- DBMS - Home
- DBMS - Overview
- DBMS - Architecture
- DBMS - Data Models
- DBMS - Data Schemas
- DBMS - Data Independence
- DBMS - System Environment
- Centralized and Client/Server Architecture
- DBMS - Classification
- Relational Model
- DBMS - Codd's Rules
- DBMS - Relational Data Model
- DBMS - Relational Model Constraints
- DBMS - Relational Database Schemas
- DBMS - Handling Constraint Violations
- Entity Relationship Model
- DBMS - ER Model Basic Concepts
- DBMS - ER Diagram Representation
- Relationship Types and Relationship Sets
- DBMS - Weak Entity Types
- DBMS - Generalization, Aggregation
- DBMS - Drawing an ER Diagram
- DBMS - Enhanced ER Model
- Subclass, Superclass and Inheritance in EER
- Specialization and Generalization in Extended ER Model
- Data Abstraction and Knowledge Representation
- Relational Algebra
- DBMS - Relational Algebra
- Unary Relational Operation
- Set Theory Operations
- DBMS - Database Joins
- DBMS - Division Operation
- DBMS - ER to Relational Model
- Examples of Query in Relational Algebra
- Relational Calculus
- Tuple Relational Calculus
- Domain Relational Calculus
- Relational Database Design
- DBMS - Functional Dependency
- DBMS - Inference Rules
- DBMS - Minimal Cover
- Equivalence of Functional Dependency
- Finding Attribute Closure and Candidate Keys
- Relational Database Design
- DBMS - Keys
- Super keys and candidate keys
- DBMS - Foreign Key
- Finding Candidate Keys
- Normalization in Database Designing
- Database Normalization
- First Normal Form
- Second Normal Form
- Third Normal Form
- Boyce Codd Normal Form
- Difference Between 4NF and 5NF
- Structured Query Language
- Types of Languages in SQL
- Querying in SQL
- CRUD Operations in SQL
- Aggregation Function in SQL
- Join and Subquery in SQL
- Views in SQL
- Trigger and Schema Modification
- Storage and File Structure
- DBMS - Storage System
- DBMS - File Structure
- DBMS - Secondary Storage Devices
- DBMS - Buffer and Disk Blocks
- DBMS - Placing File Records on Disk
- DBMS - Ordered and Unordered Records
- Indexing and Hashing
- DBMS - Indexing
- DBMS - Single-Level Ordered Indexing
- DBMS - Multi-level Indexing
- Dynamic B- Tree and B+ Tree
- DBMS - Hashing
- Query Processing and Optimization
- Heuristics in Query Processing
- Transaction and Concurrency
- DBMS - Transaction
- DBMS - Scheduling Transactions
- DBMS - Testing Serializability
- DBMS - Conflict Serializability
- DBMS - View Serializability
- DBMS - Concurrency Control
- DBMS - Lock Based Protocol
- DBMS - Timestamping based Protocol
- DBMS - Phantom Read Problem
- DBMS - Dirty Read Problem
- DBMS - Thomas Write Rule
- DBMS - Deadlock
- Backup and Recovery
- DBMS - Data Backup
- DBMS - Data Recovery
- DBMS Useful Resources
- DBMS - Quick Guide
- DBMS - Useful Resources
- DBMS - Discussion
DBMS - Single-Level Ordered Indexing
Single-level ordered indexing is a simple yet powerful method to speed up the searching process while fetching data from a database. This is like the index of a book to quickly find the page number where a term is described. Instead of reading through every single page, single-level ordered indexing creates a structured index based on specific fields in a file to make searches faster and more reliable.
In this chapter, we will have an in-depth look at single-level ordered indexing, its types, and its workings. We will see a practical example to understand how indexing can reduce the number of disk accesses during database searches.
Basics of Single-Level Ordered Indexing
When a database file is unindexed, we will have to use linear search for retrieving a specific record. We need to scan all records one by one until the desired one is found. This approach is slow, when the databases are so large. Single-level ordered indexing addresses this problem by organizing records in an auxiliary file called the index file.
An index file contains two main components −
- Index Key − A field from the original file (e.g., a name or ID) that is used to organize and locate data.
- Pointer − A reference to the location of the record in the original file.
The values in the index are stored in a specific order, so we can use efficient searching algorithms like the binary search. Since the index file is much smaller than the original data file, searches are faster.
Types of Single-Level Ordered Indexes
Depending on how the data is organized and what field is indexed, different types of indexes can be created, such as −
- Primary index
- Clustering index
- Secondary index
Let's discuss these indexes one by one.
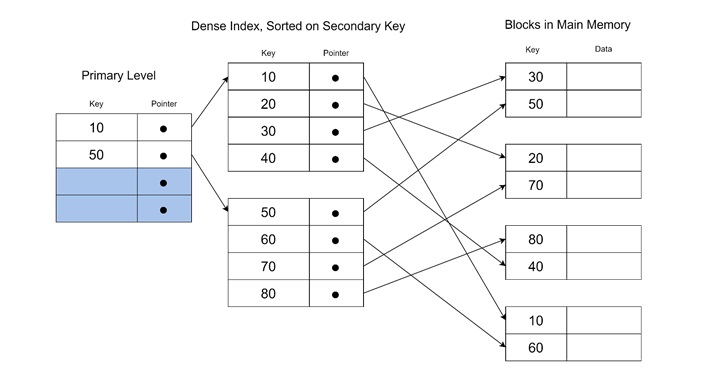
Primary Index
The primary index is built on the ordering key field of a file. This field is also called the primary key, which is used to physically sort the records in the data file. Each entry in the primary index represents the first record of a disk block. This is often called the block anchor.
The primary index is sparse, which means it contains fewer entries than the total number of records in the file. Each entry has two parts −
- Key value − The primary key value of the block anchor.
- Pointer − The address of the disk block containing the anchor.
Example of Primary Index
Let us consider a database file sorted by the "Name" field. The primary index may look like this −
- <K(1) = (Aaron, Ed), P(1)>
- <K(2) = (Adams, John), P(2)>
- <K(3) = (Alexander, Ed), P(3)>
In this example, each K(i) corresponds to the first record in block (i), and P(i) points to the block's location on the disk. This structure is useful and it is helps us perform binary searches on the index, which significantly reduces the time it takes to find a record.
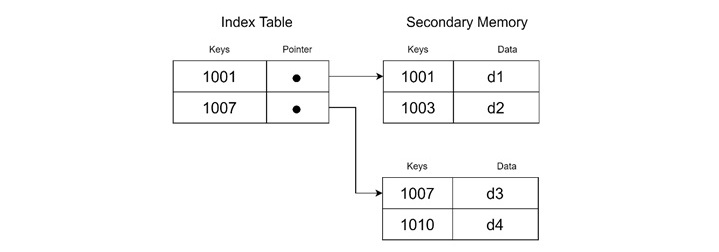
Clustering Index
The clustering index is used when records are ordered based on a non-key field. Unlike primary keys, the clustering fields can have duplicate values. The clustering index points to the first block containing records with the same clustering field value.
Example of Clustering Index
In an employee database, if records are organized by "Department Number," the clustering index might look like this −
- <K(1) = 1, P(1)> points to the block for Department 1.
- <K(2) = 2, P(2)> points to the block for Department 2.
This approach is also sparse because the clustering index contains entries for unique clustering field values rather than every record.
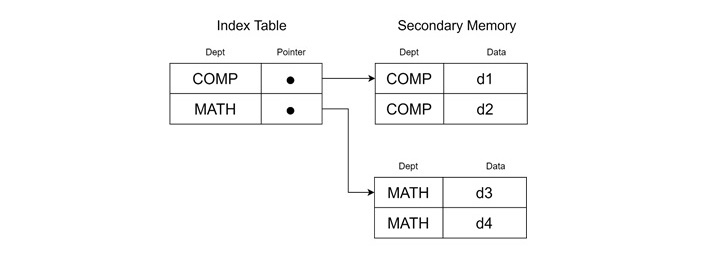
Secondary Index
The secondary index provides an alternative means of accessing records. This is created on a non-ordering field and can be dense or sparse. Dense secondary indexes contain one entry per record, which makes them larger but more precise.
Example of Secondary Index
Suppose a dense secondary index is built on the "Employee ID" field −
- <K(1) = 101, P(1)>
- <K(2) = 102, P(2)>
- <K(3) = 103, P(3)>
Secondary indexes are especially useful when the primary or clustering indexes do not meet a query's requirements.
A Detailed Example of Primary Indexing
Let us consider a detailed example for a primary index −
- Let's assume a database contains 30,000 records, each 100 bytes in size.
- The disk block size is 1,024 bytes, allowing 10 records per block (1024 ÷ 100 = 10).
- Therefore, the file requires 3,000 blocks (30,000 ÷ 10 = 3,000).
Searching without Indexing
If we perform a binary search directly on the data file, it would require about 12 block accesses (log2(3,000)).
Constructing the Primary Index
To improve search efficiency, we can make a primary index using the "Name" field. The steps are as follows −
Each index entry consists of −
- The "Name" field of the first record in each block.
- A pointer to the block's address.
The size of each index entry is 15 bytes (9 bytes for the Name and 6 bytes for the pointer).
- Each index block can hold 68 entries (1024 ÷ 15 = 68).
- Since the index contains 3,000 entries (one per block in the data file), it requires 45 blocks (3,000 ÷ 68 ≈ 45).
Searching with the Primary Index
To locate a specific record −
- Perform a binary search on the primary index, which will take about 6 block accesses (log2(45)).
- Once the relevant block is identified, retrieve it from the data file. This will require 1 additional block access.
Thus, a total of 7 block accesses are needed to find the record as compared to 12 without the index. This improvement demonstrates the efficiency of primary indexing.
Benefits of Using Single-Level Ordered Indexing
Following are the benefits of using single-level ordered indexing −
- Faster Data Retrieval − Binary search on a smaller index file is much faster than searching the entire data file.
- Space Efficiency − Sparse indexes, like primary and clustering indexes, use less storage space.
- Flexibility − Secondary indexes provide additional access paths without altering the physical organization of the data.
- Reduced I/O Operations − By minimizing the number of disk accesses, indexing improves system performance.
Limitations of Single-Level Ordered Indexing
Single-level ordered indexing has a set of limitations too, which are listed below −
- Insertion and Deletion − Adding a new record to a file requires maintaining the physical order. It may create shifting records, updating the index. Also, deleting a record can leave gaps, which complicates the indexing process.
- Overflow Blocks − When a block becomes full, overflow blocks or linked lists are used. These structures are effective, but they add complexity and may slow down retrieval.
- Storage Requirements − Dense indexes such as secondary indexes are good but they consume more storage due to the larger number of entries.
- Maintenance Overhead − Keeping the index file synchronized with the data file during updates adds extra processing time.
Conclusion
In this chapter, we covered the concept of single-level ordered indexing, its importance in database systems. We highlighted the three main types of single-level ordered indexing. Through a detailed example, we explained how a primary index could significantly reduce the number of block accesses during a search.
Single-level ordered indexing serves as a basic need of database management. However, careful planning is necessary to balance the benefits of faster retrieval with its inherent challenges of maintenance and storage.
