- OS - Home
- OS - Overview
- OS - History
- OS - Evolution
- OS - Functions
- OS - Components
- OS - Structure
- OS - Architecture
- OS - Services
- OS - Properties
- Process Management
- Processes in Operating System
- States of a Process
- Process Schedulers
- Process Control Block
- Operations on Processes
- Process Suspension and Process Switching
- Process States and the Machine Cycle
- Inter Process Communication (IPC)
- Remote Procedure Call (RPC)
- Context Switching
- Threads
- Types of Threading
- Multi-threading
- System Calls
- Scheduling Algorithms
- Process Scheduling
- Types of Scheduling
- Scheduling Algorithms Overview
- FCFS Scheduling Algorithm
- SJF Scheduling Algorithm
- Round Robin Scheduling Algorithm
- HRRN Scheduling Algorithm
- Priority Scheduling Algorithm
- Multilevel Queue Scheduling
- Lottery Scheduling Algorithm
- Starvation and Aging
- Turn Around Time & Waiting Time
- Burst Time in SJF Scheduling
- Process Synchronization
- Process Synchronization
- Solutions For Process Synchronization
- Hardware-Based Solution
- Software-Based Solution
- Critical Section Problem
- Critical Section Synchronization
- Mutual Exclusion Synchronization
- Mutual Exclusion Using Interrupt Disabling
- Peterson's Algorithm
- Dekker's Algorithm
- Bakery Algorithm
- Semaphores
- Binary Semaphores
- Counting Semaphores
- Mutex
- Turn Variable
- Bounded Buffer Problem
- Reader Writer Locks
- Test and Set Lock
- Monitors
- Sleep and Wake
- Race Condition
- Classical Synchronization Problems
- Dining Philosophers Problem
- Producer Consumer Problem
- Sleeping Barber Problem
- Reader Writer Problem
- OS Deadlock
- Introduction to Deadlock
- Conditions for Deadlock
- Deadlock Handling
- Deadlock Prevention
- Deadlock Avoidance (Banker's Algorithm)
- Deadlock Detection and Recovery
- Deadlock Ignorance
- Resource Allocation Graph
- Livelock
- Memory Management
- Memory Management
- Logical and Physical Address
- Contiguous Memory Allocation
- Non-Contiguous Memory Allocation
- First Fit Algorithm
- Next Fit Algorithm
- Best Fit Algorithm
- Worst Fit Algorithm
- Buffering
- Fragmentation
- Compaction
- Virtual Memory
- Segmentation
- Paged Segmentation & Segmented Paging
- Buddy System
- Slab Allocation
- Overlays
- Free Space Management
- Locality of Reference
- Paging and Page Replacement
- Paging
- Demand Paging
- Page Table
- Page Replacement Algorithms
- Second Chance Page Replacement
- Optimal Page Replacement Algorithm
- Belady's Anomaly
- Thrashing
- Storage and File Management
- File Systems
- File Attributes
- Structures of Directory
- Linked Index Allocation
- Indexed Allocation
- Disk Scheduling Algorithms
- FCFS Disk Scheduling
- SSTF Disk Scheduling
- SCAN Disk Scheduling
- LOOK Disk Scheduling
- I/O Systems
- I/O Hardware
- I/O Software
- I/O Programmed
- I/O Interrupt-Initiated
- Direct Memory Access
- OS Types
- OS - Types
- OS - Batch Processing
- OS - Multiprogramming
- OS - Multitasking
- OS - Multiprocessing
- OS - Distributed
- OS - Real-Time
- OS - Single User
- OS - Monolithic
- OS - Embedded
- Popular Operating Systems
- OS - Hybrid
- OS - Zephyr
- OS - Nix
- OS - Linux
- OS - Blackberry
- OS - Garuda
- OS - Tails
- OS - Clustered
- OS - Haiku
- OS - AIX
- OS - Solus
- OS - Tizen
- OS - Bharat
- OS - Fire
- OS - Bliss
- OS - VxWorks
- Miscellaneous Topics
- OS - Security
- OS Questions Answers
- OS - Questions Answers
- OS Useful Resources
- OS - Quick Guide
- OS - Useful Resources
- OS - Discussion
Operating System - SSTF Disk Scheduling
The disk scheduling algorithms are used to determine the order in which input and output (I/O) requests of the disk are to be processed. In this chapter, we will discuss the Shortest Seek Time First (SSTF) disk scheduling algorithm with examples and practice questions.
- Shortest Seek Time First (SSTF) Disk Scheduling
- Example of SSTF Disk Scheduling Algorithm
- Implementation of SSTF Disk Scheduling Algorithm
- Practice Questions in SSTF Disk Scheduling Algorithm
- Pros and Cons of SSTF Disk Scheduling Algorithm
Shortest Seek Time First (SSTF) Disk Scheduling
The Shortest Seek Time First (SSTF) disk scheduling algorithm selects the request that is closest to the current position of the disk head. This means that the request with the shortest seek time will be served first. And this will not depend on the order of arrival of requests.
The SSTF is considered as more optimal than the FCFS disk scheduling algorithm because it reduces the total head movement and hence the seek time. However, in some cases, it can lead to starvation, meaning that some requests may never get served if they are far from the current head position.
Algorithm Steps
- Start from the current position of the disk head.
- Calculate the distance of all pending requests from the current head position and store them in a min heap.
- Now, the top element of the min heap will be the request with the shortest seek time. Move the disk head to that request and process it.
- Remove the processed request from the min heap.
- Repeat these steps until all requests are processed.
Example of SSTF Disk Scheduling Algorithm
Consider that the disk requests are arriving in the order: 98, 183, 37, 122, 14, 124, 65, 67. And the initial position of the disk head is at track 53. The image below shows how the disk head moves for the above request sequence using SSTF disk scheduling algorithm −
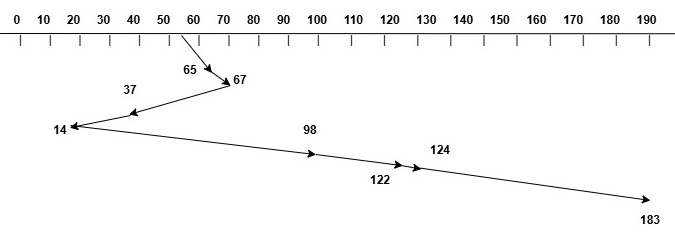
Now, to calculate the total head movement using SSTF algorithm, we can follow the steps below:
$$\mathrm{\text{Initial Position of Head} \:=\: 53}$$
$$\mathrm{\text{Request Sequence} = 98,\,183,\,37,\,122,\,14,\,124,\,65,\,67}$$
$$\mathrm{\text{Move from } 53 \text{ to } 65: |53-65| = 12}$$
$$\mathrm{\text{Move from } 65 \text{ to } 67: |65-67| = 2}$$
$$\mathrm{\text{Move from } 67 \text{ to } 37: |67-37| = 30}$$
$$\mathrm{\text{Move from } 37 \text{ to } 14: |37-14| = 23}$$
$$\mathrm{\text{Move from } 14 \text{ to } 98: |14-98| = 84}$$
$$\mathrm{\text{Move from } 98 \text{ to } 122: |98-122| = 24}$$
$$\mathrm{\text{Move from } 122 \text{ to } 124: |122-124| = 2}$$
$$\mathrm{\text{Move from } 124 \text{ to } 183: |124-183| = 59}$$
Now, we can calculate the total head movement by summing up all the individual head movements. Also the average seek length can be calculated by dividing the total head movement by the number of requests.
$$\mathrm{\text{Total Head Movement} = 12 + 2 + 30 + 23 + 84 + 24 + 2 + 59}$$
$$\mathrm{ = 236 \text{ tracks}}$$
$$\mathrm{\text{Average Seek Length} = \frac{\text{Total Head Movement}}{\text{Number of Requests}} }$$
$$\mathrm{= \frac{236}{8} = 29.5 \text{ tracks}}$$
For the same request sequence and initial head position, the FCFS algorithm will take a total head movement of 640 tracks (calculated in the FCFS chapter). You can see that the SSTF only takes 236 tracks. This indicates that the SSTF algorithm is more optimized and efficient than the FCFS algorithm.
Implementation of SSTF Disk Scheduling Algorithm
Here is how we can implement the SSTF disk scheduling algorithm in Python/CPP/Java −
import heapq
def sstf_disk_scheduling(requests, head):
total_head_movement = 0
seek_sequence = []
requests = requests.copy()
while requests:
distances = [(abs(head - req), req) for req in requests]
heapq.heapify(distances)
shortest_distance, closest_request = heapq.heappop(distances)
total_head_movement += shortest_distance
head = closest_request
seek_sequence.append(closest_request)
requests.remove(closest_request)
return total_head_movement, seek_sequence
# Example usage
requests = [98, 183, 37, 122, 14, 124, 65, 67]
initial_head = 53
total_movement, sequence = sstf_disk_scheduling(requests, initial_head)
print("Total Head Movement:", total_movement)
print("Seek Sequence:", sequence)
The output of the above code is as follows −
Total Head Movement: 236 Seek Sequence: [65, 67, 37, 14, 98, 122, 124, 183]
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
using namespace std;
pair<int, vector<int>> sstf_disk_scheduling(vector<int> requests, int head) {
int total_head_movement = 0;
vector<int> seek_sequence;
while (!requests.empty()) {
auto closest = min_element(requests.begin(), requests.end(),
[head](int a, int b) {
return abs(a - head) < abs(b - head);
});
total_head_movement += abs(*closest - head);
head = *closest;
seek_sequence.push_back(*closest);
requests.erase(closest);
}
return { total_head_movement, seek_sequence };
}
int main() {
vector<int> requests = { 98, 183, 37, 122, 14, 124, 65, 67 };
int initial_head = 53;
auto [total_movement, sequence] = sstf_disk_scheduling(requests, initial_head);
cout << "Total Head Movement: " << total_movement << endl;
cout << "Seek Sequence: ";
for (int req : sequence) {
cout << req << " ";
}
cout << endl;
return 0;
}
The output of the above code is as follows −
Total Head Movement: 236 Seek Sequence: 65 67 37 14 98 122 124 183
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class SSTFDiskScheduling {
public static Pair sstfDiskScheduling(List<Integer> requests, int head) {
int totalHeadMovement = 0;
List<Integer> seekSequence = new ArrayList<>();
while (!requests.isEmpty()) {
final int currentHead = head;
int closestRequest = Collections.min(
requests,
(a, b) -> Integer.compare(Math.abs(a - currentHead), Math.abs(b - currentHead))
);
totalHeadMovement += Math.abs(closestRequest - head);
head = closestRequest;
seekSequence.add(closestRequest);
requests.remove(Integer.valueOf(closestRequest));
}
return new Pair(totalHeadMovement, seekSequence);
}
public static void main(String[] args) {
List<Integer> requests = new ArrayList<>(List.of(98, 183, 37, 122, 14, 124, 65, 67));
int initialHead = 53;
Pair result = sstfDiskScheduling(requests, initialHead);
System.out.println("Total Head Movement: " + result.totalHeadMovement);
System.out.println("Seek Sequence: " + result.seekSequence);
}
}
class Pair {
int totalHeadMovement;
List<Integer> seekSequence;
Pair(int totalHeadMovement, List<Integer> seekSequence) {
this.totalHeadMovement = totalHeadMovement;
this.seekSequence = seekSequence;
}
}
The output of the above code is as follows −
Total Head Movement: 236 Seek Sequence: [65, 67, 37, 14, 98, 122, 124, 183]
Practice Questions in SSTF Disk Scheduling
Question 1: Given the following disk requests: 45, 23, 89, 12, 67, and the initial position of the disk head is at track 30. Calculate the total head movement using the SSTF disk scheduling algorithm.
Answer: We have,
$$\mathrm{\text{Initial Position of Head} = 30}$$
$$\mathrm{\text{Request Sequence} = 45,\,23,\,89,\,12,\,67}$$
Now, we can calculate the total head movement step by step −
$$\mathrm{\text{Move from } 30 \text{ to } 23: |30-23| = 7}$$
$$\mathrm{\text{Move from } 23 \text{ to } 12: |23-12| = 11}$$
$$\mathrm{\text{Move from } 12 \text{ to } 45: |12-45| = 33}$$
$$\mathrm{\text{Move from } 45 \text{ to } 67: |45-67| = 22}$$
$$\mathrm{\text{Move from } 67 \text{ to } 89: |67-89| = 22}$$
Now, we can calculate the total head movement by summing up all the individual head movements.
$$\mathrm{\text{Total Head Movement} = 7 + 11 + 33 + 22 + 22 = 105}$$
Question 2: Given the following disk requests: 150, 30, 90, 10, 70. Find the seek time if the initial position of the disk head is at track 50. Assume that the seek time per track is 0.1 ms.
Answer: We have,
$$\mathrm{\text{Initial Position of Head} = 50}$$
$$\mathrm{\text{Request Sequence} = 150,\,30,\,90,\,10,\,70}$$
First let's calculate the total head movement step by step −
$$\mathrm{\text{Move from } 50 \text{ to } 70: |50-70| = 20}$$
$$\mathrm{\text{Move from } 70 \text{ to } 90: |70-90| = 20}$$
$$\mathrm{\text{Move from } 90 \text{ to } 30: |90-30| = 60}$$
$$\mathrm{\text{Move from } 30 \text{ to } 10: |30-10| = 20}$$
$$\mathrm{\text{Move from } 10 \text{ to } 150: |10-150| = 140}$$
$$\mathrm{\text{Total Head Movement} = 20 + 20 + 60 + 20 + 140 = 260}$$
So the total head movement is 260 tracks. Now, the seek time can be calculated by multiplying the total head movement by the seek time per track.
$$\mathrm{\text{Seek Time} = \text{Total Head Movement} \times \text{Seek Time per Track} }$$
$$\mathrm{= 260 \times 0.1 = 26 \text{ ms}}$$
Therefore, the seek time is 26 ms.
Pros and Cons of SSTF Disk Scheduling Algorithm
The advantages of this algorithm are:
- The average seek time is lowest among all disk scheduling algorithms.
- More efficient resource utilization
The drawbacks of this algorithm are −
- Can lead to starvation for some requests if they are far from the current head position.
- More complex to implement compared to FCFS.
- Requires knowledge of all pending requests to make optimal decisions.
