are empty at the end, we accept the string.
Transition Functions
$$\mathrm{\delta(q0, \: \lambda, \: z1, \: z2) \: \rightarrow \: (qf, \: z1, \: z2)}$$
$$\mathrm{\delta(q0, \: a, \: z1, \: z2) \: \rightarrow \: (q0, \: Xz1, \: z2)}$$
$$\mathrm{\delta(q0, \: a, \: X, \: z2) \: \rightarrow \: (q0, \: XX, \: z2)}$$
$$\mathrm{\delta(q0, \: b, \: X, \: z2) \: \rightarrow \: (q0, \: X, \: Yz2)}$$
$$\mathrm{\delta(q0, \: b, \: X, \: Y) \: \rightarrow \: (q0, \: X, \: YY)}$$
$$\mathrm{\delta(q0, \: c, \: X, \: Y) \: \rightarrow \: (q1, \: \lambda, \: \lambda)}$$
$$\mathrm{\delta(q1, \: c, \: X, \: Y) \: \rightarrow \: (q1, \: \lambda, \: \lambda)}$$
$$\mathrm{\delta(q1, \: \lambda, \: z1, \: z2) \: \rightarrow \: (qf, \: z1, \: z2)}$$
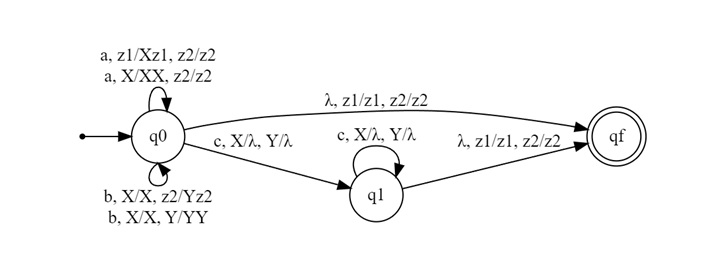
Explanation of Transitions
- The first line handles the case of an empty input string.
- The next two lines handle reading 'a' and pushing 'X' to stack 1.
- The fourth and fifth lines handle reading 'b' and pushing 'Y' to stack 2.
- The sixth and seventh lines handle reading 'c' and popping from both stacks.
- The last line checks if we have finished the string with empty stacks.
Why two-stack PDA is more powerful?
- They can recognize all context-free languages, just like regular PDAs.
- They can also recognize some context-sensitive languages, which regular PDAs can't.
- In fact, two-stack PDAs are equivalent to Turing machines! This means they can compute anything that's computable.
- This equivalence is proven by something called Minsky's theorem.
Conclusion
Two-stack Pushdown Automata are a powerful than normal one-stack pushdown automata. In this chapter, we explained the concept of two-stack pushdown automata with examples where we have three symbols at the same time. We also presented transition diagrams for easy understanding. A two-stack pushdown automaton is much advanced so that it is equivalent to Turing machines.
