- SAP BO Data Services
- SAP BODS - Overview
- SAP BODS - Architecture
- SAP BODS - Data Services Designer
- SAP BODS Repository
- SAP BODS - Repository Overview
- Repository Creating & Updating
- Data Services Management Console
- SAP BODS - DSMC Modules
- SAP BODS - DS Designer Introduction
- SAP BODS - ETL Flow in DS Designer
- SAP BODS Datastores & Formats
- SAP BODS - Datastore Overview
- SAP BODS - Changing a Datastore
- SAP BODS - Memory Datastore
- SAP BODS - Linked Datastore
- SAP BODS - Adapter Datastore
- SAP BODS - File Formats
- COBOL Copybook File Format
- Extracting Data from DB Tables
- Data Extraction from Excel Workbook
- Data Flow & Work Flow
- SAP BODS - Dataflow Introduction
- BODS - Dataflow Changing Properties
- SAP BODS - Workflow Introduction
- SAP BODS - Creating Workflows
- SAP BODS Transforms
- SAP BODS - Transforms Types
- Adding Transform to a Dataflow
- SAP BODS - Query Transform
- SAP BODS Administration
- SAP BODS - Data Services Overview
- Creating Embedded Dataflow
- Debugging & Recovery Mechanism
- Data Assessment & Data Profiling
- SAP BODS - Tuning Techniques
- Multi-user Development
- BODS - Central vs Local Repository
- BODS - Central Repository Security
- Creating a Multi-user Environment
- SAP BODS Useful Resources
- SAP BODS - Questions Answers
- SAP BODS - Quick Guide
- SAP BODS - Useful Resources
- SAP BODS - Discussion
SAP BODS - Query Transform
This is the most common transformation used in Data Services and you can perform the following functions −
- Data filtering from sources
- Joining data from multiple sources
- Perform functions and transformations on data
- Column mapping from input to output schemas
- Assigning Primary keys
- Add new columns, schemas and functions resulted to output schemas
As Query transformation is the most commonly used transformation, a shortcut is provided for this query in the tool palette.
To add Query transform, follow the steps given below −
Step 1 − Click the query-transformation tool palette. Click anywhere on the Data flow workspace. Connect this to the inputs and outputs.

When you double click the Query transform icon, it opens a Query editor that is used to perform query operations.
The following areas are present in Query transform −
- Input Schema
- Output Schema
- Parameters
The Input and Output schemas contain Columns, Nested Schemas and Functions. Schema In and Schema Out shows the currently selected schema in transformation.
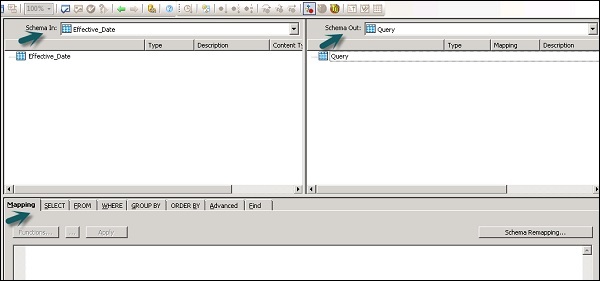
To change the output schema, select the schema in the list, right click and select Make Current.
Data Quality Transform
Data Quality Transformations cannot be directly connected to the upstream transform, which contains nested tables. To connect these transform you should add a query transform or XML pipeline transform between transformation from nested table and data quality transform.
How to use Data Quality Transformation?
Step 1 − Go to Object Library → Transform tab
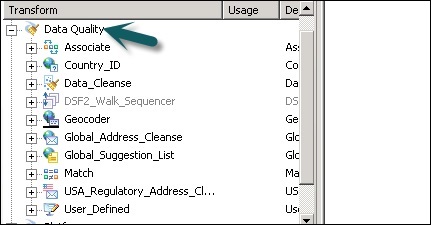
Step 2 − Expand the Data Quality transform and add the transform or transform configuration you want to add to data flow.
Step 3 − Draw the data flow connections. Double click the name of the transform, it opens the transform editor. In input schema, select the input fields that you want to map.
Note − To use Associate Transform, you can add user defined fields to input tab.
Text Data Processing Transform
Text Data Processing Transform allows you to extract the specific information from large volume of text. You can search for facts and entities like customer, product, and financial facts, specific to an organization.
This transform also checks the relationship between entities and allows the extraction. The data extracted, using text data processing, can be used in Business Intelligence, Reporting, query, and analytics.
Entity Extraction Transform
In Data Services, text data processing is done with the help of Entity Extraction, which extracts entities and facts from unstructured data.
This involves analyzing and processing large volume of text data, searching entities, assigning them to appropriate type and presenting metadata in standard format.
The Entity Extraction transform can extract information from any text, HTML, XML, or certain binary-format (such as PDF) content and generate structured output. You can use the output in several ways based on your work flow. You can use it as an input to another transform or write to multiple output sources such as a database table or a flat file. The output is generated in UTF-16 encoding.
Entity Extract Transform can be used in the following scenarios −
Finding a specific information from large amount of text volume.
Finding structured information from unstructured text with existing information to make new connections.
Reporting and analysis for product quality.
Differences between TDP and Data Cleansing
Text data processing is used for finding relevant information from unstructured text data. However, data cleansing is used for standardization and cleansing structured data.
| Parameters | Text Data Processing | Data Cleansing |
|---|---|---|
| Input Type | Unstructured Data | Structured Data |
| Input Size | More than 5KB | Less than 5KB |
| Input Scope | Broad domain with many variations | Limited variations |
| Potential Usage | Potential meaningful information from unstructured data | Quality of data for storing in to Repository |
| Output | Create annotations in form of entities, type, etc. Input is not changed | Create standardized fields, Input is changed |
