- DBMS - Home
- DBMS - Overview
- DBMS - Architecture
- DBMS - Data Models
- DBMS - Data Schemas
- DBMS - Data Independence
- DBMS - System Environment
- Centralized and Client/Server Architecture
- DBMS - Classification
- Relational Model
- DBMS - Codd's Rules
- DBMS - Relational Data Model
- DBMS - Relational Model Constraints
- DBMS - Relational Database Schemas
- DBMS - Handling Constraint Violations
- Entity Relationship Model
- DBMS - ER Model Basic Concepts
- DBMS - ER Diagram Representation
- Relationship Types and Relationship Sets
- DBMS - Weak Entity Types
- DBMS - Generalization, Aggregation
- DBMS - Drawing an ER Diagram
- DBMS - Enhanced ER Model
- Subclass, Superclass and Inheritance in EER
- Specialization and Generalization in Extended ER Model
- Data Abstraction and Knowledge Representation
- Relational Algebra
- DBMS - Relational Algebra
- Unary Relational Operation
- Set Theory Operations
- DBMS - Database Joins
- DBMS - Division Operation
- DBMS - ER to Relational Model
- Examples of Query in Relational Algebra
- Relational Calculus
- Tuple Relational Calculus
- Domain Relational Calculus
- Relational Database Design
- DBMS - Functional Dependency
- DBMS - Inference Rules
- DBMS - Minimal Cover
- Equivalence of Functional Dependency
- Finding Attribute Closure and Candidate Keys
- Relational Database Design
- DBMS - Keys
- Super keys and candidate keys
- DBMS - Foreign Key
- Finding Candidate Keys
- Normalization in Database Designing
- Database Normalization
- First Normal Form
- Second Normal Form
- Third Normal Form
- Boyce Codd Normal Form
- Difference Between 4NF and 5NF
- Structured Query Language
- Types of Languages in SQL
- Querying in SQL
- CRUD Operations in SQL
- Aggregation Function in SQL
- Join and Subquery in SQL
- Views in SQL
- Trigger and Schema Modification
- Storage and File Structure
- DBMS - Storage System
- DBMS - File Structure
- DBMS - Secondary Storage Devices
- DBMS - Buffer and Disk Blocks
- DBMS - Placing File Records on Disk
- DBMS - Ordered and Unordered Records
- Indexing and Hashing
- DBMS - Indexing
- DBMS - Single-Level Ordered Indexing
- DBMS - Multi-level Indexing
- Dynamic B- Tree and B+ Tree
- DBMS - Hashing
- Query Processing and Optimization
- Heuristics in Query Processing
- Transaction and Concurrency
- DBMS - Transaction
- DBMS - Scheduling Transactions
- DBMS - Testing Serializability
- DBMS - Conflict Serializability
- DBMS - View Serializability
- DBMS - Concurrency Control
- DBMS - Lock Based Protocol
- DBMS - Timestamping based Protocol
- DBMS - Phantom Read Problem
- DBMS - Dirty Read Problem
- DBMS - Thomas Write Rule
- DBMS - Deadlock
- Backup and Recovery
- DBMS - Data Backup
- DBMS - Data Recovery
- DBMS Useful Resources
- DBMS - Quick Guide
- DBMS - Useful Resources
- DBMS - Discussion
DBMS - Query Processing
We use various types of queries in DBMS to retrieve data. Proper query processing needs optimization. Query processing transforms user requests into efficient data retrieval operations. As databases grow in size and complexity, executing the queries becomes more complex and getting the results timely and accurately becomes challenging.
Read this chapter to learn the need for query processing, its various stages, real-world examples, algorithms used, and the challenges faced by modern database systems.
What is Query Processing?
Query processing refers to the steps needed in interpreting and executing the queries issued by users or the application software. It bridges the gap between the high-level query languages like SQL and the low-level file operations performed by the DBMS. For the queries, the ultimate goal is to retrieve the desired data efficiently, by consuming as less resource (memory, CPU, and disk I/O) as possible.
Without query processing, retrieving specific records from large databases would be slow and unreliable. This process shows that the system understands user requests and finds optimal ways to execute them.
The Importance of Query Processing in DBMS
Query processing is needed due to the following reasons −
- Performance Improvement − Databases sometimes contain millions of records spread across multiple files. Query processing reduces the search time by optimizing the data retrieval methods.
- Data Accuracy and Integrity − By verifying and validating the queries, query processing guarantees that users receive accurate results. Any errors in the query structure or content are flagged early in the process.
- Resource Efficiency − Executing a query efficiently means taking a course of action that consumes less memory, less disk space, and less CPU cycles. Query optimization reduces resource consumption by selecting the best execution strategy.
- Scalability − Well-designed query processing mechanisms enable databases to scale without significant performance degradation. This is important for systems handling growing datasets.
Key Steps in Query Processing
Query processing consists of several steps. Each step is designed to transform a user query into an executable plan. The steps are scanning, parsing, and validation.
The first step in query processing is interpreting the query's text −
- Scanning − The system breaks the query into tokens like SQL keywords (SELECT, WHERE). Here, it incorporates the table names and attributes.
- Parsing − The parser checks if the query follows the syntax rules of the query language.
- Validation − The system verifies that all the specified tables and columns exist and are accessible.
Consider the following SQL query −
SELECT Lname, Fname FROM EMPLOYEE WHERE Salary > 50000;
In this query,
- Scanning − Recognizes keywords like SELECT, FROM, WHERE.
- Parsing − Confirms that the query is syntactically correct.
- Validation − Checks whether the EMPLOYEE table and its columns (Lname, Fname, Salary) exist.
The following flowchart shows the series of steps a query must go through to fetch the output data −
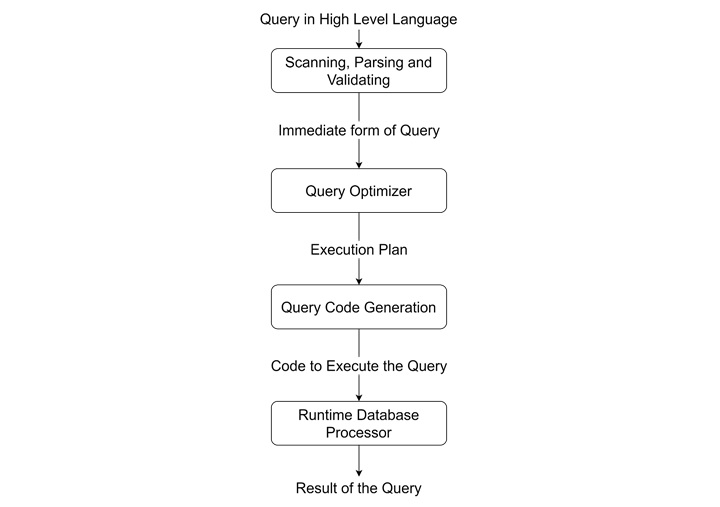
Query Optimization in DBMS
Once the query is validated, the next step for the DBMS is to decide the most efficient way to execute the query. It involves the following steps −
- Query Tree Creation − The system converts the query into a query tree or query graph. It represents the logical structure of the query.
- Execution Plan Selection − The optimizer evaluates different execution strategies and chooses the one with the lowest estimated cost.
Example − Consider a query that finds employees earning more than the average salary in department 5 −
SELECT Lname, Fname FROM EMPLOYEE WHERE Salary > (SELECT AVG(Salary) FROM EMPLOYEE WHERE Dno=5);
This query has two blocks −
- Inner Query − Calculates the average salary in department 5.
- Outer Query − Retrieves employees with salaries above this average.
The optimizer evaluates alternatives. Now in such cases it is computing the inner query only once instead of recalculating it repeatedly. This significantly reduces execution time.
Code Generation and Execution
The next phase is code generation and execution. After optimization, the system generates an executable query plan. Depending on the DBMS, the plan can be −
- Interpreted Mode − Executed directly
- Compiled Mode − Stored for future use
The runtime database processor executes the query and returns the result to the user.
Algorithms for Query Processing
Several algorithms handle different query processing tasks. Here, let's understand in brief how external sorting and the search methods work. We will cover them in detail in the later chapters.
External Sorting: The Sort-Merge Algorithm
Sorting is a frequent operation in query processing. Mainly when queries include ORDER BY etc. Since datasets may be too large to fit into main memory, external sorting methods like sort-merge sorting are used. It has majorly two steps.
- Sorting Phase − Break the file into smaller sub-files that fit in memory. Then sort them, and write them back to disk.
- Merging Phase − Merge the sorted sub-files repeatedly until a single sorted file remains.
Example − Suppose we need to sort a file with 1,024 blocks using a memory buffer holding 5 blocks at a time −
- Initial Sorting − The system creates 205 sorted chunks. Each holding 5 blocks.
- Merging Phase − The sorted chunks are merged four at a time:
205 → 52 → 13 → 4 → 1 (fully sorted file)
The total sorting cost consists of reading and writing costs for each block multiple times. They are calculated as −
Cost = 2b + 2b·log4 (205)
Where "b" is the number of blocks.
Search Methods for Query Execution
The search methods vary depending on file organization and available indexes −
- Linear Search − Scans all records sequentially.
- Binary Search − Searches ordered files using key comparisons.
- Index-based Search − Uses indexes such as primary, clustering, or secondary indexes for faster lookups.
Example − To retrieve an employee with SSN = '123456789', the system uses a primary index rather than scanning the entire file. This approach helps in reducing the search time significantly.
Challenges in Query Processing
Listed below are some of the challenges that databases face in managing complex queries while balancing performance, accuracy, and scalability −
- Query Complexity − Complex queries contain multiple joins, subqueries, and conditions that require advanced optimization strategies.
- Resource Constraints − Query processing must manage limited memory, CPU power, and disk space efficiently.
- Data Distribution − Uneven data distributions can lead to performance bottlenecks if the queries frequently access heavily populated records.
- Index Maintenance − Creating and updating indexes consumes resources, though it speeds up the future queries.
Conclusion
In this chapter, we highlighted the importance of query processing in databases. We covered the three essential steps: scanning, parsing, and validation. In query optimization, we understood how algorithms like external sorting and searching improve the query efficiency.
