- Automata Theory - Applications
- Automata Terminology
- Basics of String in Automata
- Set Theory for Automata
- Finite Sets and Infinite Sets
- Algebraic Operations on Sets
- Relations Sets in Automata Theory
- Graph and Tree in Automata Theory
- Transition Table in Automata
- What is Queue Automata?
- Compound Finite Automata
- Complementation Process in DFA
- Closure Properties in Automata
- Concatenation Process in DFA
- Language and Grammars
- Language and Grammar
- Grammars in Theory of Computation
- Language Generated by a Grammar
- Chomsky Classification of Grammars
- Context-Sensitive Languages
- Finite Automata
- What is Finite Automata?
- Finite Automata Types
- Applications of Finite Automata
- Limitations of Finite Automata
- Two-way Deterministic Finite Automata
- Deterministic Finite Automaton (DFA)
- Non-deterministic Finite Automaton (NFA)
- NDFA to DFA Conversion
- Equivalence of NFA and DFA
- Dead State in Finite Automata
- Minimization of DFA
- Automata Moore Machine
- Automata Mealy Machine
- Moore vs Mealy Machines
- Moore to Mealy Machine
- Mealy to Moore Machine
- Myhill–Nerode Theorem
- Mealy Machine for 1’s Complement
- Finite Automata Exercises
- Complement of DFA
- Regular Expressions
- Regular Expression in Automata
- Regular Expression Identities
- Applications of Regular Expression
- Regular Expressions vs Regular Grammar
- Kleene Closure in Automata
- Arden’s Theorem in Automata
- Convert Regular Expression to Finite Automata
- Conversion of Regular Expression to DFA
- Equivalence of Two Finite Automata
- Equivalence of Two Regular Expressions
- Convert Regular Expression to Regular Grammar
- Convert Regular Grammar to Finite Automata
- Pumping Lemma in Theory of Computation
- Pumping Lemma for Regular Grammar
- Pumping Lemma for Regular Expression
- Pumping Lemma for Regular Languages
- Applications of Pumping Lemma
- Closure Properties of Regular Set
- Closure Properties of Regular Language
- Decision Problems for Regular Languages
- Decision Problems for Automata and Grammars
- Conversion of Epsilon-NFA to DFA
- Regular Sets in Theory of Computation
- Context-Free Grammars
- Context-Free Grammars (CFG)
- Derivation Tree
- Parse Tree
- Ambiguity in Context-Free Grammar
- CFG vs Regular Grammar
- Applications of Context-Free Grammar
- Left Recursion and Left Factoring
- Closure Properties of Context Free Languages
- Simplifying Context Free Grammars
- Removal of Useless Symbols in CFG
- Removal Unit Production in CFG
- Removal of Null Productions in CFG
- Linear Grammar
- Chomsky Normal Form (CNF)
- Greibach Normal Form (GNF)
- Pumping Lemma for Context-Free Grammars
- Decision Problems of CFG
- Pushdown Automata
- Pushdown Automata (PDA)
- Pushdown Automata Acceptance
- Deterministic Pushdown Automata
- Non-deterministic Pushdown Automata
- Construction of PDA from CFG
- CFG Equivalent to PDA Conversion
- Pushdown Automata Graphical Notation
- Pushdown Automata and Parsing
- Two-stack Pushdown Automata
- Turing Machines
- Basics of Turing Machine (TM)
- Representation of Turing Machine
- Examples of Turing Machine
- Turing Machine Accepted Languages
- Variations of Turing Machine
- Multi-tape Turing Machine
- Multi-head Turing Machine
- Multitrack Turing Machine
- Non-Deterministic Turing Machine
- Semi-Infinite Tape Turing Machine
- K-dimensional Turing Machine
- Enumerator Turing Machine
- Universal Turing Machine
- Restricted Turing Machine
- Convert Regular Expression to Turing Machine
- Two-stack PDA and Turing Machine
- Turing Machine as Integer Function
- Post–Turing Machine
- Turing Machine for Addition
- Turing Machine for Copying Data
- Turing Machine as Comparator
- Turing Machine for Multiplication
- Turing Machine for Subtraction
- Modifications to Standard Turing Machine
- Linear-Bounded Automata (LBA)
- Church's Thesis for Turing Machine
- Recursively Enumerable Language
- Computability & Undecidability
- Turing Language Decidability
- Undecidable Languages
- Turing Machine and Grammar
- Kuroda Normal Form
- Converting Grammar to Kuroda Normal Form
- Decidability
- Undecidability
- Reducibility
- Halting Problem
- Turing Machine Halting Problem
- Rice's Theorem in Theory of Computation
- Post’s Correspondence Problem (PCP)
- Types of Functions
- Recursive Functions
- Injective Functions
- Surjective Function
- Bijective Function
- Partial Recursive Function
- Total Recursive Function
- Primitive Recursive Function
- μ Recursive Function
- Ackermann’s Function
- Russell’s Paradox
- Gödel Numbering
- Recursive Enumerations
- Kleene's Theorem
- Kleene's Recursion Theorem
- Advanced Concepts
- Matrix Grammars
- Probabilistic Finite Automata
- Cellular Automata
- Reduction of CFG
- Reduction Theorem
- Regular expression to ∈-NFA
- Quotient Operation
- Parikh’s Theorem
- Ladner’s Theorem
Probabilistic Finite Automata
Probabilistic Finite Automata (PFA) is an extension of traditional finite automata that incorporates probabilities into state transitions. This approach is useful for to design systems where outcomes are not deterministic but instead have some uncertainty (or probability).
In this chapter, we will see the basics of Probabilistic Finite Automata and understand it through example to understand how they work.
Basics of Probabilistic Finite Automata
A Probabilistic Finite Automaton (PFA) is nothing but a finite automaton where each transition between states is assigned a probability. This concept was first introduced by O. Rabin in 1963.
Unlike the deterministic finite automata (DFA) or non-deterministic finite automata (NFA), where the transitions are definite and has probability 1.0 for each transition, in a PFA, the transitions are probabilistic. This means that for each input symbol, the automaton may move to different states with certain probabilities.
Definition and Components
The formal definition of PFA is −
$$\mathrm{\{Q,\: \Sigma,\: \delta,\: I,\: F,\: M \}}$$
Where,
- Q − A finite set of states.
- Σ − A finite set of input symbols (also known as the alphabet).
- δ − A transition function that takes a state and an input symbol and returns a probability distribution over the states.
- I − The initial state probability distribution. It represents the probability of starting in each state.
- F − The final state probability distribution. It shows the probability of ending in each state.
- M − A probability matrix associated with each input symbol, determining the likelihood of transitions between states.
Understanding the Probability Matrix
In PFA, the transition probabilities for each input symbol form what is called a stochastic matrix or probability matrix. Each row of the matrix corresponds to a current state, and each column corresponds to a possible next state. The value in each cell of the matrix represents the probability of transitioning from one state to another upon reading a particular input symbol.
For example, consider the following probability matrices for the input symbols a and b −
M(a) =
| States | q0 | qf |
|---|---|---|
| q0 | 0 | 1.0 |
| qf | 0.8 | 0.2 |
M(b) =
| States | q0 | qf |
|---|---|---|
| q0 | 0.3 | 0.7 |
| qf | 1.0 | 0 |
In this setup, the transition diagram will look like the following −
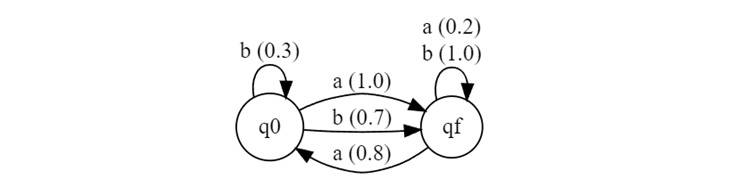
M(a) indicates that when the automaton reads a in state q0, it will definitely move to state qf with probability 1.0. In state qf, upon reading a, it has a 0.8 probability of staying in qf and a 0.2 probability of moving to q0.
M(b) suggests that on reading b in state q0, there is a 0.3 probability of staying in q0 and a 0.7 probability of moving to qf.
Initial and Final State Probabilities
The PFA also requires us to define the initial and final state probabilities:
- Initial State Probability (I) − This represents the probability distribution over the states at the beginning of the process.
- Final State Probability (F) − This represents the probability distribution over the states at the end of the process.
For instance, if the initial state probability is I(q0) = 1 and I(qf) = 0, the automaton starts in state q0 with certainty. Similarly, if F(q0) = 0 and F(qf) = 1, the automaton must end in state qf.
Example: String Acceptance by a PFA
Let us see another example to understand how a PFA better. It will check if a string is accepted.
Example Setup
Consider a PFA with the following components −
- States − {q0, qf}
- Input Symbols − {a, b}
- Initial State Probability − I = {1, 0} (The automaton starts in q0 with probability 1)
- Final State Probability − F = {0, 1} (The automaton ends in qf with probability 1)
Probability Matrices
M(a) =
| States | q0 | qf |
|---|---|---|
| q0 | 0.25 | 0.5 |
| qf | 0 | 1 |
M(b) =
| States | q0 | qf |
|---|---|---|
| q0 | 0.5 | 0.75 |
| qf | 1.0 | 0 |
The machine will be like −
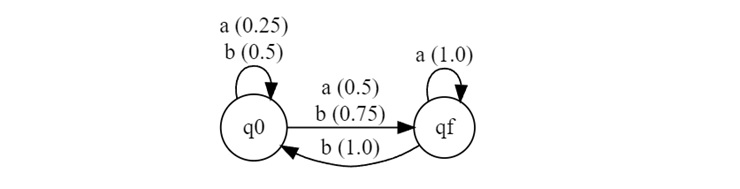
String Processing: ab and baa
Let us calculate whether the strings ab and ba are accepted by this PFA.
For the string "ab" −
$$\mathrm{I \:\times\: M(ab)\: \times\: F^T \:=\: I \:\times\: M(a)\: \times\: M(b)\: \times\: F^T}$$
$$\mathrm{\left[ \begin{array}{cc} 1 & 0 \end{array} \right] \times \left[ \begin{array}{cc} 0.25 & 0.5 \\ 0 & 1 \end{array} \right] \times \left[ \begin{array}{cc} 0.5 & 0.75 \\ 1 & 0 \end{array} \right] \times \left[ \begin{array}{c} 0 \\ 1 \end{array} \right]}$$
$$\mathrm{= 0.1875}$$
The acceptance probability is 0.1875
For the string "ba" −
$$\mathrm{I \times M(ba) \times F^T = I \times M(b) \times M(a) \times F^T}$$
$$\mathrm{\left[ \begin{array}{cc} 1 & 0 \end{array} \right] \times \left[ \begin{array}{cc} 0.5 & 0.75 \\ 1 & 0 \end{array} \right] \times \left[ \begin{array}{cc} 0.25 & 0.5 \\ 0 & 1 \end{array} \right] \times \left[ \begin{array}{c} 0 \\ 1 \end{array} \right]}$$
$$\mathrm{= 1}$$
The acceptance probability is 1.0, so it will be accepted.
Conclusion
In this chapter, we covered the basics of Probabilistic Finite Automata (PFA). The idea of PFA is unique and it is a powerful extension of finite automata that states probabilities into state transitions.
We explored the fundamental components of a PFA, including states, input symbols, transition functions, and probability matrices. Through the example, we explained how a PFA processes strings and check whether they are accepted based on the calculated probabilities or not.
