- Automata Theory - Applications
- Automata Terminology
- Basics of String in Automata
- Set Theory for Automata
- Finite Sets and Infinite Sets
- Algebraic Operations on Sets
- Relations Sets in Automata Theory
- Graph and Tree in Automata Theory
- Transition Table in Automata
- What is Queue Automata?
- Compound Finite Automata
- Complementation Process in DFA
- Closure Properties in Automata
- Concatenation Process in DFA
- Language and Grammars
- Language and Grammar
- Grammars in Theory of Computation
- Language Generated by a Grammar
- Chomsky Classification of Grammars
- Context-Sensitive Languages
- Finite Automata
- What is Finite Automata?
- Finite Automata Types
- Applications of Finite Automata
- Limitations of Finite Automata
- Two-way Deterministic Finite Automata
- Deterministic Finite Automaton (DFA)
- Non-deterministic Finite Automaton (NFA)
- NDFA to DFA Conversion
- Equivalence of NFA and DFA
- Dead State in Finite Automata
- Minimization of DFA
- Automata Moore Machine
- Automata Mealy Machine
- Moore vs Mealy Machines
- Moore to Mealy Machine
- Mealy to Moore Machine
- Myhill–Nerode Theorem
- Mealy Machine for 1’s Complement
- Finite Automata Exercises
- Complement of DFA
- Regular Expressions
- Regular Expression in Automata
- Regular Expression Identities
- Applications of Regular Expression
- Regular Expressions vs Regular Grammar
- Kleene Closure in Automata
- Arden’s Theorem in Automata
- Convert Regular Expression to Finite Automata
- Conversion of Regular Expression to DFA
- Equivalence of Two Finite Automata
- Equivalence of Two Regular Expressions
- Convert Regular Expression to Regular Grammar
- Convert Regular Grammar to Finite Automata
- Pumping Lemma in Theory of Computation
- Pumping Lemma for Regular Grammar
- Pumping Lemma for Regular Expression
- Pumping Lemma for Regular Languages
- Applications of Pumping Lemma
- Closure Properties of Regular Set
- Closure Properties of Regular Language
- Decision Problems for Regular Languages
- Decision Problems for Automata and Grammars
- Conversion of Epsilon-NFA to DFA
- Regular Sets in Theory of Computation
- Context-Free Grammars
- Context-Free Grammars (CFG)
- Derivation Tree
- Parse Tree
- Ambiguity in Context-Free Grammar
- CFG vs Regular Grammar
- Applications of Context-Free Grammar
- Left Recursion and Left Factoring
- Closure Properties of Context Free Languages
- Simplifying Context Free Grammars
- Removal of Useless Symbols in CFG
- Removal Unit Production in CFG
- Removal of Null Productions in CFG
- Linear Grammar
- Chomsky Normal Form (CNF)
- Greibach Normal Form (GNF)
- Pumping Lemma for Context-Free Grammars
- Decision Problems of CFG
- Pushdown Automata
- Pushdown Automata (PDA)
- Pushdown Automata Acceptance
- Deterministic Pushdown Automata
- Non-deterministic Pushdown Automata
- Construction of PDA from CFG
- CFG Equivalent to PDA Conversion
- Pushdown Automata Graphical Notation
- Pushdown Automata and Parsing
- Two-stack Pushdown Automata
- Turing Machines
- Basics of Turing Machine (TM)
- Representation of Turing Machine
- Examples of Turing Machine
- Turing Machine Accepted Languages
- Variations of Turing Machine
- Multi-tape Turing Machine
- Multi-head Turing Machine
- Multitrack Turing Machine
- Non-Deterministic Turing Machine
- Semi-Infinite Tape Turing Machine
- K-dimensional Turing Machine
- Enumerator Turing Machine
- Universal Turing Machine
- Restricted Turing Machine
- Convert Regular Expression to Turing Machine
- Two-stack PDA and Turing Machine
- Turing Machine as Integer Function
- Post–Turing Machine
- Turing Machine for Addition
- Turing Machine for Copying Data
- Turing Machine as Comparator
- Turing Machine for Multiplication
- Turing Machine for Subtraction
- Modifications to Standard Turing Machine
- Linear-Bounded Automata (LBA)
- Church's Thesis for Turing Machine
- Recursively Enumerable Language
- Computability & Undecidability
- Turing Language Decidability
- Undecidable Languages
- Turing Machine and Grammar
- Kuroda Normal Form
- Converting Grammar to Kuroda Normal Form
- Decidability
- Undecidability
- Reducibility
- Halting Problem
- Turing Machine Halting Problem
- Rice's Theorem in Theory of Computation
- Post’s Correspondence Problem (PCP)
- Types of Functions
- Recursive Functions
- Injective Functions
- Surjective Function
- Bijective Function
- Partial Recursive Function
- Total Recursive Function
- Primitive Recursive Function
- μ Recursive Function
- Ackermann’s Function
- Russell’s Paradox
- Gödel Numbering
- Recursive Enumerations
- Kleene's Theorem
- Kleene's Recursion Theorem
- Advanced Concepts
- Matrix Grammars
- Probabilistic Finite Automata
- Cellular Automata
- Reduction of CFG
- Reduction Theorem
- Regular expression to ∈-NFA
- Quotient Operation
- Parikh’s Theorem
- Ladner’s Theorem
Derivation Tree in Automata Theory
In automata theory, we use derivation trees or parse trees to derive language from grammars. In this chapter, we will see the concept of derivation trees in the context of context-free-grammars. Derivation tree is a fundamental tool in understanding and representing the structure of strings generated by context-free grammars.
What are Derivation Tree?
A Derivation Tree, also known as a Parse Tree, is a visual representation of the process by which a context-free grammar generates a particular string. It provides a hierarchical breakdown of the string. This illustrates the sequence of production rules applied to derive the string from the grammar's start symbol.
Key Elements of a Derivation Tree
Before learning how to construct a derivation tree, let's understand their essential components:
- Root Vertex − The root vertex represents the starting point of the derivation process and is always labeled with the grammar's start symbol.
- Vertices (Internal Nodes) − These nodes represent the non-terminal symbols of the grammar, serving as intermediate stages in the derivation.
- Leaves − These nodes represent the terminal symbols of the grammar, forming the final string derived from the grammar. They can also be labeled with the empty symbol, ε, if the grammar allows for empty productions.
Example of Context-Free Grammar
Let's consider the following context-free grammar G −
$$\mathrm{G \:=\: (V,\: T,\: P,\: S)}$$
Where,
- V = {S, A, B} (Variables or Non-terminal symbols)
- T = {0, 1} (Terminal symbols)
- P = {S → 0B, A → 1AA | ε, B → 0AA} (Production Rules)
- S = S (Start Symbol)
This grammar defines a language where strings begin with a '0', then followed by a combination of '0's and '1's.
Derivation Tree Construction
To illustrate the formation of a derivation tree, let us examine the derivation of the string "001" from the grammar G:
Root Vertex
We begin by placing the start symbol 'S' as the root vertex of the tree.
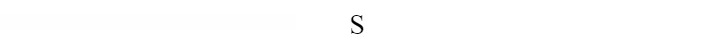
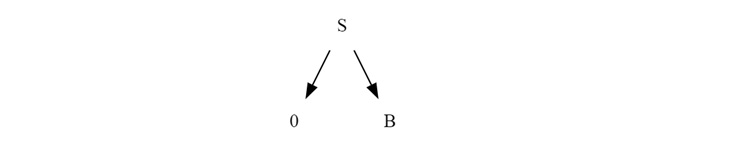
Applying Production Rules
Looking at the production rules, we see that 'S' can be replaced by "0B".
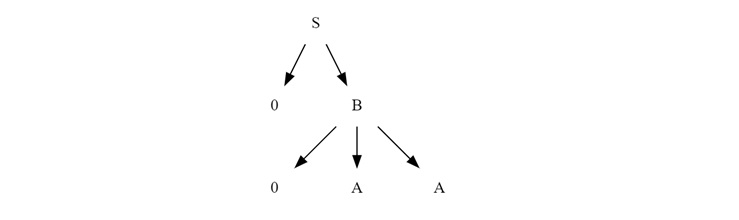
Continuing the Derivation
The rightmost vertex is 'B', and the production rule for 'B' is "0AA". Applying this rule, we obtain −
Reaching Terminal Symbols
Now, we have two 'A' variables. Since the production rule for 'A' allows for the empty string 'ε', we can replace the right most 'A's with 'ε', and left A to 1AA.
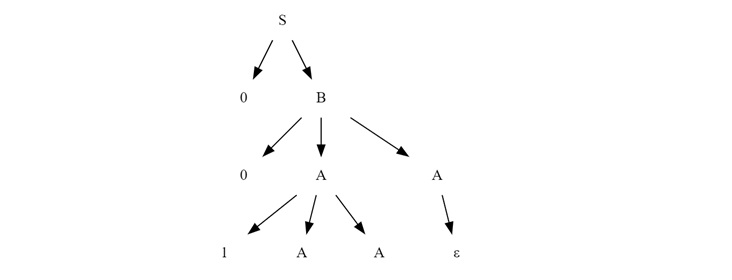
Now from the final non-terminals A to ε to get final tree.

This final structure represents the derivation tree for the string "001" from grammar G.
Left Derivation Tree and Right Derivation Tree
There are two primary methods for constructing derivation trees: The left derivation and right derivation. These methods dictate the order in which production rules are applied to non-terminal symbols within the sentential form.
- Left Derivation Tree − A Left Derivation Tree is generated by consistently applying production rules to the leftmost variable in each step of the derivation. This method uses expanding the non-terminal symbols on the left side of the sentential form.
- Right Derivation Tree − A Right Derivation Tree is obtained by applying production rules to the rightmost variable in each step. This method uses expanding non-terminal symbols on the right side of the sentential form.
Example of Left and Right Derivation Trees
Let's consider a new grammar and generate both left and right derivation trees to understand the difference in their construction.
Grammar −
$$\mathrm{S \: \rightarrow \: aAS | aSS | ε}$$
$$\mathrm{A \: \rightarrow \: SbA | ba}$$
$$\mathrm{\text{String to derive: "aabbaa"}}$$
Left Derivation Tree
For the left derivation tree, we start from S.

- Applying Leftmost Derivation − We apply the production rule 'S → aSS' to the leftmost 'S'.
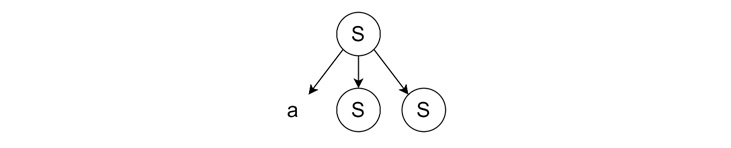
- Expanding Leftmost Variable − We expand the leftmost 'S' using the rule 'S → aAS'.
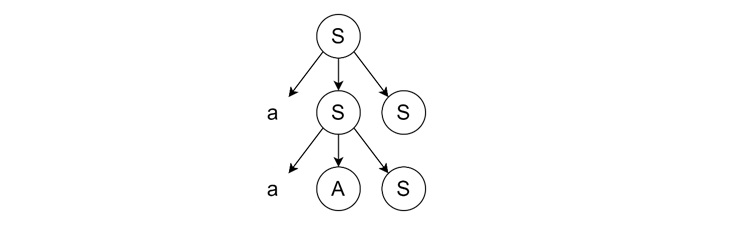
- Continuing Leftmost Derivation − We continue expanding the leftmost 'A' using the rule 'A → ba'.
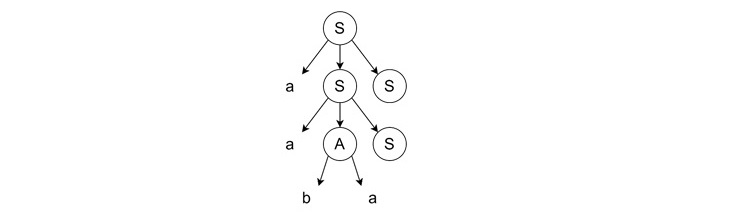
- Completing the Derivation − We expand the next leftmost S to aSS, and from there remaining S to 'S → ε'.
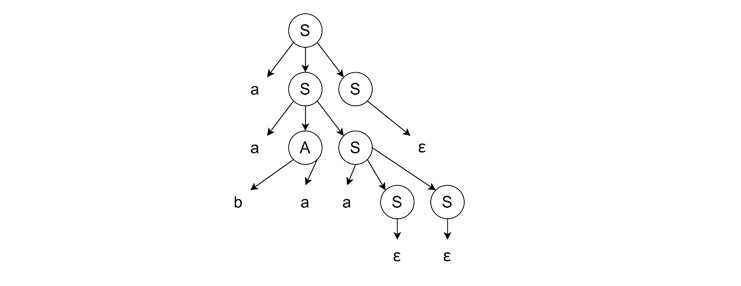
Right Derivation Tree
Like left most derivation, we start from the start symbol 'S'.
- Applying Rightmost Derivation − We apply the production rule 'S → aSS' to the rightmost 'S'.
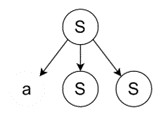
- Expanding Rightmost Variable − We expand the rightmost 'S' using the rule 'S → aAS'.
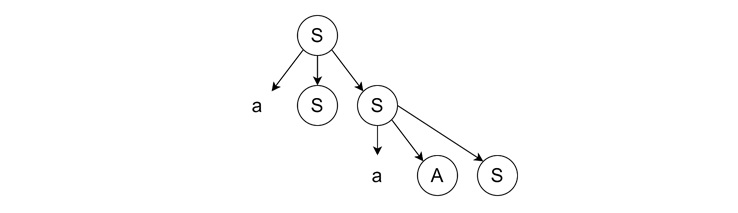
- Continuing Rightmost Derivation − We expand the rightmost 'S' using the rule 'S → aSS'.
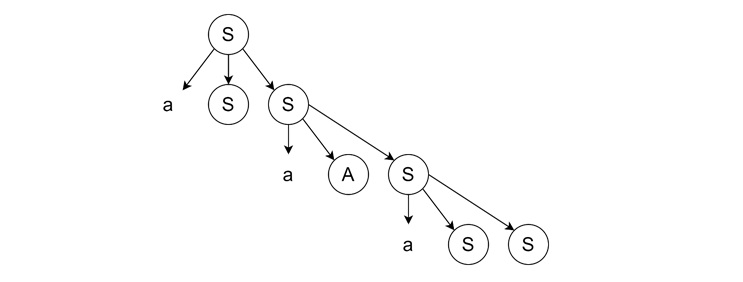
- Completing the Derivation − We expand the remaining 'A' and 'S' from the right to left, the last two S will produce ε. Then A will bring ‘ba’ and the leftmost S will bring ε again.
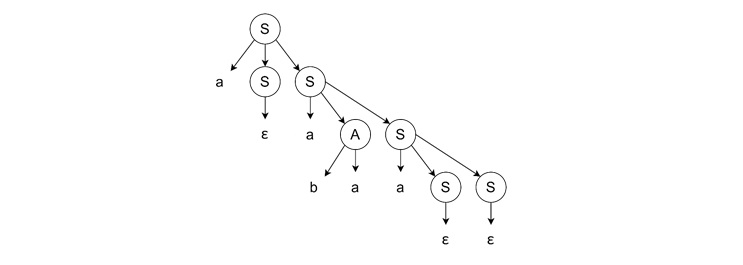
Conclusion
Derivation trees provide a method of visualizing the structure of strings generated by context-free grammars. These are essential in several cases including understanding the concepts CFG derivation, parsing in compiler design, etc. In this chapter, we explained the concepts in detail with step by step examples for a clear understanding.
