- SAP BO Data Services
- SAP BODS - Overview
- SAP BODS - Architecture
- SAP BODS - Data Services Designer
- SAP BODS Repository
- SAP BODS - Repository Overview
- Repository Creating & Updating
- Data Services Management Console
- SAP BODS - DSMC Modules
- SAP BODS - DS Designer Introduction
- SAP BODS - ETL Flow in DS Designer
- SAP BODS Datastores & Formats
- SAP BODS - Datastore Overview
- SAP BODS - Changing a Datastore
- SAP BODS - Memory Datastore
- SAP BODS - Linked Datastore
- SAP BODS - Adapter Datastore
- SAP BODS - File Formats
- COBOL Copybook File Format
- Extracting Data from DB Tables
- Data Extraction from Excel Workbook
- Data Flow & Work Flow
- SAP BODS - Dataflow Introduction
- BODS - Dataflow Changing Properties
- SAP BODS - Workflow Introduction
- SAP BODS - Creating Workflows
- SAP BODS Transforms
- SAP BODS - Transforms Types
- Adding Transform to a Dataflow
- SAP BODS - Query Transform
- SAP BODS Administration
- SAP BODS - Data Services Overview
- Creating Embedded Dataflow
- Debugging & Recovery Mechanism
- Data Assessment & Data Profiling
- SAP BODS - Tuning Techniques
- Multi-user Development
- BODS - Central vs Local Repository
- BODS - Central Repository Security
- Creating a Multi-user Environment
- SAP BODS Useful Resources
- SAP BODS - Questions Answers
- SAP BODS - Quick Guide
- SAP BODS - Useful Resources
- SAP BODS - Discussion
SAP BODS Interview Questions
Dear readers, these SAP BODS Interview Questions have been designed specially to get you acquainted with the nature of questions you may encounter during your interview for the subject of SAP BODS. As per my experience good interviewers hardly plan to ask any particular question during your interview, normally questions start with some basic concept of the subject and later they continue based on further discussion and what you answer:
Indexes − OLTP system has only few indexes while in an OLAP system there are many indexes for performance optimization.
Joins − In an OLTP system, large number of joins and data is normalized however in an OLAP system there are less joins and de-normalized.
Aggregation − In an OLTP system data is not aggregated while in an OLAP database more aggregations are used.
There is a staging area that is required during ETL load. There are various reasons why a staging area is required −
As source systems are only available for specific period of time to extract data and this time is less than total data load time so Staging area allows you to extract the data from source system and keep it in staging area before time slot is ended.
Staging area is required when you want to get data from multiple data sources together. If you want to join two or more systems together. Example- You will not be able to perform a SQL query joining two tables from two physically different databases.
Data extractions time slot for different systems vary as per the time zone and operational hours.
Data extracted from source systems can be used in multiple data warehouse system, Operation Data stores, etc.
During ETL you can perform complex transformations that allows you to perform complex transformations and require extra area to store the data.
SAP BO Data Services is an ETL tool used for Data integration, data quality, data profiling and data processing and allows you to integrate, transform trusted data to data warehouse system for analytical reporting.
BO Data Services consists of a UI development interface, metadata repository, data connectivity to source and target system and management console for scheduling of jobs.
You can also divide BODS architecture in below layers −
Web Application Layer, Database Server Layer, Data Services Service Layer.
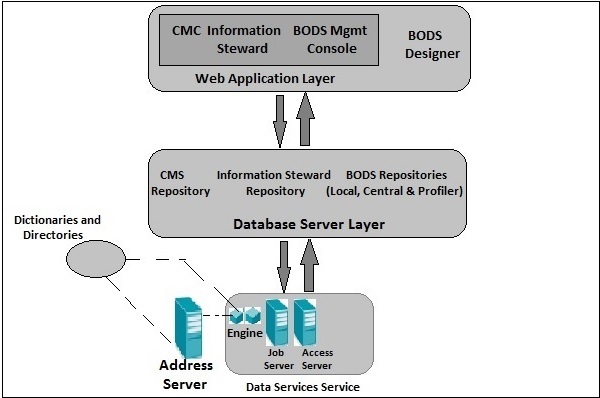
Repository is used to store meta-data of objects used in BO Data Services. Each Repository should be registered in Central Management Console CMC and is linked with single or many job servers which is responsible to execute jobs that are created by you.
There are three types of Repositories −
Local Repository −
It is used to store the metadata of all objects created in Data Services Designer like project, jobs, data flow, work flow, etc.
Central Repository −
It is used to control the version management of the objects and is used for multiuse development. Central Repository stores all the versions of an application object so it allows you to move to previous versions.
Profiler Repository −
This is used to manage all the metadata related to profiler tasks performed in SAP BODS designer. CMS Repository stores metadata of all the tasks performed in CMC on BI platform. Information Steward Repository stores all the metadata of profiling tasks and objects created in information steward.
Reusable Objects −
Most of the objects that are stored in repository can be reused. When a reusable objects is defined and save in the local repository, you can reuse the object by creating calls to the definition. Each reusable object has only one definition and all the calls to that object refer to that definition. Now if definition of an object is changed at one place you are changing object definition at all the places where that object appears.
An object library is used to contain object definition and when an object is drag and drop from library, it means a new reference to an existing object is created.
Single Use Objects −
All the objects that are defined specifically to a job or data flow, they are called single use objects. Example-specific transformation used in any data load.
Datastore are used to setup connection between an application and database. You can directly create Datastore or can be created with help of adapters. Datastore allows an application/software to read or write metadata from an application or database and to write to that database or application.
To create BODS Repository you need a database installed. You can use SQL Server, Oracle database, My SQL, SAP HANA, Sybase, etc. You have to create below users in database while installing BODS and to create Repositories. These users are required to login to different servers CMS Server, Audit Server. To create a new repository, you have to login to Repository manager.
Real-time jobs "extract" data from the body of the real time message received and from any secondary sources used in the job.
Central repository is used to control the version management of the objects and is used for multiuse development. Central Repository stores all the versions of an application object so it allows you to move to previous versions.
Data Services Management Console
In Data Services, you can create a template table to move to target system that has same structure and data type as source table.
DS Management Console → Job Execution History
It is a developer tool which is used to create objects consist of data mapping, transformation, and logic. It is GUI based and work as designer for Data Services.
You can create various objects using Data Services Designer like Project, Jobs, Work Flow, Data Flow, mapping, transformations, etc.
In Object library in DS Designer
You can create Datastore using memory as database type. Memory Datastore are used to improve the performance of data flows in real time jobs as it stores the data in memory to facilitate quick access and doesnt require to go to original data source.
A memory Datastore is used to store memory table schemas in the repository. These memory tables get data from tables in Relational database or using hierarchical data files like XML message and IDocs.
The memory tables remain alive till job executes and data in memory tables cant be shared between different real time jobs.
There are various database vendors which only provides one way communication path from one database to another database. These paths are known as database links. In SQL Server, Linked server allows one way communication path from one database to other.
Example −
Consider a local database Server name Product stores database link to access information on remote database server called Customer. Now users that are connected to remote database server Customer cant use the same link to access data in database server Product. User that are connected to Customer should have a separate link in data dictionary of the server to access the data in Product database server.
This communication path between two databases are called database link and Datastores which are created between these linked database relationships is known as linked Datastores.
There is a possibility to connect Datastore to another Datastore and importing an external database link as option of Datastore.
Adapter Datastore allows you to import application metadata into repository. You can also access application metadata and you can also move batch and real time data between different applications and software.
- Delimited
- SAP Transport
- Unstructured Text
- Unstructured Binary
- Fixed Width
You can use Microsoft Excel workbook as data source using file formats in Data Services. Excel work book should be available on Windows file system or Unix File system.
Data flow is used to extract, transform and load data from source to target system. All the transformations, loading and formatting occurs in dataflow.
- Source
- Target
- Transforms
- Execute once
- Parallelism
- Database links
- Cache
Workflows are used to determine the process for executing the workflows. Main purpose of workflow is to prepare for executing the data flows and to set the state of system once data flow execution is completed.
- Work flow
- Data flow
- Scripts
- Loops
- Conditions
- Try or Catch Blocks
Yes
There is a fact table that you want to update and you have created a data flow with the transformation. Now If you want to move the data from source system, you have to check last modification for fact table so that you extract only rows that has been added after last update.
In order to achieve this, you have to create one script which determines last update date and then pass this as input parameter to data flow.
You also have to check if data connection to a particular fact table is active or not. If it is not active, you need to setup a catch block which automatically sends an email to administrator to notify about this problem.
You can also add Conditionals to workflow. This allows you to implement If/Else/Then logic on the workflows.
Transforms are used to manipulate data sets as inputs and creating one or multiple outputs. There are various transforms that can be used in Data Services.
- Data Integration
- Data Quality
- Platform
- Merge
- Query
- Text data processing
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Table_Comparision, etc.
This is most common transformation used in Data Services and you can perform below functions −
Data filtering from sources
Joining data from multiple sources
Perform functions and transformations on data
Column mapping from input to output schemas
Assigning Primary keys
Add new columns, schemas and functions resulted to output schemas
As Query transformation is most commonly used transformation, so a shortcut is provided for this query in tool palette.
This allows you to extract the specific information from large volume of text. You can search for facts and entities like customer, product, and financial facts specific to an organization.
This transform also checks the relationship between entities and allows the extraction.
The data extracted using text data processing can be used in Business Intelligence, Reporting, query, and analytics.
Text data processing is used for finding relevant information from unstructured text data however data cleansing is used for standardization and cleansing structured data.
You can create real time jobs to process real time messages in Data Services designer. Like a batch job, real time job extracts the data, transform and load it.
Each real time job can extract data from a single message or you can also extract data from other sources like tables or files.
Transform like branches and control logic are used more often in real time job unlike the batch jobs in designer.
Real time jobs are not executed in response of a schedule or internal trigger unlike the batch jobs.
Embedded data flow is known as data flows which are called from another data flow in the design. The embedded data flow can contain multiple number of source and targets but only one input or output pass data to main data flow.
One Input − Embedded data flow is added at the end of dataflow.
One Output − Embedded data flow is added at the beginning of a data flow.
No input or output − Replicate an existing data flow.
Local variables in data services are restricted to object in which they are created.
Global variables are restricted to jobs in which they are created. Using global variables, you can change values for default global variables at run time.
Expressions that are used in work flow and data flow they are called parameters.
All the variables and parameters in work flow and data flows are shown in variable and parameters window.
Automatic Recovery - This allows you to run unsuccessful jobs in recovery mode.
Manually Recovery - This allows you to rerun the jobs without considering partial rerun previous time.
Data Services Designer provides a feature of Data Profiling to ensure and improve the quality and structure of source data. Data Profiler allows you to −
Find anomalies in source data, validation and corrective action and quality of source data.
The structure and relationship of source data for better execution of jobs, work flows and data flows.
The content of source and target system to determine that your job returns the result as expected.
The performance of an ETL job depends on the system on which you are using Data Services software, number of moves, etc. There are various other factors that contributes to the performance in an ETL task −
- Source Data Base
- Source Operating System
- Target Database
- Target Operating System
- Network
- Job Server OS
- BODs Repository Database
SAP BO Data Services support multi user development where each user can work on application in their own local repository. Each team uses central repository to save main copy of an application and all the versions of objects in the application.
In SAP Data Services, job migration can be applied at different levels- Application Level, Repository Level, Upgrade level.
To copy the content of one central repository to other central repository, you cant do it directly and you need to make use of local repository.
First is to get the latest version of all objects from central repository to local repository. Activate the central repository in which you want to copy the contents.
Add all the objects you want to copy from local repository to central repository.
If you update version of SAP Data Services, there is a need to update version of Repository. Below points should be considered when migrating a central repository to upgrade version −
Point 1
Take the backup of central repository all tables and objects.
Point 2
To maintain version of objects in data services, maintain a central repository for each version. Create a new central history with new version of Data Services software and copy all objects to this repository.
Point 3
It is always recommended if you install new version of Data Services, you should upgrade your central repository to new version of objects.
Point 4
Also upgrade your local repository to same version as different version of central and local repository may not work at the same time.
Point 5
Before migrating the central repository, check in all the objects. As you dont upgrade central and local repository simultaneously, so there is a need to check in all the objects. As once you have your central repository upgraded to new version, you will not be able to check in objects from local repository which is having older version of Data Services.
SCDs are dimensions that have data that changes over time.
SCD Type 1 No history preservation
Natural consequence of normalization
SCD Type 2 Preserving all history and new rows
There are new rows generated for significant changes
You need to use of a unique key
There are new fields are generated to store history data
You need to manage an Effective_Date field.
SCD Type 3 Limited history preservation
In this only two states of data are preserved - current and old
No, File format is not a datastore type.
What is Next ?
Further you can go through your past assignments you have done with the subject and make sure you are able to speak confidently on them. If you are fresher then interviewer does not expect you will answer very complex questions, rather you have to make your basics concepts very strong.
Second it really doesn't matter much if you could not answer few questions but it matters that whatever you answered, you must have answered with confidence. So just feel confident during your interview. We at tutorialspoint wish you best luck to have a good interviewer and all the very best for your future endeavor. Cheers :-)
