
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is design space of Arbiter Logics in computer architecture?
Arbiter logic plays a crucial act in the implementation of pended and split-transaction buses. These are the so-called 1 of N arbiters since they grant the requested resource only to one of the requesters. The design space of arbiter logic is very rich. There are two ways to organize the arbitration logic according to the distribution of its components in the multiprocessor system −
- Centralized arbiter
- Decentralized arbiter
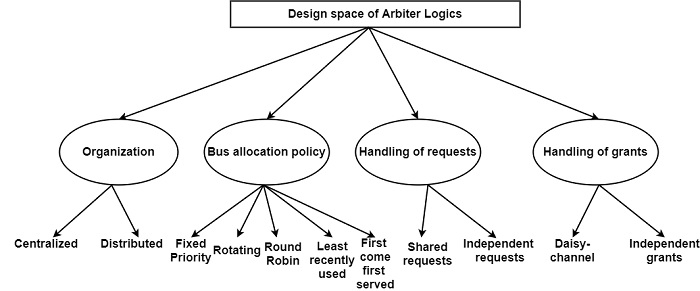
The implementation of the fixed priority policy is very simple but it cannot provide a fair allocation of the bus. The highest priority can be dynamically changed in the rotating priority scheme, providing a fair bus allocation strategy but with the increased hardware complexity.
In the round-robin arbiter policy, fixed-length slices of bus times are allocated and sequentially to each bus master in a round-robin fashion. In the least recently used policy, the bus master that has not used the bus for the longest time receives the highest priority at every bus cycle. Both schemes provide good load balancing but the latter requires less waiting time than the former. In the first come first served scheme, the bus is granted in the order of requests. This approach provides the best performance but it requires the most complicated hardware to implement.
The centralized arbiter with independent request and grant lines has two major advantages are as follows −
It can realize any bus allocation policy.
It has a faster arbitration time compared with daisy-chained arbiters.
One of the most popular organizations of arbiter logic is daisy-chaining. There is only one shared bus request line in the daisy-chained bus arbitration scheme. All the masters use this line to indicate their need to access the shared bus.
The arbiter passes the bus grant line to the first master and then it is passed from master to master, creating a chain of the master. The priority of a master is decided by its position in the grant chain. The closer is to the arbiter, its higher the priority.
The implementation of the daisy-chained arbitration scheme is very cost-effective. Adding a new processor module does not require any extension of the existing bus exchange lines. The main drawback of this scheme is the relatively slow propagation of the grant signal on the grant chain line. There is another disadvantage is the deficiency of fairness in the allocation scheme.
It can eliminate this drawback a modified version, called the rotating arbiter, can be employed in shared bus multiprocessors. The priority loop of the rotating arbiter works similarly to the grant chain of the daisy-chained arbiter.
Arbiter is allowed to grant its coupled master unit if the master has activated its bus request line, the bus busy line is passive and the priority input line is active. If the master has not activated its bus request line, the arbiter activates its output priority line.

1K+ Views
