- Automata Theory - Applications
- Automata Terminology
- Basics of String in Automata
- Set Theory for Automata
- Finite Sets and Infinite Sets
- Algebraic Operations on Sets
- Relations Sets in Automata Theory
- Graph and Tree in Automata Theory
- Transition Table in Automata
- What is Queue Automata?
- Compound Finite Automata
- Complementation Process in DFA
- Closure Properties in Automata
- Concatenation Process in DFA
- Language and Grammars
- Language and Grammar
- Grammars in Theory of Computation
- Language Generated by a Grammar
- Chomsky Classification of Grammars
- Context-Sensitive Languages
- Finite Automata
- What is Finite Automata?
- Finite Automata Types
- Applications of Finite Automata
- Limitations of Finite Automata
- Two-way Deterministic Finite Automata
- Deterministic Finite Automaton (DFA)
- Non-deterministic Finite Automaton (NFA)
- NDFA to DFA Conversion
- Equivalence of NFA and DFA
- Dead State in Finite Automata
- Minimization of DFA
- Automata Moore Machine
- Automata Mealy Machine
- Moore vs Mealy Machines
- Moore to Mealy Machine
- Mealy to Moore Machine
- Myhill–Nerode Theorem
- Mealy Machine for 1’s Complement
- Finite Automata Exercises
- Complement of DFA
- Regular Expressions
- Regular Expression in Automata
- Regular Expression Identities
- Applications of Regular Expression
- Regular Expressions vs Regular Grammar
- Kleene Closure in Automata
- Arden’s Theorem in Automata
- Convert Regular Expression to Finite Automata
- Conversion of Regular Expression to DFA
- Equivalence of Two Finite Automata
- Equivalence of Two Regular Expressions
- Convert Regular Expression to Regular Grammar
- Convert Regular Grammar to Finite Automata
- Pumping Lemma in Theory of Computation
- Pumping Lemma for Regular Grammar
- Pumping Lemma for Regular Expression
- Pumping Lemma for Regular Languages
- Applications of Pumping Lemma
- Closure Properties of Regular Set
- Closure Properties of Regular Language
- Decision Problems for Regular Languages
- Decision Problems for Automata and Grammars
- Conversion of Epsilon-NFA to DFA
- Regular Sets in Theory of Computation
- Context-Free Grammars
- Context-Free Grammars (CFG)
- Derivation Tree
- Parse Tree
- Ambiguity in Context-Free Grammar
- CFG vs Regular Grammar
- Applications of Context-Free Grammar
- Left Recursion and Left Factoring
- Closure Properties of Context Free Languages
- Simplifying Context Free Grammars
- Removal of Useless Symbols in CFG
- Removal Unit Production in CFG
- Removal of Null Productions in CFG
- Linear Grammar
- Chomsky Normal Form (CNF)
- Greibach Normal Form (GNF)
- Pumping Lemma for Context-Free Grammars
- Decision Problems of CFG
- Pushdown Automata
- Pushdown Automata (PDA)
- Pushdown Automata Acceptance
- Deterministic Pushdown Automata
- Non-deterministic Pushdown Automata
- Construction of PDA from CFG
- CFG Equivalent to PDA Conversion
- Pushdown Automata Graphical Notation
- Pushdown Automata and Parsing
- Two-stack Pushdown Automata
- Turing Machines
- Basics of Turing Machine (TM)
- Representation of Turing Machine
- Examples of Turing Machine
- Turing Machine Accepted Languages
- Variations of Turing Machine
- Multi-tape Turing Machine
- Multi-head Turing Machine
- Multitrack Turing Machine
- Non-Deterministic Turing Machine
- Semi-Infinite Tape Turing Machine
- K-dimensional Turing Machine
- Enumerator Turing Machine
- Universal Turing Machine
- Restricted Turing Machine
- Convert Regular Expression to Turing Machine
- Two-stack PDA and Turing Machine
- Turing Machine as Integer Function
- Post–Turing Machine
- Turing Machine for Addition
- Turing Machine for Copying Data
- Turing Machine as Comparator
- Turing Machine for Multiplication
- Turing Machine for Subtraction
- Modifications to Standard Turing Machine
- Linear-Bounded Automata (LBA)
- Church's Thesis for Turing Machine
- Recursively Enumerable Language
- Computability & Undecidability
- Turing Language Decidability
- Undecidable Languages
- Turing Machine and Grammar
- Kuroda Normal Form
- Converting Grammar to Kuroda Normal Form
- Decidability
- Undecidability
- Reducibility
- Halting Problem
- Turing Machine Halting Problem
- Rice's Theorem in Theory of Computation
- Post’s Correspondence Problem (PCP)
- Types of Functions
- Recursive Functions
- Injective Functions
- Surjective Function
- Bijective Function
- Partial Recursive Function
- Total Recursive Function
- Primitive Recursive Function
- μ Recursive Function
- Ackermann’s Function
- Russell’s Paradox
- Gödel Numbering
- Recursive Enumerations
- Kleene's Theorem
- Kleene's Recursion Theorem
- Advanced Concepts
- Matrix Grammars
- Probabilistic Finite Automata
- Cellular Automata
- Reduction of CFG
- Reduction Theorem
- Regular expression to ∈-NFA
- Quotient Operation
- Parikh’s Theorem
- Ladner’s Theorem
MyhillNerode Theorem in Automata
Deterministic Finite Automata (DFA) are abstract machines that read a string of symbols and decide whether to accept or reject it based on a set of states and transitions and final states. Sometimes DFA has some unnecessary states while converting from NFA and we need to minimize the DFA to find the smallest DFA that recognizes the same language as a given DFA.
In this chapter, we will see the table filling method which is known as MyhillNerode Theorem for minimizing DFAs.
Concepts of DFA Minimization
Before understanding the table filling method, let's see why DFA minimization is important. Suppose we have a DFA with many states, possibly redundant. A minimized DFA, recognizing the same language with fewer states, offers several advantages −
- Simplicity − Easier to understand and visualize the behavior of the automaton.
- Efficiency− Less memory and processing power required to implement the DFA.
- Optimization − Improved performance in applications using the minimized DFA.
MyhillNerode Theorem
The theorem states that a language L is regular if L~ (L~ is relation on strings x and y, where no distinguishable extension for x and y) has a finite number of equivalence classes, and if this number is N, then there are N states in a minimal Deterministic Finite Automaton (DFA) recognizing L.
To see this theorem in action, let us consider a DFA and the corresponding table filling method.
Algorithm
The algorithm for the theorem is as follows −
- Create a table with all possible pairs of states from the given DFA. Each cell in the table will represent a pair of states, like (A, B), (C, D), etc.
- Mark all pairs where P belongs to the final state, and Q does not belong to the final state. This means that for each pair of states in the table, check whether one state is a final state, and the other is not. If this condition is met, we mark that pair in the table.
- If there are any unmarked pairs PQ, such that the transition of P on X and the transition of Q on X is marked, then mark PQ, where X is an input symbol. After marking the pairs in the second step, we move on to the unmarked pairs. For each unmarked pair (P, Q), check their transitions on every input symbol (X). If both P and Q transition to a pair that is already marked in the table, then mark the pair (P, Q).
- Repeat step 3 until you cannot make any new markings in the table. This means we have exhausted all possible combinations and identified all the distinguishable pairs of states.
- At the end combine all the unmarked pairs and make them a single state in the minimized DFA.
Example of Myhill-Nerode Theorem
Consider we have a DFA like below −
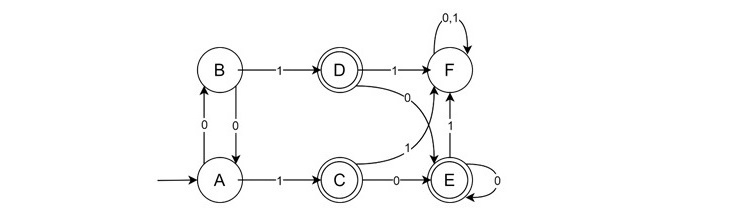
Here,
- States: {A, B, C, D, E, F}
- Input Symbols: {0, 1}
- Start State: A
- Final States: {C, D, E}
State Transition Table
The state transition table will be like the shown here −
| State | 0 | 1 |
|---|---|---|
| A | B | C |
| B | A | D |
| C | E | A |
| D | E | F |
| E | E | F |
| F | F | F |
To make the table for the theorem we need 6 × 6 table, but the upper triangle is not needed, so we can remove them.

After the first step, we jump to the second step to fill the table −
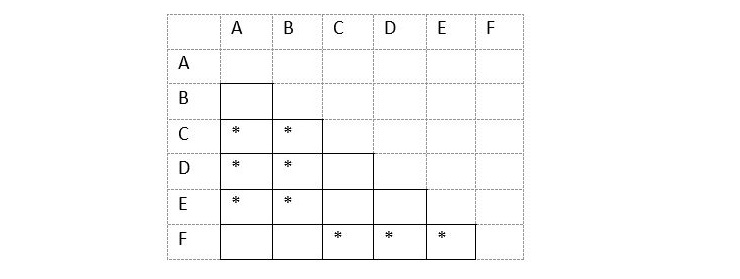
For any pair (A, C) any one is final, then mark it, for (C, F) one is final so mark it, for (C,D) both are final so not marked. Like (A, B) both are non-final so do not mark it.
Based on the 3rd stage, we pick unmarked cells and check.
For a pair (B, A), check −
- δ(B, 0) = A and δ(A, 0) = B, since the new pair (B, A) is not marked, nothing will be marked now.
- δ(B, 1) = D and δ(A, 1) = C, since the new pair (C, D) is not marked, nothing will be marked now.
For a pair (D, C), check −
- δ(D, 0) = E and δ(C, 0) = E, since the new pair (E, E) is not in the table, nothing will be marked now.
- δ(D, 1) = F and δ(C, 1) = F, since the new pair (F, F) is not in the table, nothing will be marked now.
For a pair (E, C), check −
- δ(E, 0) = E and δ(C, 0) = E, since the new pair (E, E) is not in the table, nothing will be marked now.
- δ(E, 1) = F and δ(C, 1) = F, since the new pair (F, F) is not in the table, nothing will be marked now.
For a pair (E, D), check −
- δ(E, 0) = E and δ(D, 0) = E, since the new pair (E, E) is not in the table, nothing will be marked now.
- δ(E, 1) = F and δ(D, 1) = F, since the new pair (F, F) is not in the table, nothing will be marked now.
For a pair (F, A), check −
- δ(F, 0) = F and δ(A, 0) = B, since the new pair (F, B) is not marked, nothing will be marked now.
- δ(F, 1) = F and δ(A, 1) = C, since the new pair (F, C) is marked, then we have to mark the current pair (F, A) also.
For a pair (F, B), check −
- δ(F, 0) = F and δ(B, 0) = A, since the new pair (F, A) is marked in the previous step, we have to mark (F, B).
- δ(F, 1) = F and δ(B, 1) = C, since the new pair (F, C) is marked, then we have to mark the current pair (F, A) also.
Now let us see the updated table once −
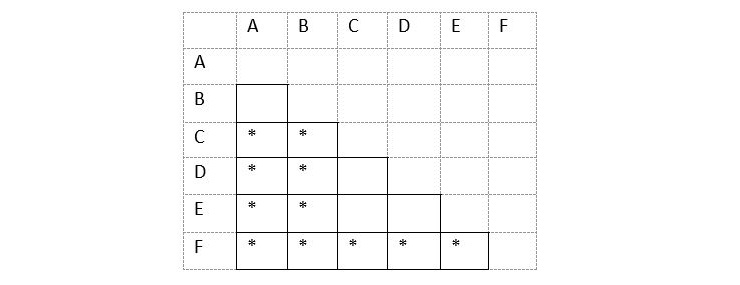
In step 4, it states repeat step 3 until there is no other marks. You can check, but here we do not have any new marking in the next iteration. So go to the next step.
The unmarked pairs are (B, A), (D, C), (E, C), (E, D)
Now let us draw the minimized DFA −

(D, C), (E, C), (E, D) contains the common elements so these are merged. And we are getting the minimized DFA.
Conclusion
The table filling method, or Myhill-Nerode Theorem, gives us a structured approach to minimizing DFAs. By systematically analyzing state transitions and identifying equivalent states, we can achieve a smaller DFA that recognizes the same language. The minimized DFA provides benefits optimization in many sense. Here we explained the table filling style with examples and explanations.
