- OS - Home
- OS - Overview
- OS - History
- OS - Evolution
- OS - Functions
- OS - Components
- OS - Structure
- OS - Architecture
- OS - Services
- OS - Properties
- Process Management
- Processes in Operating System
- States of a Process
- Process Schedulers
- Process Control Block
- Operations on Processes
- Process Suspension and Process Switching
- Process States and the Machine Cycle
- Inter Process Communication (IPC)
- Remote Procedure Call (RPC)
- Context Switching
- Threads
- Types of Threading
- Multi-threading
- System Calls
- Scheduling Algorithms
- Process Scheduling
- Types of Scheduling
- Scheduling Algorithms Overview
- FCFS Scheduling Algorithm
- SJF Scheduling Algorithm
- Round Robin Scheduling Algorithm
- HRRN Scheduling Algorithm
- Priority Scheduling Algorithm
- Multilevel Queue Scheduling
- Lottery Scheduling Algorithm
- Starvation and Aging
- Turn Around Time & Waiting Time
- Burst Time in SJF Scheduling
- Process Synchronization
- Process Synchronization
- Solutions For Process Synchronization
- Hardware-Based Solution
- Software-Based Solution
- Critical Section Problem
- Critical Section Synchronization
- Mutual Exclusion Synchronization
- Mutual Exclusion Using Interrupt Disabling
- Peterson's Algorithm
- Dekker's Algorithm
- Bakery Algorithm
- Semaphores
- Binary Semaphores
- Counting Semaphores
- Mutex
- Turn Variable
- Bounded Buffer Problem
- Reader Writer Locks
- Test and Set Lock
- Monitors
- Sleep and Wake
- Race Condition
- Classical Synchronization Problems
- Dining Philosophers Problem
- Producer Consumer Problem
- Sleeping Barber Problem
- Reader Writer Problem
- OS Deadlock
- Introduction to Deadlock
- Conditions for Deadlock
- Deadlock Handling
- Deadlock Prevention
- Deadlock Avoidance (Banker's Algorithm)
- Deadlock Detection and Recovery
- Deadlock Ignorance
- Resource Allocation Graph
- Livelock
- Memory Management
- Memory Management
- Logical and Physical Address
- Contiguous Memory Allocation
- Non-Contiguous Memory Allocation
- First Fit Algorithm
- Next Fit Algorithm
- Best Fit Algorithm
- Worst Fit Algorithm
- Buffering
- Fragmentation
- Compaction
- Virtual Memory
- Segmentation
- Paged Segmentation & Segmented Paging
- Buddy System
- Slab Allocation
- Overlays
- Free Space Management
- Locality of Reference
- Paging and Page Replacement
- Paging
- Demand Paging
- Page Table
- Page Replacement Algorithms
- Second Chance Page Replacement
- Optimal Page Replacement Algorithm
- Belady's Anomaly
- Thrashing
- Storage and File Management
- File Systems
- File Attributes
- Structures of Directory
- Linked Index Allocation
- Indexed Allocation
- Disk Scheduling Algorithms
- FCFS Disk Scheduling
- SSTF Disk Scheduling
- SCAN Disk Scheduling
- LOOK Disk Scheduling
- I/O Systems
- I/O Hardware
- I/O Software
- I/O Programmed
- I/O Interrupt-Initiated
- Direct Memory Access
- OS Types
- OS - Types
- OS - Batch Processing
- OS - Multiprogramming
- OS - Multitasking
- OS - Multiprocessing
- OS - Distributed
- OS - Real-Time
- OS - Single User
- OS - Monolithic
- OS - Embedded
- Popular Operating Systems
- OS - Hybrid
- OS - Zephyr
- OS - Nix
- OS - Linux
- OS - Blackberry
- OS - Garuda
- OS - Tails
- OS - Clustered
- OS - Haiku
- OS - AIX
- OS - Solus
- OS - Tizen
- OS - Bharat
- OS - Fire
- OS - Bliss
- OS - VxWorks
- Miscellaneous Topics
- OS - Security
- OS Questions Answers
- OS - Questions Answers
- OS Useful Resources
- OS - Quick Guide
- OS - Useful Resources
- OS - Discussion
Operating System - Disk Scheduling Algorithms
Disk scheduling algorithms are used by operating systems to manage the read and write requests of computer's hard disk drive (HDD) or solid-state drive (SSD). The main aim of scheduling algorithms is to minimize the seek time, rotational latency, and overall response time for disk I/O operations. Following are most commonly used disk scheduling algorithms.
- First-Come, First-Served (FCFS) Disk Scheduling
- Shortest Seek Time First (SSTF) Disk Scheduling
- SCAN Disk Scheduling
- C-SCAN Disk Scheduling
- LOOK Disk Scheduling
- C-LOOK Disk Scheduling
- Random Disk Scheduling
- Last-In, First-Out (LIFO) Disk Scheduling
Important Terms Related to Disk Scheduling
Before moving to the algorithms, let's understand some important terms related to disk scheduling:
1. Seek Time
Seek time is the time taken by the disk's read/write head to move to the place where the data is stored. High seek times means that the disk head has to move a lot to reach the requested data. This will affect the overall performance of the disk I/O operations.
2. Rotational Latency
Rotational latency is the time taken for the sector containing the data to rotate under the read/write head to the correct position. It depends on the speed of the disk's rotation. Faster rotation speeds make rotational latency lower and the data can be accessed more quickly.
3. Response Time
Response time is the total time taken to complete a disk I/O operation. This is the sum of seek time, rotational latency, and data transfer time. If the response time is low, it means that the disk can quickly respond to read/write requests.
4. Transfer Time
Transfer time is the time taken to actually transfer the data after the read/write head reached at the correct position. This time does not depend disk head movement, it only depends on the amount of data being transferred and the speed of the transfer.
The formulas for calculating disk access time and total seek time are as follows:
$$\mathrm{\text{ Disk Access Time}\) = $$\mathrm{\text{Seek Time} + \text{Rotational Latency} + \text{Transfer Time}}$$
$$\mathrm{\text{Total Head Movement} = \sum |\text{Current Head Position} - \text{Next Request Position}|}$$
$$\mathrm{\text{Total Seek Time} = \text{Total Head Movement} \times \text{Seek Time per Track}}$$
First-Come, First-Served (FCFS) Disk Scheduling
The FCFS (also called as FIFO, First-in First-out) disk scheduling algorithm is the simplest form of disk scheduling. Here, the requests are processed in the order they arrive. Meaning the request that came first will be served first. This will not depend on the current position of the disk head.
The image below shows how the disk head moves for the sequence of requests: 98, 183, 37, 122, 14, 124, 65, 67 using FCFS disk scheduling algorithm −
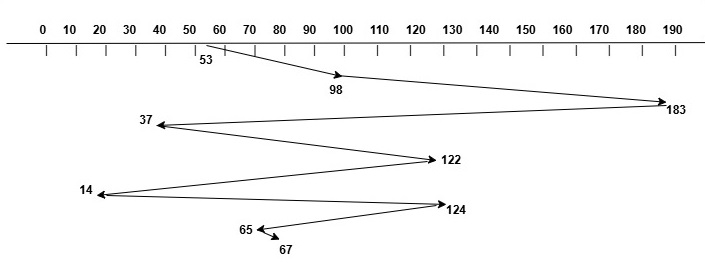
Initial Position of Head = 53
Request Sequence = 98, 183, 37, 122, 14, 124, 65, 67
Total Head Movement = |53-98| + |98-183| + |183-37| + |37-122| + |122-14|
+ |14-124| + |124-65| + |65-67|
= 45 + 85 + 146 + 85 + 108 + 110 + 59 + 2
= 640 tracks
So the total head movement using FCFS disk scheduling algorithm is 640 tracks.
Shortest Seek Time First (SSTF) Disk Scheduling
The SSTF disk scheduling algorithm selects the request that is closest to the current position of the disk head. This means that the request with the shortest seek time will be served first. And this will not depend on the order of arrival of requests.
Compared to FCFS, the total head movement is significantly low in SSTF algorithm. This is because SSTF always selects the request that is closest to the current head position. So it minimizes the distance the head has to move for each request. However, this algorithm can lead to starvation.
The image below shows how the disk head moves for a request sequence: 98, 183, 37, 122, 14, 124, 65, 67. The initial position of the disk head is at track 53.
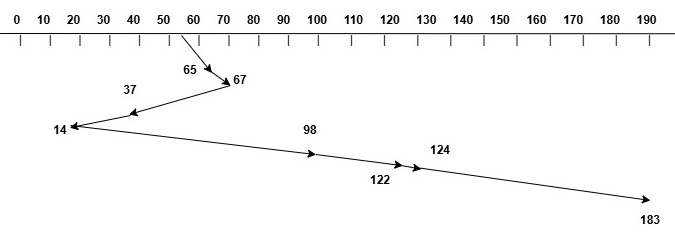
Initial Position of Head = 53
Request Sequence = 98, 183, 37, 122, 14, 124, 65, 67
Total Head Movement = |53-65| + |65-67| + |67-37| + |37-14| + |14-98|
+ |98-122| + |122-124| + |124-183|
= 12 + 2 + 30 + 23 + 84 + 24 + 2 + 59
= 236 tracks
So the total head movement is 236 tracks. We can see that the total head movement is reduced using SSTF algorithm compared to FCFS.
SCAN Disk Scheduling
The SCAN disk scheduling algorithm works by moving the disk head in one direction (either left or right) and then serve all the requests in that direction until it reaches the end of the disk. After reaching the end, the head reverses its direction and serves the requests in the opposite direction. This is also known as the elevator algorithm due to its similarity with working of an elevator.
For example, consider the a disk having 200 tracks and requests are arriving in the order: [82, 170, 43, 140, 34, 190]. The initial position of the disk head is at track 70 and the head is moving towards the right. The image below shows how the disk head moves for this request sequence.
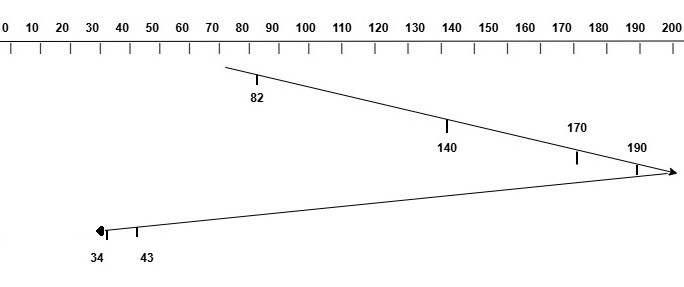
The total head movement can be calculated as follows −
Initial Position of Head = 70
Request Sequence = 82, 170, 43, 140, 34, 190
Start from 70 and move towards right
Serve 82, 140, 170, 190
Reach the end of the disk at 199
Now, reverse direction and move towards left
Serve 43, 34
Total Head Movement = 199 - 70 + 199 - 34
= 129 + 165
= 294 tracks
The advantages of this algorithm are −
- Improves response time for requests.
- Reduces the variance in wait times for requests.
The drawbacks of this algorithm are −
- Can lead to longer wait times for requests located at the ends of the disk.
- More complex to implement compared to FCFS and SSTF.
C-SCAN Disk Scheduling
The C-SCAN (Circular SCAN) disk scheduling algorithm is an improvement over the SCAN algorithm. In C-SCAN, the disk head moves in one direction (either left or right) and serves all the requests in that direction until it reaches the end of the disk. After reaching the end, instead of reversing direction, the head jumps back to the beginning of the disk and starts serving requests in the same direction again. This algorithm is suitable for circular disk structures.
Using the same example as above, with the current head position at cylinder 70 and requests for cylinders 82, 170, 43, 140 , 34, and 190, the image below shows how the disk head will move to serve the requests using the C-SCAN algorithm.
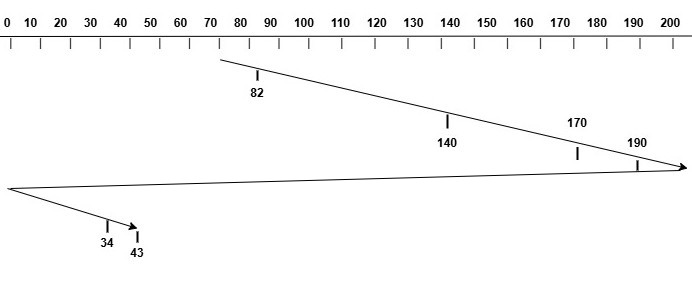
Initial Position of Head = 70
Request Sequence = 82, 170, 43, 140, 34, 190
Start from 70 and move towards right
Serve 82, 140, 170, 190
Reach the end of the disk at 199 (199 - 70 tracks)
Jump to the beginning of the disk (199 tracks)
Now, reverse direction and move towards left
Serve 34, 43 (43 - 0 tracks)
Total Head Movement = 199 - 70 + 199 + 43 - 0
= 129 + 199 + 43
= 371 tracks
The advantages of this algorithm are −
- Improves response time for requests.
- Reduces the variance in wait times for requests.
The drawbacks of this algorithm are −
- Can lead to longer wait times for requests located at the ends of the disk.
- More complex to implement compared to FCFS and SSTF.
LOOK Disk Scheduling
The LOOK disk scheduling algorithm is an improvement over the SCAN algorithm. In LOOK, the disk head does not go to the end of the disk if there are no requests in that direction. Instead, it reverses its direction as soon as it reaches the last request in that direction. This way it reduces unnecessary head movement.
Consider a disk with 200 cylinders numbered from 0 to 199. The current head position is at cylinder 70, and the requests are for cylinders 82, 170, 43, 140, 34, and 190. Assume that the head is moving towards the right direction. The image below shows how the disk head will move to serve the requests using the LOOK algorithm.
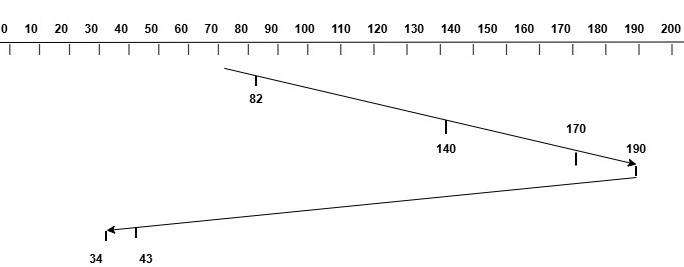
The total head movement can be calculated as follows −
Initial Position of Head = 70
Request Sequence = 82, 170, 43, 140, 34, 190
Start from 70 and move towards right
Serve 82, 140, 170, 190 (190 - 70 tracks)
Now, reverse direction and move towards left
Serve 43, 34 (190 - 34 tracks)
Total Head Movement = 190 - 70 + 190 - 34
= 120 + 156
= 276 tracks
The advantages of this algorithm are −
- Reduces unnecessary head movement compared to SCAN.
- Improves response time for requests.
C-LOOK Disk Scheduling
The C-LOOK (circular look) disk scheduling algorithm is an improvement over the C-SCAN algorithm. In C-LOOK, the disk head does not go to the end of the disk if there are no requests in that direction. Instead, it jumps back to the beginning of the disk as soon as it reaches the last request in that direction. This way it reduces unnecessary head movement.
For example, consider the same disk requests arriving in the order: 82, 170, 43, 140, 34, and 190. The initial position of the disk head is at track 70 and the head is moving towards the right. The image below shows how the disk head moves for this request sequence using C-LOOK algorithm.
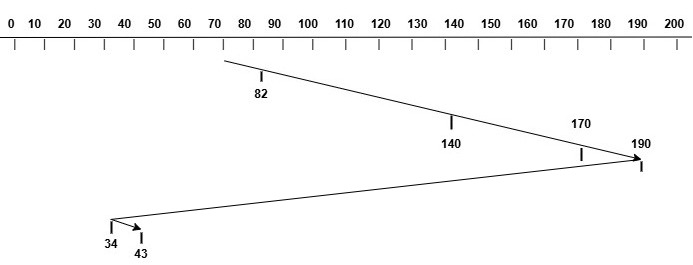
The total head movement can be calculated as follows −
Initial Position of Head = 70
Request Sequence = 82, 170, 43, 140, 34,
Start from 70 and move towards right
Serve 82, 140, 170, 190 (190 - 70 tracks)
Now, jump to the beginning of the disk (190 - 34 tracks)
Now, reverse direction and move towards left
Serve 34, 43 (190 - 34 tracks)
Total Head Movement = 190 - 70 + 190 - 34
= 120 + 156
= 276 tracks
The advantages of this algorithm are −
- Reduces unnecessary head movement compared to C-SCAN.
- Improves response time for requests.
Random Disk Scheduling
The Random Disk Scheduling algorithm selects disk I/O requests any random order. The algorithm will not consider the current head position, seek time, or any other factors while selecting the next request to serve. This is commonly used for testing and comparison purposes rather than in practical applications.
Last-In, First-Out (LIFO) Disk Scheduling
The Last-In, First-Out (LIFO) Disk Scheduling algorithm is just opposite to the FCFS algorithm. In LIFO, the most recently arrived request is served first. This means that the request that came last will be served first, regardless of the current head position or seek time. This algorithm is rarely used in practice due to its potential to cause starvation for older requests.
Goals of Disk Scheduling Algorithms
The main goals of disk scheduling algorithms are −
- Minimize Seek Time − The algorithms aim to reduce the total seek time by optimizing the movement of the disk head.
- Minimize Rotational Latency − The algorithms try to minimize the rotational latency by efficiently scheduling the requests.
- Improve Throughput − The algorithms aim to increase the number of I/O operations that can be completed in a given time period.
- Fairness − The algorithms needs to ensure that all requests are served in a fair manner.
Conclusion
Disk scheduling algorithms decide the order in which disk I/O requests of a computer's disk are processed. We have six commonly used disk scheduling algorithms - FCFS, SSTF, SCAN, C-SCAN, LOOK, and C-LOOK. The other two algorithms - Random and LIFO are rarely used in practice. Each algorithm follows a specific strategy which will be suitable for different scenarios. Generally, SCAN and C-SCAN are preferred in most systems due to their balance between performance and fairness. The most optimized algorithm is SSTF as it follows a greedy approach to minimize seek time. However, it can lead to starvation for some requests.
