- OS - Home
- OS - Overview
- OS - History
- OS - Evolution
- OS - Functions
- OS - Components
- OS - Structure
- OS - Architecture
- OS - Services
- OS - Properties
- Process Management
- Processes in Operating System
- States of a Process
- Process Schedulers
- Process Control Block
- Operations on Processes
- Process Suspension and Process Switching
- Process States and the Machine Cycle
- Inter Process Communication (IPC)
- Remote Procedure Call (RPC)
- Context Switching
- Threads
- Types of Threading
- Multi-threading
- System Calls
- Scheduling Algorithms
- Process Scheduling
- Types of Scheduling
- Scheduling Algorithms Overview
- FCFS Scheduling Algorithm
- SJF Scheduling Algorithm
- Round Robin Scheduling Algorithm
- HRRN Scheduling Algorithm
- Priority Scheduling Algorithm
- Multilevel Queue Scheduling
- Lottery Scheduling Algorithm
- Starvation and Aging
- Turn Around Time & Waiting Time
- Burst Time in SJF Scheduling
- Process Synchronization
- Process Synchronization
- Solutions For Process Synchronization
- Hardware-Based Solution
- Software-Based Solution
- Critical Section Problem
- Critical Section Synchronization
- Mutual Exclusion Synchronization
- Mutual Exclusion Using Interrupt Disabling
- Peterson's Algorithm
- Dekker's Algorithm
- Bakery Algorithm
- Semaphores
- Binary Semaphores
- Counting Semaphores
- Mutex
- Turn Variable
- Bounded Buffer Problem
- Reader Writer Locks
- Test and Set Lock
- Monitors
- Sleep and Wake
- Race Condition
- Classical Synchronization Problems
- Dining Philosophers Problem
- Producer Consumer Problem
- Sleeping Barber Problem
- Reader Writer Problem
- OS Deadlock
- Introduction to Deadlock
- Conditions for Deadlock
- Deadlock Handling
- Deadlock Prevention
- Deadlock Avoidance (Banker's Algorithm)
- Deadlock Detection and Recovery
- Deadlock Ignorance
- Resource Allocation Graph
- Livelock
- Memory Management
- Memory Management
- Logical and Physical Address
- Contiguous Memory Allocation
- Non-Contiguous Memory Allocation
- First Fit Algorithm
- Next Fit Algorithm
- Best Fit Algorithm
- Worst Fit Algorithm
- Buffering
- Fragmentation
- Compaction
- Virtual Memory
- Segmentation
- Paged Segmentation & Segmented Paging
- Buddy System
- Slab Allocation
- Overlays
- Free Space Management
- Locality of Reference
- Paging and Page Replacement
- Paging
- Demand Paging
- Page Table
- Page Replacement Algorithms
- Second Chance Page Replacement
- Optimal Page Replacement Algorithm
- Belady's Anomaly
- Thrashing
- Storage and File Management
- File Systems
- File Attributes
- Structures of Directory
- Linked Index Allocation
- Indexed Allocation
- Disk Scheduling Algorithms
- FCFS Disk Scheduling
- SSTF Disk Scheduling
- SCAN Disk Scheduling
- LOOK Disk Scheduling
- I/O Systems
- I/O Hardware
- I/O Software
- I/O Programmed
- I/O Interrupt-Initiated
- Direct Memory Access
- OS Types
- OS - Types
- OS - Batch Processing
- OS - Multiprogramming
- OS - Multitasking
- OS - Multiprocessing
- OS - Distributed
- OS - Real-Time
- OS - Single User
- OS - Monolithic
- OS - Embedded
- Popular Operating Systems
- OS - Hybrid
- OS - Zephyr
- OS - Nix
- OS - Linux
- OS - Blackberry
- OS - Garuda
- OS - Tails
- OS - Clustered
- OS - Haiku
- OS - AIX
- OS - Solus
- OS - Tizen
- OS - Bharat
- OS - Fire
- OS - Bliss
- OS - VxWorks
- Miscellaneous Topics
- OS - Security
- OS Questions Answers
- OS - Questions Answers
- OS Useful Resources
- OS - Quick Guide
- OS - Useful Resources
- OS - Discussion
Operating System - Solution to Process Synchronization Problem
The process synchronization refers to process of coordinating multiple processes in such a way that they can run without interfering with each other. When multiple processes access shared resources concurrently, it may lead to data inconsistency and unexpected results. To solve these issues, various synchronization mechanisms have been developed.
We have four types of solutions to the process synchronization problem −
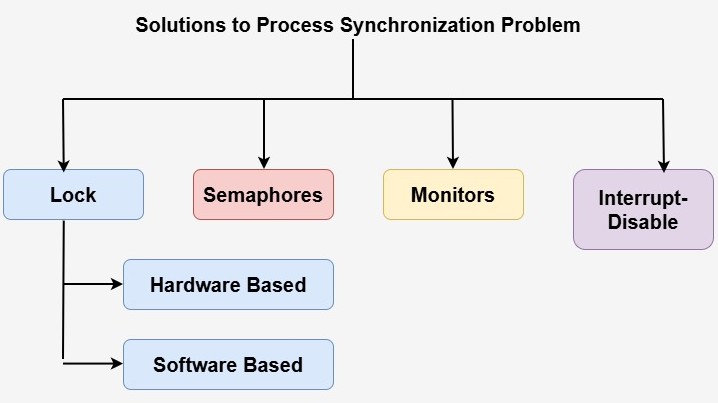
Locks for Process Synchronization
Locks are one of the simplest and most commonly used synchronization mechanisms. A lock is a data structure that allows only one process to access a shared resource at a time. When a process wants to access a shared resource, it must first get the lock associated with that resource. If the lock is already held by another process, the requesting process will be blocked until the lock is released.
Locks can be implemented using two techniques −
1. Software Based Locks
The software-based locks use algorithms to ensure mutual exclusion. They use flags, turn variables, or tickets to manage access to critical sections. For example, a turn variable can be used to indicate whose turn it is to enter the critical section.
Following are some common software-based lock algorithms −
- Peterson's Algorithm − A classic algorithm for achieving mutual exclusion between two processes.
- Test-and-Set Lock − A simple lock that uses a single atomic instruction to test and set a lock variable.
- Dekker's Algorithm − More complex version of Peterson's algorithm that also works for two processes.
- Bakery Algorithm − A token based implementation system for more than two processes.
2. Hardware Based Locks
Hardware-based locks use special CPU instructions to ensure mutual exclusion. These instructions are atomic, meaning they cannot be interrupted. Common hardware-based lock instructions include −
- Test-and-Set − An atomic instruction that tests a lock variable and sets it if it is free.
- Compare-and-Swap − An atomic instruction that compares the value of a variable to an expected value and swaps it with a new value if they match.
- Fetch-and-Add − An atomic instruction that fetches the current value of a variable and adds a specified value to it.
The atomic instructions are indivisible operation. Once an atomic instruction starts, it finishes completely before anything else (like another process or interrupt) can occur. This ensures that no other process can interfere while the atomic instruction is being executed.
A spinlock is a type of lock that uses busy-waiting to acquire the lock. It is typically implemented using atomic instructions like Test-and-Set or Compare-and-Swap. When a process tries to acquire a spinlock, it continuously checks the lock variable until it becomes available.
Note: Semaphores and monitors are called as operating system level synchronization primitives, whereas locks are often implemented at the application level.
Semaphores for Process Synchronization
Semaphores are synchronization mechanism used at the operating system level to control access to shared resources. A semaphore is a non-negative integer variable that is used to signal the availability of resources. There are two types of semaphores −
- Binary Semaphore − A semaphore that can take only two values, 0 and 1. It is used to implement mutual exclusion.
- Counting Semaphore − A semaphore that can take non-negative integer values. It is used to control access to a resource that has multiple instances.
Semaphores support two atomic operations - wait() and signal(). The wait() operation decrements the semaphore value, and if the value becomes negative, the process is blocked. The signal() operation increments the semaphore value, and if there are any processes waiting, one of them is unblocked.
Example
In this example, we create a binary semaphore to control access to a critical section.
#include <iostream>
#include <stdio.h>
#include <semaphore.h>
#include <pthread.h>
sem_t semaphore;
void* process(void* arg) {
sem_wait(&semaphore); // wait operation
// critical section
// Use std::cout in C++
std::cout << "Process " << *(int*)arg << " in critical section" << std::endl;
sem_post(&semaphore); // signal operation
return NULL;
}
int main() {
pthread_t threads[5];
int process_ids[5] = {1, 2, 3, 4, 5};
sem_init(&semaphore, 0, 1); // initialize binary semaphore
for (int i = 0; i < 5; i++) {
pthread_create(&threads[i], NULL, process, &process_ids[i]);
}
for (int i = 0; i < 5; i++) {
pthread_join(threads[i], NULL);
}
sem_destroy(&semaphore);
return 0;
}
The output of the above code will be −
Process 1 in critical section Process 2 in critical section Process 3 in critical section Process 4 in critical section Process 5 in critical section
Monitors for Process Synchronization
Monitors are high-level synchronization mechanism used to manage access to shared resources. A monitor is an abstract data type that encapsulates shared data and the procedures that operate on that data.
In a monitor, only one process can execute a procedure at a time. This way, monitors provide mutual exclusion. Monitors also support condition variables, which allow processes to wait for certain conditions to be met before proceeding.
Interrupt Disable for Process Synchronization
Interrupt Disable is a low-level synchronization mechanism. Here, a process disables all the hardware interrupts before entering its critical section and enables them after exiting the critical section. This way, no any other processes will have access to the hardware resources while the current process is in its critical section.
This method is not suitable for multi-processor systems, because disabling interrupts on one processor does not prevent other processors from accessing shared resources.
Conclusion
We have discussed four types of solutions to the process synchronization problem: locks, semaphores, monitors, and interrupt disable. Locks are used at the application level, while semaphores and monitors are operating system level synchronization primitives. Interrupt disable is a low-level mechanism that can be used only in uni-processor systems. Each of these mechanisms has its own advantages and disadvantages, based on the specific requirements of the system.
