- DBMS - Home
- DBMS - Overview
- DBMS - Architecture
- DBMS - Data Models
- DBMS - Data Schemas
- DBMS - Data Independence
- DBMS - System Environment
- Centralized and Client/Server Architecture
- DBMS - Classification
- Relational Model
- DBMS - Codd's Rules
- DBMS - Relational Data Model
- DBMS - Relational Model Constraints
- DBMS - Relational Database Schemas
- DBMS - Handling Constraint Violations
- Entity Relationship Model
- DBMS - ER Model Basic Concepts
- DBMS - ER Diagram Representation
- Relationship Types and Relationship Sets
- DBMS - Weak Entity Types
- DBMS - Generalization, Aggregation
- DBMS - Drawing an ER Diagram
- DBMS - Enhanced ER Model
- Subclass, Superclass and Inheritance in EER
- Specialization and Generalization in Extended ER Model
- Data Abstraction and Knowledge Representation
- Relational Algebra
- DBMS - Relational Algebra
- Unary Relational Operation
- Set Theory Operations
- DBMS - Database Joins
- DBMS - Division Operation
- DBMS - ER to Relational Model
- Examples of Query in Relational Algebra
- Relational Calculus
- Tuple Relational Calculus
- Domain Relational Calculus
- Relational Database Design
- DBMS - Functional Dependency
- DBMS - Inference Rules
- DBMS - Minimal Cover
- Equivalence of Functional Dependency
- Finding Attribute Closure and Candidate Keys
- Relational Database Design
- DBMS - Keys
- Super keys and candidate keys
- DBMS - Foreign Key
- Finding Candidate Keys
- Normalization in Database Designing
- Database Normalization
- First Normal Form
- Second Normal Form
- Third Normal Form
- Boyce Codd Normal Form
- Difference Between 4NF and 5NF
- Structured Query Language
- Types of Languages in SQL
- Querying in SQL
- CRUD Operations in SQL
- Aggregation Function in SQL
- Join and Subquery in SQL
- Views in SQL
- Trigger and Schema Modification
- Storage and File Structure
- DBMS - Storage System
- DBMS - File Structure
- DBMS - Secondary Storage Devices
- DBMS - Buffer and Disk Blocks
- DBMS - Placing File Records on Disk
- DBMS - Ordered and Unordered Records
- Indexing and Hashing
- DBMS - Indexing
- DBMS - Single-Level Ordered Indexing
- DBMS - Multi-level Indexing
- Dynamic B- Tree and B+ Tree
- DBMS - Hashing
- Query Processing and Optimization
- Heuristics in Query Processing
- Transaction and Concurrency
- DBMS - Transaction
- DBMS - Scheduling Transactions
- DBMS - Testing Serializability
- DBMS - Conflict Serializability
- DBMS - View Serializability
- DBMS - Concurrency Control
- DBMS - Lock Based Protocol
- DBMS - Timestamping based Protocol
- DBMS - Phantom Read Problem
- DBMS - Dirty Read Problem
- DBMS - Thomas Write Rule
- DBMS - Deadlock
- Backup and Recovery
- DBMS - Data Backup
- DBMS - Data Recovery
- DBMS Useful Resources
- DBMS - Quick Guide
- DBMS - Useful Resources
- DBMS - Discussion
Data Abstraction and Knowledge Representation
Data abstraction and knowledge representation are fundamental to organizing and understanding complex information. These concepts are especially important in fields like AI and database design, where they help simplify real-world complexities into manageable models that are easier to analyze and manipulate.
This chapter explores the core ideas behind data abstraction and knowledge representation, provides examples, and explains how they connect with ontologies to help model and organize knowledge effectively.
What is Data Abstraction?
Data abstraction involves simplifying complex details and focussing on the essential aspects of data. The concept is useful in both database modeling and AI-based knowledge systems. At its core, data abstraction is a deliberate process of identifying shared properties within a "domain of discourse," while suppressing irrelevant details.
Key elements of data abstraction include −
- Classification and Instantiation − Grouping similar objects into classes for better management.
- Identification − Creating unique identifiers. It is needed for distinguishing and linking objects.
- Specialization and Generalization − Refining or unifying concepts for better representation of data.
- Aggregation and Association − Combining related entities to form higher-level concepts.
Each abstraction method plays a critical role in managing and interpreting complex data effectively. Let us now understand these four concepts of data abstraction with examples.
Classification and Instantiation: Grouping Similar Objects
Classification organizes entities into groups based on shared attributes. For instance, in a Company database −
- Job applicants share attributes like Name, Ssn, and Phone.
- Companies have attributes like Company Name (Cname) and Company Address (Caddress).
Take a look at the following ER diagram
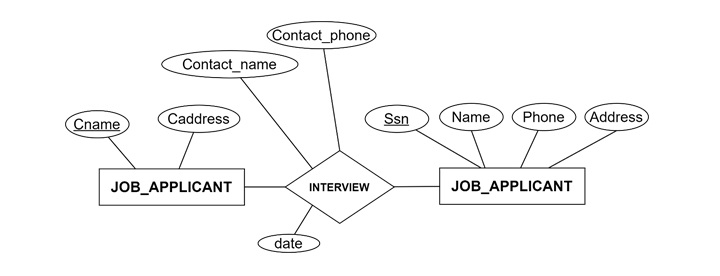
By grouping applicants and companies into separate classes, it becomes easier to describe and analyze the data. Instantiation, on the other hand, focuses on individual members. Instantiation refers to the creation of specific instances from these classes, such as a job applicant named "John Doe" or a company called "TechCorp".
Example − ER diagrams often illustrate this structure. Classification allows class-level properties like "Company Type," while Instances might include a "Startup" or "Multinational".
Identification: Creating Unique Identifiers
Identification ensures that each entity is uniquely distinguishable, which is critical for linking and cross-referencing data. It involves creating names for schema constructs to distinguish objects using attributes. For example −
- A person in a PERSON entity might be identified by their Name, Ssn, and Address.
- The same person could also appear in a STUDENT entity, identified by a Student ID and Course.
Without clear identifiers, we cannot link or cross-reference related instances across entities. Database designers and administrators must implement effective identification mechanisms to maintain consistency.
Specialization and Generalization
Specialization refines a broader class into specific subclasses. Generalization, on the other hand, unifies subclasses into a broader superclass. These processes help capture hierarchical relationships. For example −
- A database may define an Employee superclass, with subclasses such as Manager and Technician.
- Specializing further, Manager might have unique attributes like Department, while Technician might have attributes like Skill Set.
Such classifications allow databases to handle both shared and unique attributes effectively.
Aggregation and Association: Combining Related Entities
Aggregation and Association are the concepts used to combine related objects into higher-level entities.
- Aggregation combines related objects into a composite entity.
- Association links independent entities based on their interactions.
Example − In an Employment database, we may want to represent Interviews between applicants and companies. Aggregation simplifies the process. Take a look at the following representation −
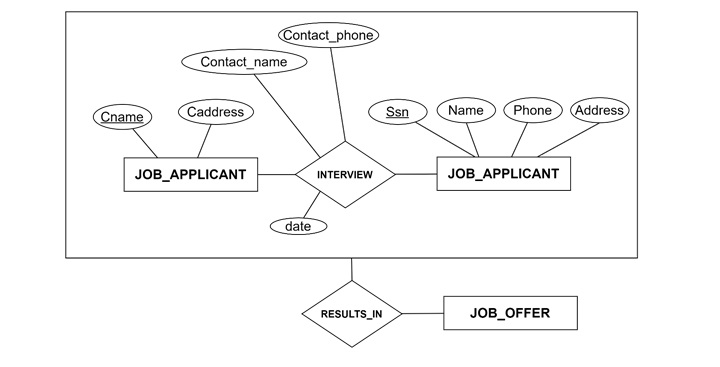
An Interview can be modeled as a composite of Company, Applicant, and attributes like Date and Contact Person. Associating Interview with Job Offer must be done carefully to avoid incorrect assumptions (e.g., assuming every interview results in a job offer).
What is Knowledge Representation?
Building on data abstraction, Knowledge Representation (KR) is about capturing the structure and relationships within a knowledge domain. It goes beyond data modeling by supporting reasoning and inference.
Knowledge Representation models use −
- Rules for decision-making.
- Incomplete and temporal knowledge to manage uncertainty.
Unlike traditional databases, KR systems mix schemas with data instances, enabling intelligent reasoning over the stored information.
Ontologies and the Semantic Web
Ontology is a concept rooted in philosophy that provides a shared vocabulary for describing a domain. Ontologies are now critical for creating shared understanding in AI and the Semantic Web.
An ontology defines −
- Concepts − Entities, attributes, and relationships
- Relationships − How those concepts connect or interact
For example, suppose a company is hiring. In this context, an ontology might define terms like "Applicant", "Interview", and "Job Offer" and their interconnections.
Role in the Semantic Web
Ontologies means data exchange and search across diverse systems. By defining shared meanings, they allow diverse applications to exchange and interpret data meaningfully.
Example − A semantic job portal might use ontologies to link job requirements with applicant profiles, despite differences in data structures, even when the data is in different formats and structures.
Challenges and Opportunities in Data Abstraction and Knowledge Representation
Data abstraction and knowledge representation provide powerful tools, but they also have some limitations −
- Efficiency − Representing exceptions or composite entities can be resource-intensive.
- Flexibility − Balancing schema-level definitions with instance-level data requires careful planning and design.
Conclusion
This chapter introduced the foundational concepts of data abstraction and knowledge representation. We explored core concepts such as classification, identification, specialization, and aggregation, with practical examples. We also examined their application in knowledge systems and the Semantic Web, highlighting the importance of ontologies in creating shared meaning across platforms.
