- Automata Theory - Applications
- Automata Terminology
- Basics of String in Automata
- Set Theory for Automata
- Finite Sets and Infinite Sets
- Algebraic Operations on Sets
- Relations Sets in Automata Theory
- Graph and Tree in Automata Theory
- Transition Table in Automata
- What is Queue Automata?
- Compound Finite Automata
- Complementation Process in DFA
- Closure Properties in Automata
- Concatenation Process in DFA
- Language and Grammars
- Language and Grammar
- Grammars in Theory of Computation
- Language Generated by a Grammar
- Chomsky Classification of Grammars
- Context-Sensitive Languages
- Finite Automata
- What is Finite Automata?
- Finite Automata Types
- Applications of Finite Automata
- Limitations of Finite Automata
- Two-way Deterministic Finite Automata
- Deterministic Finite Automaton (DFA)
- Non-deterministic Finite Automaton (NFA)
- NDFA to DFA Conversion
- Equivalence of NFA and DFA
- Dead State in Finite Automata
- Minimization of DFA
- Automata Moore Machine
- Automata Mealy Machine
- Moore vs Mealy Machines
- Moore to Mealy Machine
- Mealy to Moore Machine
- Myhill–Nerode Theorem
- Mealy Machine for 1’s Complement
- Finite Automata Exercises
- Complement of DFA
- Regular Expressions
- Regular Expression in Automata
- Regular Expression Identities
- Applications of Regular Expression
- Regular Expressions vs Regular Grammar
- Kleene Closure in Automata
- Arden’s Theorem in Automata
- Convert Regular Expression to Finite Automata
- Conversion of Regular Expression to DFA
- Equivalence of Two Finite Automata
- Equivalence of Two Regular Expressions
- Convert Regular Expression to Regular Grammar
- Convert Regular Grammar to Finite Automata
- Pumping Lemma in Theory of Computation
- Pumping Lemma for Regular Grammar
- Pumping Lemma for Regular Expression
- Pumping Lemma for Regular Languages
- Applications of Pumping Lemma
- Closure Properties of Regular Set
- Closure Properties of Regular Language
- Decision Problems for Regular Languages
- Decision Problems for Automata and Grammars
- Conversion of Epsilon-NFA to DFA
- Regular Sets in Theory of Computation
- Context-Free Grammars
- Context-Free Grammars (CFG)
- Derivation Tree
- Parse Tree
- Ambiguity in Context-Free Grammar
- CFG vs Regular Grammar
- Applications of Context-Free Grammar
- Left Recursion and Left Factoring
- Closure Properties of Context Free Languages
- Simplifying Context Free Grammars
- Removal of Useless Symbols in CFG
- Removal Unit Production in CFG
- Removal of Null Productions in CFG
- Linear Grammar
- Chomsky Normal Form (CNF)
- Greibach Normal Form (GNF)
- Pumping Lemma for Context-Free Grammars
- Decision Problems of CFG
- Pushdown Automata
- Pushdown Automata (PDA)
- Pushdown Automata Acceptance
- Deterministic Pushdown Automata
- Non-deterministic Pushdown Automata
- Construction of PDA from CFG
- CFG Equivalent to PDA Conversion
- Pushdown Automata Graphical Notation
- Pushdown Automata and Parsing
- Two-stack Pushdown Automata
- Turing Machines
- Basics of Turing Machine (TM)
- Representation of Turing Machine
- Examples of Turing Machine
- Turing Machine Accepted Languages
- Variations of Turing Machine
- Multi-tape Turing Machine
- Multi-head Turing Machine
- Multitrack Turing Machine
- Non-Deterministic Turing Machine
- Semi-Infinite Tape Turing Machine
- K-dimensional Turing Machine
- Enumerator Turing Machine
- Universal Turing Machine
- Restricted Turing Machine
- Convert Regular Expression to Turing Machine
- Two-stack PDA and Turing Machine
- Turing Machine as Integer Function
- Post–Turing Machine
- Turing Machine for Addition
- Turing Machine for Copying Data
- Turing Machine as Comparator
- Turing Machine for Multiplication
- Turing Machine for Subtraction
- Modifications to Standard Turing Machine
- Linear-Bounded Automata (LBA)
- Church's Thesis for Turing Machine
- Recursively Enumerable Language
- Computability & Undecidability
- Turing Language Decidability
- Undecidable Languages
- Turing Machine and Grammar
- Kuroda Normal Form
- Converting Grammar to Kuroda Normal Form
- Decidability
- Undecidability
- Reducibility
- Halting Problem
- Turing Machine Halting Problem
- Rice's Theorem in Theory of Computation
- Post’s Correspondence Problem (PCP)
- Types of Functions
- Recursive Functions
- Injective Functions
- Surjective Function
- Bijective Function
- Partial Recursive Function
- Total Recursive Function
- Primitive Recursive Function
- μ Recursive Function
- Ackermann’s Function
- Russell’s Paradox
- Gödel Numbering
- Recursive Enumerations
- Kleene's Theorem
- Kleene's Recursion Theorem
- Advanced Concepts
- Matrix Grammars
- Probabilistic Finite Automata
- Cellular Automata
- Reduction of CFG
- Reduction Theorem
- Regular expression to ∈-NFA
- Quotient Operation
- Parikh’s Theorem
- Ladner’s Theorem
Parse Tree in Automata Theory
Parsing is an important part in context of automata and compiler design perspective. Parsing refers to the process of analyzing a string of symbols, either in natural language or programming language, according to the rules of a formal grammar. This is done by the concept called parser, which determines if a given string belongs to a language defined by a specific grammar.
The parser often generates a graphical representation of the derivation process. In this chapter, we will explain the concept of parsing and parse trees through examples.
Basics of Context-Free Grammar (CFG)
Before getting the idea of parse trees, it is essential to understand Context-Free Grammar (CFG). A CFG consists of a set of production rules that describe all possible strings in a given formal language. These production rules define how the symbols in the language can be combined and transformed to generate valid strings.
A Context-Free Grammar $\mathrm{G}$ is defined by four components −
- $\mathrm{V}$: A finite set of variables (non-terminal symbols).
- $\mathrm{T}$: A finite set of terminal symbols.
- $\mathrm{S}$: A start symbol, which is a special non-terminal symbol from $\mathrm{V}$.
- $\mathrm{P}$: A finite set of production rules, each having a form $\mathrm{A \rightarrow \alpha A}$, where $\mathrm{A}$ is a non-terminal and $\mathrm{\alpha}$ is a string consisting of terminals and/or non-terminals.
Parse Trees and Their Role in Parsing
A parse tree, also known as derivation tree is a graphical representation of the derivation of a string according to the production rules of a CFG. It shows how a start symbol of a CFG can be transformed into a terminal string, using applying production rules in a sequence.
Each node in a parse tree represents a symbol of the grammar, while the edges represent the application of production rules.
- Tree Nodes − The nodes in a parse tree represent either terminal or non-terminal symbols of the grammar.
- Tree Edges − The edges represent the application of production rules leading from one node to another.
Types of Parsers
Parsers can be broadly categorized into two types based on how they construct the parse tree −
- Top-down Parsers − These parsers build the parse tree starting from the root and proceed towards the leaves. They typically perform a leftmost derivation. They expand the leftmost non-terminal at each step.
- Bottom-up Parsers − These parsers start from the leaves and move towards the root, performing a rightmost derivation in reverse order.
Example of Parse Tree Construction
Let us consider an example of a parse tree construction using a simple grammar −
Given grammar $\mathrm{G}$ −
$$\mathrm{E \:\rightarrow \: E \:+\:E \:| \:E\: \times \:E\:|(E)|\:|\:-\:E|\:id}$$
Deriving the String "-(id + id)"
To determine whether the string "-(id + id)" is a valid sentence in this grammar, we can construct a parse tree as follows −
- Start with $\mathrm{E}$.
- Apply the production $\mathrm{E \:\rightarrow \:-\: EE}$ to get the intermediate string "\mathrm{- E}".
- Apply $\mathrm{E \:\rightarrow\: (E)}$ to derive "$\mathrm{-(E)}$".
- Apply $\mathrm{E \:\rightarrow\: E \:+\: E}$ to derive "$\mathrm{-(E \:+\: E)}$".
- Finally, apply $\mathrm{E \:\rightarrow\: id}$ to get the final string "$\mathrm{-(id \:+\: id)}$".
Here is the corresponding parse tree −
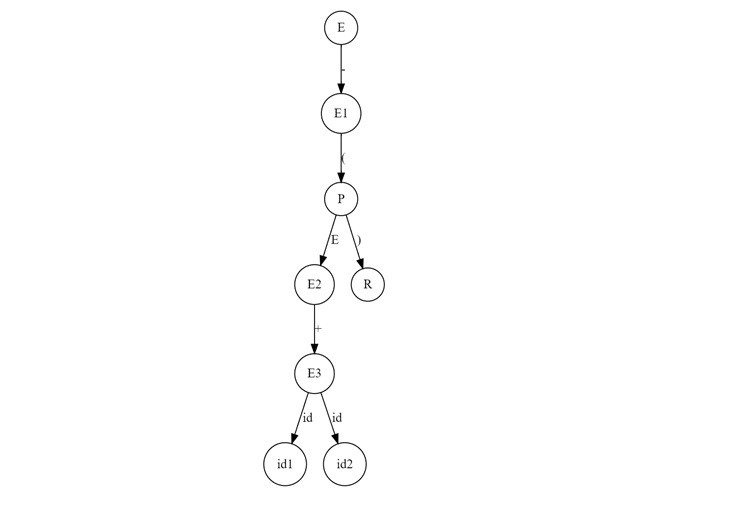
This representation shows the hierarchical structure of the derivation, with the root representing the start symbol and the leaves representing the terminal symbols of the string.
Another Example of Parse Tree
Consider a different grammar for a second example −
Given grammar $\mathrm{G}$
$$\mathrm{S \:\rightarrow\: SS\: |\: aSb\: |\: \varepsilon}$$
To derive the string "aabb", we proceed as follows −
- Start with $\mathrm{S}$.
- Apply $\mathrm{S \:\rightarrow\: aSb}$ to get "$\mathrm{aSb}$".
- Apply $\mathrm{S \:\rightarrow\: asb}$ again within the non-terminal $\mathrm{S}$ to derive "$\mathrm{aaSbb}$".
- Finally, apply $\mathrm{S \:\rightarrow\: \varepsilon}$ to replace the last $\mathrm{S}$, resulting in "$\mathrm{aabb}$".
The corresponding parse tree can be represented like below −
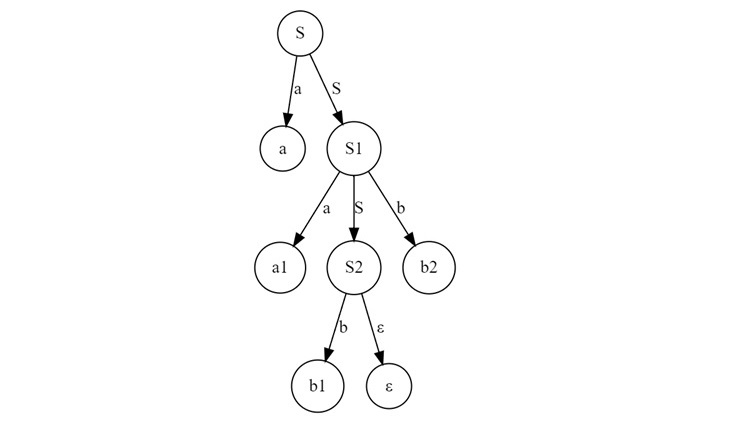
Ambiguity in Parse Trees
A grammar is said to be ambiguous if there exists at least one string that can be derived in more than one way. So there are multiple distinct parse trees. Ambiguity poses challenges when parsing as it can lead to multiple interpretations of the same string.
For instance, consider the following grammar −
$$\mathrm{S \:\rightarrow\:S \:+\: S\:|\:S\:\times\:S\:|\:id}$$
The string "id + id × id" can have two different parse trees depending on the order of operations −
First Parse Tree

Second Parse Tree

Conclusion
Parse trees are a basic concept in Theory of Computation and Compiler Design. Parse trees are used to parse context-free languages. They provide a visual representation of how a string is derived from the grammars start symbol. It offers an insight into the structure and hierarchy of the language.
