
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is design space of register renaming in computer architecture?
The design space of register renaming resembles that of shelving. As shown in the figure, it consists of the following main components such as the scope of register renaming, the layout of rename buffers, the operand fetch policy, and the number of renames per cycle.
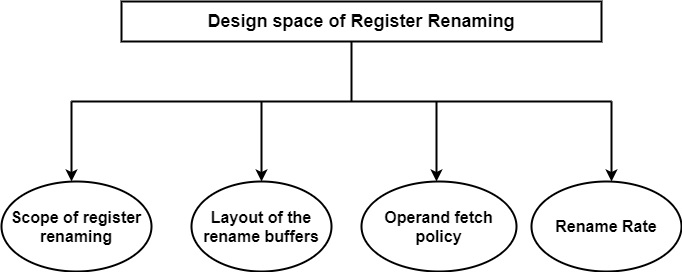
- Scope of Register Renaming
Most first-generation superscalar processors, like the PA 7100, Supersparc, α21064, R8000, Pentium, and others did not employ renaming. In partial renaming, it is restricted to a particular instruction type or a few types. Examples are the Power1 (RS6000), Power2, and Nx586.
- Layout of the rename buffers
The layout of the rename buffers creates the real framework for renaming. There are three basic components are the type and the number of the rename buffers and the basic mechanism which is used for accessing rename buffers.
Type of rename buffers
The chosen type of rename buffers has the largest impact on renaming. It is definitive for the basic approach of the implementation and thus it determines where the intermediate results of the instruction are to be written into or read form.
Number of rename buffers
The following table shows an overview of how many rename buffers are provided by recent processors. Each of the three sections of the table covers a different implementation type. In the first section, we list processors that use a merged register file for architectural and rename registers. In these processors, it can find quite a large number of additional registers which can be used for renaming. The number of rename buffers ranges from 8 in the Power1, up to 32 in the R10000, and even 38 in the 64-bit Sparc-processor PM1 (Sparc64).
Number of rename buffers provided
| Implementation of renaming | Number of rename buffers | |
|---|---|---|
| Processor type | FX | FP |
| Merged rename and arch. Register file | ||
| Power1 (1990) | 8 (32 arch. + 8 rename) |
|
| Power2 (1993) | 22 (32 arch. + 22 rename) |
|
| ES/9000 (1992p) | 16 (16 arch. + 16 ren.) |
12 (4 arch. + 12 rename) |
| PM1 (1995) | 38 (78 arch. + 38 ren.) |
24 (32 arch. + 24 rename) |
| R10000 (1996) | 32 (32 arch. + 32 ren.) |
32 (32 arch. + 32 rename) |
| Separate rename register file | ||
| PowerPC 603 (1993) | n.a. | 4 |
| PowerPC 604 (1995) | 12 | 8 |
| PowerPC 620 (1996) | 8 | 8 |
| Renaming within the ROB | ||
| Am29000 sup (1995) | 10 | |
| K5 (1995) | 16 | |
| PentiumPro (1995) | 40 | |
Operand fetch policies − There are two possible policies such as fetch operands during instruction issue and store instructions along with their operands in the shelving buffers (issue bound fetch) or shelve instructions without their operands and delay fetching the operands until the instructions are dispatched from the shelving buffer (dispatch bound fetch).
Rename Rate − The rename rate is the maximum number of renames per cycle that a processor can perform. It can avoid bottlenecks the rename rate usually equals the issue rate. Recent processors can issue up to four FX or FP instructions or any mix of the two.

704 Views
