- DBMS - Home
- DBMS - Overview
- DBMS - Architecture
- DBMS - Data Models
- DBMS - Data Schemas
- DBMS - Data Independence
- DBMS - System Environment
- Centralized and Client/Server Architecture
- DBMS - Classification
- Relational Model
- DBMS - Codd's Rules
- DBMS - Relational Data Model
- DBMS - Relational Model Constraints
- DBMS - Relational Database Schemas
- DBMS - Handling Constraint Violations
- Entity Relationship Model
- DBMS - ER Model Basic Concepts
- DBMS - ER Diagram Representation
- Relationship Types and Relationship Sets
- DBMS - Weak Entity Types
- DBMS - Generalization, Aggregation
- DBMS - Drawing an ER Diagram
- DBMS - Enhanced ER Model
- Subclass, Superclass and Inheritance in EER
- Specialization and Generalization in Extended ER Model
- Data Abstraction and Knowledge Representation
- Relational Algebra
- DBMS - Relational Algebra
- Unary Relational Operation
- Set Theory Operations
- DBMS - Database Joins
- DBMS - Division Operation
- DBMS - ER to Relational Model
- Examples of Query in Relational Algebra
- Relational Calculus
- Tuple Relational Calculus
- Domain Relational Calculus
- Relational Database Design
- DBMS - Functional Dependency
- DBMS - Inference Rules
- DBMS - Minimal Cover
- Equivalence of Functional Dependency
- Finding Attribute Closure and Candidate Keys
- Relational Database Design
- DBMS - Keys
- Super keys and candidate keys
- DBMS - Foreign Key
- Finding Candidate Keys
- Normalization in Database Designing
- Database Normalization
- First Normal Form
- Second Normal Form
- Third Normal Form
- Boyce Codd Normal Form
- Difference Between 4NF and 5NF
- Structured Query Language
- Types of Languages in SQL
- Querying in SQL
- CRUD Operations in SQL
- Aggregation Function in SQL
- Join and Subquery in SQL
- Views in SQL
- Trigger and Schema Modification
- Storage and File Structure
- DBMS - Storage System
- DBMS - File Structure
- DBMS - Secondary Storage Devices
- DBMS - Buffer and Disk Blocks
- DBMS - Placing File Records on Disk
- DBMS - Ordered and Unordered Records
- Indexing and Hashing
- DBMS - Indexing
- DBMS - Single-Level Ordered Indexing
- DBMS - Multi-level Indexing
- Dynamic B- Tree and B+ Tree
- DBMS - Hashing
- Query Processing and Optimization
- Heuristics in Query Processing
- Transaction and Concurrency
- DBMS - Transaction
- DBMS - Scheduling Transactions
- DBMS - Testing Serializability
- DBMS - Conflict Serializability
- DBMS - View Serializability
- DBMS - Concurrency Control
- DBMS - Lock Based Protocol
- DBMS - Timestamping based Protocol
- DBMS - Phantom Read Problem
- DBMS - Dirty Read Problem
- DBMS - Thomas Write Rule
- DBMS - Deadlock
- Backup and Recovery
- DBMS - Data Backup
- DBMS - Data Recovery
- DBMS Useful Resources
- DBMS - Quick Guide
- DBMS - Useful Resources
- DBMS - Discussion
DBMS - Indexing
We know that data is stored in the form of records. Every record has a key field, which helps it to be recognized uniquely.
Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done. Indexing in database systems is similar to what we see in books.
Indexing is defined based on its indexing attributes. Indexing can be of the following types −
Primary Index − Primary index is defined on an ordered data file. The data file is ordered on a key field. The key field is generally the primary key of the relation.
Secondary Index − Secondary index may be generated from a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values.
Clustering Index − Clustering index is defined on an ordered data file. The data file is ordered on a non-key field.
Ordered Indexing is of two types −
- Dense Index
- Sparse Index
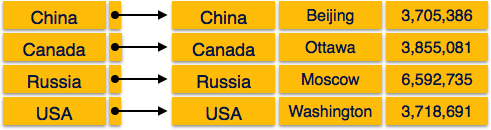
Dense Index
In dense index, there is an index record for every search key value in the database. This makes searching faster but requires more space to store index records itself. Index records contain search key value and a pointer to the actual record on the disk.
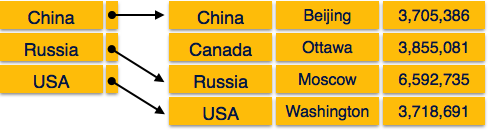
Sparse Index
In sparse index, index records are not created for every search key. An index record here contains a search key and an actual pointer to the data on the disk. To search a record, we first proceed by index record and reach at the actual location of the data. If the data we are looking for is not where we directly reach by following the index, then the system starts sequential search until the desired data is found.
Multilevel Index
Index records comprise search-key values and data pointers. Multilevel index is stored on the disk along with the actual database files. As the size of the database grows, so does the size of the indices. There is an immense need to keep the index records in the main memory so as to speed up the search operations. If single-level index is used, then a large size index cannot be kept in memory which leads to multiple disk accesses.
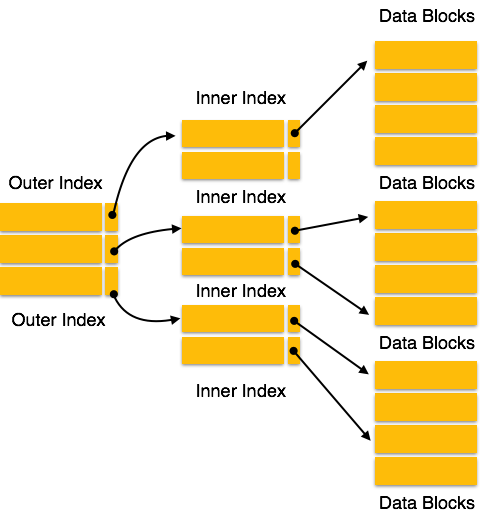
Multi-level Index helps in breaking down the index into several smaller indices in order to make the outermost level so small that it can be saved in a single disk block, which can easily be accommodated anywhere in the main memory.
B+ Tree
A B+ tree is a balanced binary search tree that follows a multi-level index format. The leaf nodes of a B+ tree denote actual data pointers. B+ tree ensures that all leaf nodes remain at the same height, thus balanced. Additionally, the leaf nodes are linked using a link list; therefore, a B+ tree can support random access as well as sequential access.
Structure of B+ Tree
Every leaf node is at equal distance from the root node. A B+ tree is of the order n where n is fixed for every B+ tree.
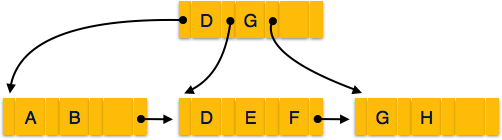
Internal nodes −
- Internal (non-leaf) nodes contain at least ⌈n/2⌉ pointers, except the root node.
- At most, an internal node can contain n pointers.
Leaf nodes −
- Leaf nodes contain at least ⌈n/2⌉ record pointers and ⌈n/2⌉ key values.
- At most, a leaf node can contain n record pointers and n key values.
- Every leaf node contains one block pointer P to point to next leaf node and forms a linked list.
B+ Tree Insertion
B+ trees are filled from bottom and each entry is done at the leaf node.
- If a leaf node overflows −
Split node into two parts.
Partition at i = ⌊(m+1)/2⌋.
First i entries are stored in one node.
Rest of the entries (i+1 onwards) are moved to a new node.
ith key is duplicated at the parent of the leaf.
If a non-leaf node overflows −
Split node into two parts.
Partition the node at i = ⌈(m+1)/2⌉.
Entries up to i are kept in one node.
Rest of the entries are moved to a new node.
B+ Tree Deletion
B+ tree entries are deleted at the leaf nodes.
The target entry is searched and deleted.
If it is an internal node, delete and replace with the entry from the left position.
After deletion, underflow is tested,
If underflow occurs, distribute the entries from the nodes left to it.
If distribution is not possible from left, then
Distribute from the nodes right to it.
If distribution is not possible from left or from right, then
Merge the node with left and right to it.
