- Automata Theory - Applications
- Automata Terminology
- Basics of String in Automata
- Set Theory for Automata
- Finite Sets and Infinite Sets
- Algebraic Operations on Sets
- Relations Sets in Automata Theory
- Graph and Tree in Automata Theory
- Transition Table in Automata
- What is Queue Automata?
- Compound Finite Automata
- Complementation Process in DFA
- Closure Properties in Automata
- Concatenation Process in DFA
- Language and Grammars
- Language and Grammar
- Grammars in Theory of Computation
- Language Generated by a Grammar
- Chomsky Classification of Grammars
- Context-Sensitive Languages
- Finite Automata
- What is Finite Automata?
- Finite Automata Types
- Applications of Finite Automata
- Limitations of Finite Automata
- Two-way Deterministic Finite Automata
- Deterministic Finite Automaton (DFA)
- Non-deterministic Finite Automaton (NFA)
- NDFA to DFA Conversion
- Equivalence of NFA and DFA
- Dead State in Finite Automata
- Minimization of DFA
- Automata Moore Machine
- Automata Mealy Machine
- Moore vs Mealy Machines
- Moore to Mealy Machine
- Mealy to Moore Machine
- Myhill–Nerode Theorem
- Mealy Machine for 1’s Complement
- Finite Automata Exercises
- Complement of DFA
- Regular Expressions
- Regular Expression in Automata
- Regular Expression Identities
- Applications of Regular Expression
- Regular Expressions vs Regular Grammar
- Kleene Closure in Automata
- Arden’s Theorem in Automata
- Convert Regular Expression to Finite Automata
- Conversion of Regular Expression to DFA
- Equivalence of Two Finite Automata
- Equivalence of Two Regular Expressions
- Convert Regular Expression to Regular Grammar
- Convert Regular Grammar to Finite Automata
- Pumping Lemma in Theory of Computation
- Pumping Lemma for Regular Grammar
- Pumping Lemma for Regular Expression
- Pumping Lemma for Regular Languages
- Applications of Pumping Lemma
- Closure Properties of Regular Set
- Closure Properties of Regular Language
- Decision Problems for Regular Languages
- Decision Problems for Automata and Grammars
- Conversion of Epsilon-NFA to DFA
- Regular Sets in Theory of Computation
- Context-Free Grammars
- Context-Free Grammars (CFG)
- Derivation Tree
- Parse Tree
- Ambiguity in Context-Free Grammar
- CFG vs Regular Grammar
- Applications of Context-Free Grammar
- Left Recursion and Left Factoring
- Closure Properties of Context Free Languages
- Simplifying Context Free Grammars
- Removal of Useless Symbols in CFG
- Removal Unit Production in CFG
- Removal of Null Productions in CFG
- Linear Grammar
- Chomsky Normal Form (CNF)
- Greibach Normal Form (GNF)
- Pumping Lemma for Context-Free Grammars
- Decision Problems of CFG
- Pushdown Automata
- Pushdown Automata (PDA)
- Pushdown Automata Acceptance
- Deterministic Pushdown Automata
- Non-deterministic Pushdown Automata
- Construction of PDA from CFG
- CFG Equivalent to PDA Conversion
- Pushdown Automata Graphical Notation
- Pushdown Automata and Parsing
- Two-stack Pushdown Automata
- Turing Machines
- Basics of Turing Machine (TM)
- Representation of Turing Machine
- Examples of Turing Machine
- Turing Machine Accepted Languages
- Variations of Turing Machine
- Multi-tape Turing Machine
- Multi-head Turing Machine
- Multitrack Turing Machine
- Non-Deterministic Turing Machine
- Semi-Infinite Tape Turing Machine
- K-dimensional Turing Machine
- Enumerator Turing Machine
- Universal Turing Machine
- Restricted Turing Machine
- Convert Regular Expression to Turing Machine
- Two-stack PDA and Turing Machine
- Turing Machine as Integer Function
- Post–Turing Machine
- Turing Machine for Addition
- Turing Machine for Copying Data
- Turing Machine as Comparator
- Turing Machine for Multiplication
- Turing Machine for Subtraction
- Modifications to Standard Turing Machine
- Linear-Bounded Automata (LBA)
- Church's Thesis for Turing Machine
- Recursively Enumerable Language
- Computability & Undecidability
- Turing Language Decidability
- Undecidable Languages
- Turing Machine and Grammar
- Kuroda Normal Form
- Converting Grammar to Kuroda Normal Form
- Decidability
- Undecidability
- Reducibility
- Halting Problem
- Turing Machine Halting Problem
- Rice's Theorem in Theory of Computation
- Post’s Correspondence Problem (PCP)
- Types of Functions
- Recursive Functions
- Injective Functions
- Surjective Function
- Bijective Function
- Partial Recursive Function
- Total Recursive Function
- Primitive Recursive Function
- μ Recursive Function
- Ackermann’s Function
- Russell’s Paradox
- Gödel Numbering
- Recursive Enumerations
- Kleene's Theorem
- Kleene's Recursion Theorem
- Advanced Concepts
- Matrix Grammars
- Probabilistic Finite Automata
- Cellular Automata
- Reduction of CFG
- Reduction Theorem
- Regular expression to ∈-NFA
- Quotient Operation
- Parikh’s Theorem
- Ladner’s Theorem
Convert Regular Grammar to Finite Automata
In the last chapter, we covered how to convert finite automata to regular grammar. In this chapter, we will understand the steps to convert a regular grammar to finite automata.
The process of converting a regular grammar containing epsilon productions into a finite automata is not a complex process. Here we will see the steps involved, covering the crucial step of eliminating epsilon productions before constructing the automata. We will also have an example to get a better understanding of the concept.
Understanding Epsilon Productions
As we know the null production or epsilon productions are a key concept in formal language theory. An epsilon production in a grammar is a production of the form A → ε, where 'A' is a non-terminal symbol, and 'ε' represents the empty string (a string with no symbols).
These productions can pose a challenge when converting a grammar into a finite automata, as they introduce the potential for empty transitions.
The Need for Epsilon-Free Grammars
Finite automata, by definition, operate on strings of symbols. They cannot directly handle transitions that involve the empty string. So, before we can convert a grammar containing epsilon productions into a finite automata, we need to eliminate these productions.
Eliminating Epsilon Productions: A Step-by-Step Approach
Let's see the process of converting a regular grammar with epsilon productions to an epsilon-free grammar using a concrete example. Consider the following grammar −
S → a, aA | bB A → aA | aS B → cS S → ε B → ε
Step 1: Identifying Epsilon Productions
First, we identify the epsilon productions in our grammar. In this case, they are −
S → ε B → ε
Step 2: Generating Non-Epsilon Productions
We list all the productions that do not involve epsilon. These are the productions that form the basis of our epsilon-free grammar −
S → a, aA | bB A → aA | aS B → cS
Step 3: Replacing Epsilon Productions
Now, we systematically replace all occurrences of non-terminals with epsilon productions in the right-hand sides of our productions.
- In 'A → aA | aS', replacing 'S' with 'ε' yields 'A → aA | ε'. Since 'ε' is the empty string, we can simplify this to 'A → aA'.
- In 'B → cS', replacing 'S' with 'ε' yields 'B → c'.
- In 'S → aA | bB', replacing 'B' with 'ε' yields 'S → aA | b'.
The final productions will be like,
S → a, aA | b A → aA | aS | a B → cS | c
Step 4: Handling the Start Symbol
The start symbol 'S' has an epsilon production. This means that the start symbol can derive the empty string, which is often acceptable in finite automata.
However, if the start symbol has an epsilon production, we need to add a new start symbol ('S1' in our example) that inherits all the productions of the original start symbol, including the epsilon production. This new start symbol ensures that the empty string can be accepted by the automata.
S1 → a | aA | b | bB | ε S → a, aA | b A → aA | aS | a B → cS | c
Converting the Epsilon-Free Grammar to a Finite Automata
Now it is time to convert the final finite automata from the above grammar. We have five states {S1, S, A, B, C}. The S1 and C will be the final state, S1 is final because it has null transition.
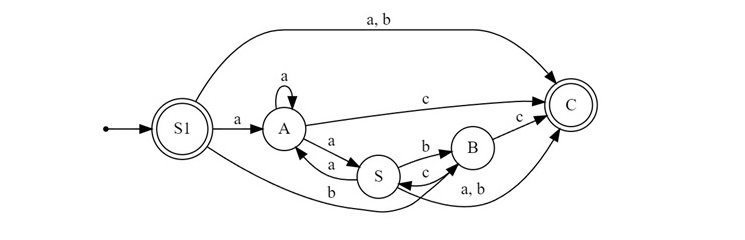
Conclusion
In this chapter, we have had a detailed explanation on how to convert regular grammar to finite automata.
Converting a regular grammar with epsilon productions into a finite automata is a two-step process. First, we eliminate epsilon productions, ensuring a grammar that accurately reflects the desired language without ambiguity introduced by empty transitions. Then, we translate this epsilon-free grammar into a finite automata, capturing the language's structure in a format compatible with finite state machines.
