- SAP BW on HANA - Home
- SAP BW on HANA - Overview
- SAP BW Basics
- SAP HANA Basics
- SAP BW on HANA - Architecture
- SAP BW on HANA - Benefits
- Native HANA Modeling
- BW Data Warehousing
- BW Database Version
- SAP BW on HANA - Modeling Tools
- SAP BW on HANA - Migration
- SAP BW on HANA - Migration Tools
- SAP BW on HANA - Data Mngmt
- HANA Optimized InfoCubes
- Composite Providers
- Composite Providers in HANA
- SAP BW on HANA - Advanced DSOs
- SAP BW on HANA - Hybrid Modeling
- HANA Views for BW InfoProviders
- SAP BW on HANA - HANA Live
- Data Provisioning
- SLT Replication HANA
- SLT Replication BW
- DB Connect
- HANA View for InfoCube
- SAP BW on HANA - Process Chain
- HANA vs BWA
- SAP BW on HANA - Authorization
- Consultant Responsibilities
SAP BW on HANA - Quick Guide
SAP BW on HANA - Overview
SAP Business Warehouse (BW) powered by SAP HANA helps you speed up data analysis by consuming data via a Data Warehouse (DW) for analytical reporting and data analysis. You can achieve key opportunities like real-time data integration and data modeling, and hence real-time BI reporting on large amount of data in the database.
SAP Business Warehouse continues to act like a powerful data warehouse tool to consolidate master data and provide flexible reporting options. With SAP HANA underneath BW system as a database, you can use a combination of DW capabilities with fast in-memory database to achieve performance improvements and exceptional modeling capabilities.
HANA in-memory database is much faster as compared to other common databases like Oracle, SQL Server, and hence DW performs much faster when powered by HANA as database underneath it. It combines the power of both the tools - BW Modeling and HANA in-memory computing engine to process huge amounts of data.
BW on HANA supports various exceptional databases and reporting capabilities that are not possible using other databases - like transformations and DSOs are moved to HANA database to provide much faster processing of data, data load performance, query processing and optimization, exceptional HANA modeling capabilities, etc.
Drawbacks of Using SAP BW with Other Databases
Following are the drawbacks when you use SAP BW with other databases such as Oracle, SQL Server, and IBM DB2.
Real-time Reporting − Using BW with other databases, you cant perform realtime reporting as real-time data is not available in the data warehouse. Data is moved to Business Warehouse in batches and hence is not available for real-time reporting.
Implementing Structural Changes − To implement any structure changes, it is very time consuming and a tough task as compatibility is not available with other DB vendors. To implement any structure changes in Business Warehouse, it takes 2-12 months time.
Report Performance − You have to perform report performance optimization and tuning for each application.
Compatibility − Data in Business Warehouse is aggregated and materialized and you cant get the data at different granularity level. HANA supports aggregations on the fly when the report is executed.
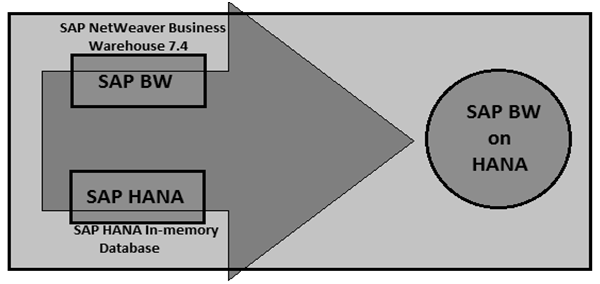
As mentioned, HANA is much faster as compared to other databases like Oracle and SQL Server. Hence, when you combine HANA capabilities with BW, you get an exceptional data processing and reporting features.
BW on HANA Key Customers
As per SAP, organizations of all sizes and industries around the world are using the power of SAP HANA platform to transform their business and create new value. It includes a list of companies from all domains and regions who have adapted HANA as database and used in-memory power of HANA database with BW data warehouse features.
Procter and Gamble
Procter & Gamble has adapted to SAP BW on HANA with the following business transformations.
Reliable, real-time reporting and Better Business Decisions with SAP Software and Services.
55% database reduction from 36 TB to 16 TB.
400% increase in data loading speeds.
35,000 business users supported.
CenterPoint Energy
CenterPoint Energy uses SAP HANA as the foundation to realize their strategic vision.
10 minutes to create marketing targets, down from four weeks.
200% increase in productivity by replacing manual data replications with scheduled data loads into SAP HANA.
98.8% faster predictive analytics engine runtime (from 90 seconds to 1 second).
15% more calls handled by IVR rather than by agents.
Adidas
Adidas leveraging SAP HANA platform stays ahead of consumer demand utilizing SAP Fashion Management application.
Complete visibility from the factory to the shop floor and e-commerce channels.
Point of sale data analysis that provides a better understanding of consumers.
Significantly faster nightly replenishment and allocation runs.
BW on HANA: Important Transactions
Following are the key transaction codes to be used in BW on HANA system.
RSA1 − To open BW workbench
RSMIGRHANADB − To convert in-memory optimized BW
SM59 − To configure RFC connection for SLT
Ltr − To configure Trusted RFC
RSPCM − To monitor periodic process chains
RSPC − To view the log for runs of a process chain
RSLIMO − BW Lean Modeler Test UI
SAP BW on HANA - BW Basics
SAP BW integrates data from different sources, transforms and consolidates the data, performs data cleansing, and stores data. SAP BW also includes data modeling, administration and staging area.
Data in SAP BW is managed with the help of a centralized tool known as SAP Business Intelligence (BI) Administration Workbench. The BI platform provides infrastructure and functions to include −
- OLAP Processor
- Metadata Repository
- Process Designer and other functions
Business Explorer (BEx) is a reporting and analysis tool that supports query, analysis, and reporting functions in BI. Using BEx, you can analyze historical and current data to different degree of analysis.
SAP BW is known as open, standard-based tool which allows you to extract data from different systems to BI system. It evaluates the data with different reporting tools and you can distribute this to other systems.
When you go to SAP BI Administration workbench, the source system is defined there. Go to RSA1 → Source Systems.

As per the type of data source, you can differentiate source systems −
- Data Sources for transaction data
- Data Sources for master data
- Data sources for hierarchies
- Data sources for text
- Data Sources for attributes
You can load the data from any source in the data source structure into BI with an InfoPackage. The target system where the data is to be loaded is defined in the transformation.
DataStore Object
DataStore Object (DSO) is known as a storage place to keep cleansed and consolidated transaction or master data at lowest granularity level. This data can be analyzed using BEx query.
A DSO contains key figures and characteristic fields. Data from DSO can be updated using Delta update or other DataStore objects or master data. DSOs are commonly stored in two-dimensional transparent database tables.
DSO Architecture
DSO component consists of three tables −
Activation Queue
This is used to store the data before it is activated. The key contains request id, package id, and record number. Once activation is complete, the request is deleted from the activation queue.
Active Data Table
This table is used to store the current active data and it contains the semantic key defined for data modeling.
Change Log
When you activate the object, changes to active data are stored in the change log. Change log is a PSA table and is maintained in Administration Workbench under PSA tree.
InfoCube
InfoCube is defined as a multidimensional dataset, which is used for analysis in a BEx query. An InfoCube consists of a set of relational tables which are logically joined to implement star schema. A Fact table in star schema is joined with multiple dimension tables.
You can add data from one or more InfoSource or InfoProviders to an InfoCube. They are available as InfoProviders for analysis and reporting purposes.
InfoCube Structure
An InfoCube is used to store the data physically. It consists of a number of InfoObjects that are filled with data from staging. It has the structure of a star schema.
The real-time characteristic can be assigned to an InfoCube. Real-time InfoCubes are used differently than standard InfoCubes.
SAP BW on HANA - HANA Basics
HANA database takes advantage of in-memory processing to deliver the fastest dataretrieval speed, which is enticing for organizations struggling with high-scale online transactions or timely forecasting and planning.
Disk-based storage is still the enterprise standard and the price of RAM has been declining steadily. Thus, memory-intensive architectures will eventually replace slow, mechanical spinning disks and will lower the cost of Data storage.
In-memory column based storage provides data compression up to 11 times, reduces the space to store huge amount of data.
The speed advantages offered by RAM storage system are further enhanced by the use multi-core CPUs multiple CPUs per node and multiple nodes per server in the distributed environment.
Getting Started with SAP HANA Studio
SAP HANA studio is an Eclipse-based tool that runs on development environment and administration tool for working on HANA.
SAP HANA studio is both the central development environment and the main administration tool for HANA system. It is a client tool which can be used to access local or remote HANA system.
It provides an environment for HANA Administration, HANA Information Modeling and Data Provisioning in HANA database.
SAP HANA Studio can be used on the following platforms −
Microsoft Windows 32 and 64 bit versions of: Windows XP, Windows Vista, Windows 7
SUSE Linux Enterprise Server SLES11: x86 64 bit
However, in Mac OS, HANA studio client is not available.
Depending on HANA Studio installation, all features may not be available. At the time of Studio installation, specify the features you want to install as per the role. To work on the most recent version of HANA studio, Software Life Cycle Manager can be used for client update.
SAP HANA Studio AFeatures
SAP HANA Studio provides a perspective to work on the following HANA features. You can choose the Perspective in HANA Studio using the following path, HANA Studio → Window → Open Perspective → Other
SAP HANA Studio Administration
The toolset for various administration tasks, excluding transportable design-time repository objects. General troubleshooting tools like tracing, the catalog browser, and SQL Console are also included.
SAP HANA Studio Database Development
It provides the toolset for content development. It addresses, in particular, the DataMarts and ABAP on SAP HANA scenarios, which does not include SAP HANA native application development.
SAP HANA Studio Application Development
SAP HANA system contains a small Web server which can be used to host small applications. It provides the toolset for developing SAP HANA native applications, like application code written in Java and HTML.
By default, all features are installed.
HANA Studio Administration View
To perform HANA Database Administration and monitoring features, SAP HANA Administration Console Perspective can be used.
Administrator Editor can be accessed in the following ways −
From System View Toolbar − Choose Open Administration default button
In System View − Double-click HANA System or Open Perspective
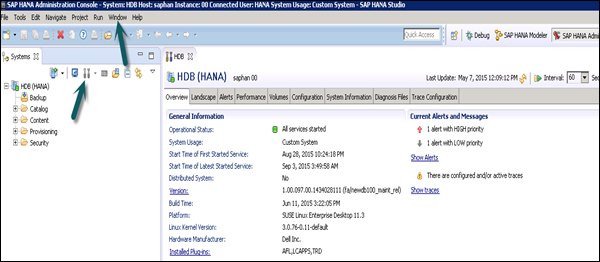
In the Administration view, HANA studio provides multiple tabs to check the configuration and health of the HANA system. The Overview tab provides General Information such as: the operational status, the start time of the first and last started service, the version, the build date and time, the platform, the hardware manufacturer, etc.
Adding a HANA System to Studio
One or multiple systems can be added to HANA studio for Administration and Information modeling purposes. To add a new HANA system, the host name, the instance number, and the database username and password is required.
- Port 3615 should be open to connect to Database
- Port 31015 Instance No 10
- Port 30015 Instance No 00
- SSh port should also be open
Following are the steps to add a System to HANA studio −
Step 1 − Right-click in the Navigator space and click Add System. Enter HANA system details, i.e. the host name and the instance number. Click next.
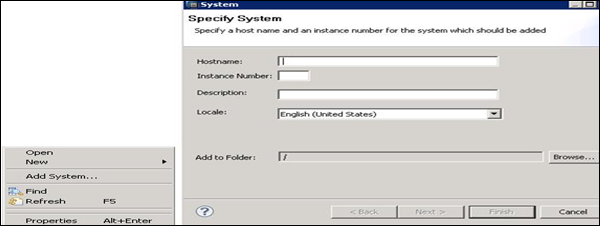
Step 2 − Enter the database username and password to connect to SAP HANA database. Click Next and then Finish.
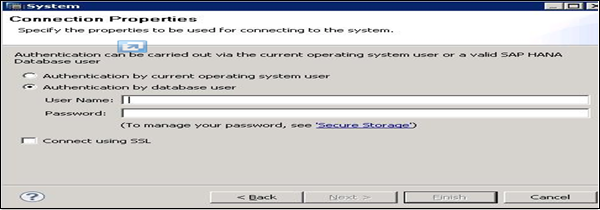
Once you click Finish, HANA system will be added to System View for administration and modeling purposes. Each HANA system has two main sub-nodes, Catalog and Content.
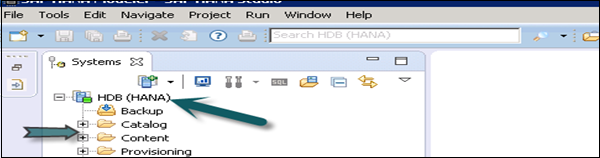
Catalog − It contains all available Schemas, i.e. all data structures, tables and data, column views, and procedures, which can be used in the Content tab.
Content − The Content tab contains design time repository, which holds all information of data models created with the HANA Modeler. These models are organized in Packages. The Content node provides different views on the same physical data.
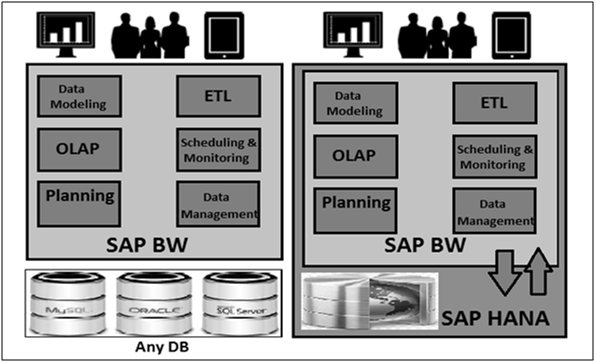
SAP BW on HANA - Architecture
When SAP BW is powered by HANA, all the tasks are performed using HANA database optimized techniques. SAP HANA is responsible to perform key tasks related to Data Warehousing delivering excellent performance while performing analytical reporting.
In the following figure, you can see BW on HANA architecture where all the key activities of BW are HANA optimized −
- HANA-Optimized Data Modeling: InfoCubes
- HANA-Optimized Data Modeling: Advanced DataStore Objects
- HANA-Optimized Data Modeling: Composite Providers
- HANA-Optimized Data Staging
- HANA-Optimized Analytic Manager
- HANA-Optimized Analysis Processes
Layered Scalable Architecture (LSA and LSA++)
In SAP BW, LSA makes it more robust, flexible, and scalable solution to perform enterprise data warehousing functions. LSA is the corporate framework for BW to reliably manage the entire data and metadata life cycle −
- Data delivery
- Data modeling
- Data staging
- Authorizations
- Solution delivery
When BW is implemented on SAP HANA, you can create a different LSA which is more dependent on virtual objects. This is known as LSA++ and it consists of three key layers −
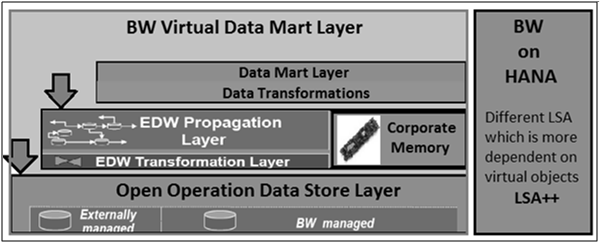
Open Operation Data Store Layer
This layer is similar to the data acquisition layer in SAP BW. The open ODS layer is used to integrate data into the Data Warehouse and provides the same functionality as the classic data acquisition layer, but with more flexible data integration possibilities.
Core Data Warehouse Layer
This layer is responsible to perform functions like data transformation, data cleansing and consolidation.
Virtual Data Mart Layer
This layer is responsible to combine the data from other layers and to make it available for reporting purposes. This layer contains all the InfoProviders that combine data using join or union, without saving the result: MultiProvider, Composite Provider, etc. You can use this to access data directly in the SAP HANA database, to allow queries on Composite Provider, Open ODS View.
Composite provider allows you to merge the data from BW InfoProviders with HANA Modeling views. Union and Joins are performed in SAP HANA and queries can be run on composite providers, like BW InfoProviders.
SAP BW on HANA - Benefits
Using BW powered by SAP HANA, you can find the following benefits −
Excellent performance in analytical reporting and data loading using HANA in memory database capabilities. All BW functions performed in SAP HANA benefits from in-memory database and calculation engines for faster data processing.
With HANA optimized objects, you can perform complex queries, detailed analysis, high data volume, and aggregations efficiently.
All existing BI tools such as BEx, Business Objects BI reporting tools, and Microsoft Excel are directly supported by SAP BW on HANA.
SAP HANA provides high level of data compression. Column storage of tables requires less storage type and hence provides lower Total Cost of Ownership (TCO).
Business Warehouse Accelerator (BWA) is not required while using HANA underneath BW.
You dont need aggregated tables and HANA supports on-the-fly aggregations.
It has simplified data modeling by using in-memory-optimized objects. There is no need to load BWA index.
When you use SAP BW on HANA, the following processes are not required −
Rolling Up Filled Aggregates
Filling of New aggregates
Adjust Time-Dependent Aggregates
Construct Database Statistics
Build Index
Delete Index
SAP BW on HANA - Native HANA Modeling
SAP HANA Modeler option is used to create information views on the top of schemas → tables in HANA database. These views are consumed by JAVA/HTML based applications or SAP Applications such as SAP Lumira, Office Analysis, or third party software like MS Excel for reporting purposes to meet business logic and to perform analysis and extract information.
HANA Modeling is done on the top of tables available in Catalog tab under Schema in HANA Studio and all views are saved under the Content table under Package.
You can create a new Package under the Content tab in HANA Studio using right-click on Content and New.
All Modeling Views created inside one package comes under the same package in HANA Studio and is categorized according to the View Type.
Each View has a different structure for Dimension and Fact tables. Dimension tables are defined with master data. Fact table has a Primary Key for dimension tables and measures like Number of Unit sold, Average delay time, Total Price, etc.
You can create a new Package by a right-click on the Content Tab → New → Package.
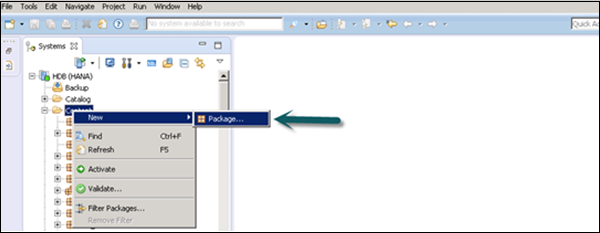
You can also create a Sub Package under a Package by a right-click on the Package name. When we right click on the Package, we get 7 options. We can create HANA Views Attribute Views, Analytical Views, and Calculation Views under a Package.
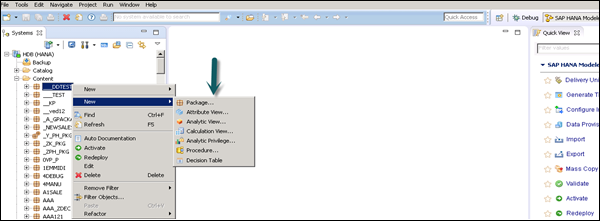
You can also create a Decision Table, define an Analytic Privilege and create Procedures in a Package.
When you right-click on Package and click New, you can also create sub packages in a Package. You have to enter Package Name, Description while creating a Package.
SAP HANA Attribute View
Attribute Views in SAP HANA Modeling are created on the top of Dimension tables. They are used to join Dimension tables or other Attribute Views.
You can also copy a new Attribute View from an already existing Attribute Views inside other Packages but that doesnt let you change the View Attributes.
Following are few characteristics of an Attribute View in SAP HANA −
Attribute Views in HANA are used to join Dimension tables or other Attribute Views.
Attribute Views are used in Analytical and Calculation Views for analysis to pass the master data.
They are similar to characteristics in BM and contain master data.
Attribute Views are used for performance optimization in large size dimension tables. You can limit the number of attributes in an Attribute View, which are further used for Reporting and analysis purpose.
Attribute Views are used to model master data to give some context.
Create an Attribute View
Choose the Package name under which you want to create an Attribute View. Right-click on Package → Go to New → Attribute View.
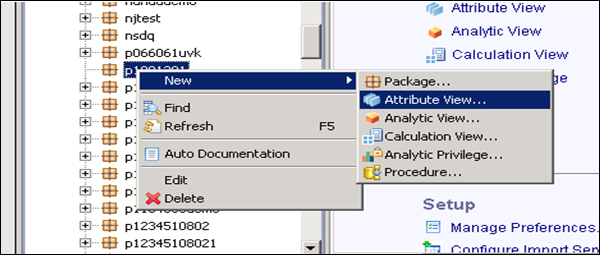
When you click on Attribute View, a New Window will open. Enter Attribute View name and Description. Then, from the dropdown list, choose View Type and subtype. In subtype, there are 3 types of Attribute views: Standard, Time, and Derived.
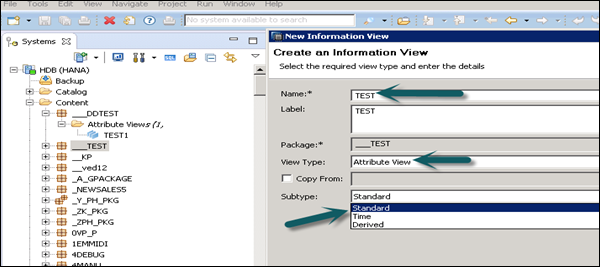
Time subtype Attribute View is a special type of Attribute view that adds a Time Dimension to Data Foundation. When you enter the Attribute name, Type and Subtype and click Finish, it will open three work panes −
Scenario pane that has Data Foundation and Semantic Layer.
Details pane shows the attribute of all tables added to Data Foundation and the joining between them.
Output pane where we can add attributes from the Detail pane to filter in the report.
You can add Objects to Data Foundation by clicking the + sign written next to Data Foundation. You can add multiple Dimension tables and Attribute Views in the Scenario Pane and join them using a Primary Key.
When you click on Add Object in Data Foundation, you will get a search bar from where you can add Dimension tables and Attribute views to the Scenario Pane. Once Tables or Attribute Views are added to Data Foundation, they can be joined using a Primary Key in the Details Pane as shown in the following screenshot.
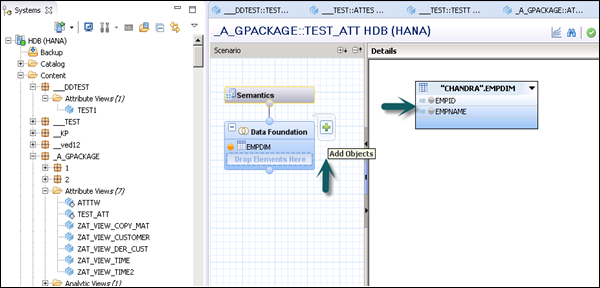
Once the join is complete, choose multiple attributes in the Details pane, right-click and Add to Output.
All columns will be added to the Output pane. Click the Activate option and you will get a confirmation message in the job log.
Now you can right-click on the Attribute View and go for Data Preview.
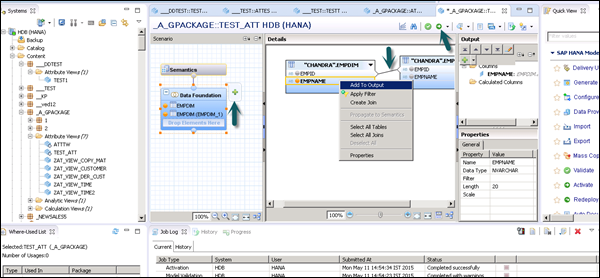
Note − When a View is not activated, it has a diamond mark on it. However, once you activate it, that diamond disappears which confirms that the View has been activated successfully.
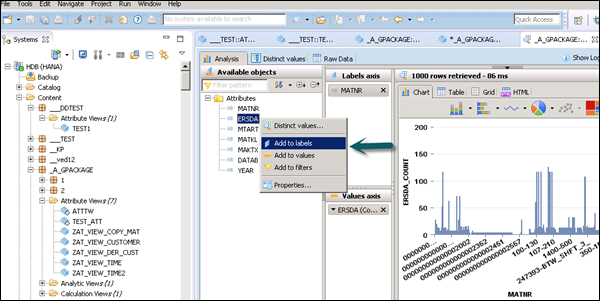
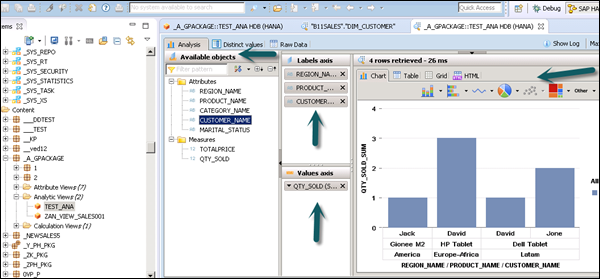
Once you click Data Preview, it will show all the attributes that has been added to the Output pane under Available Objects.
You can right-click and add to Labels and Value axis or simply drag the objects as shown in the following screenshot.
SAP HANA Analytic View
Analytic View is in the form of Star Schema where we join one Fact table to multiple Dimension tables. Analytic views use real power of SAP HANA to perform complex calculations and aggregate functions by joining the tables in the form of Star Schema and by executing Star schema queries. Following are a few properties of SAP HANA Analytic View −
Analytic Views are used to perform complex calculations and Aggregate functions like Sum, Count, Min, Max, etc.
Analytic Views are designed to run Start Schema queries.
Each Analytic View has one Fact table surrounded by multiple dimension tables. Fact table contains a primary key for each Dimension table and measures.
Analytic Views are similar to Info Objects and Info sets of SAP BW.
Create an Analytic View
Choose the Package name under which you want to create an Analytic View. Right-click on Package → Go to New → Analytic View. When you click on an Analytic View, a new window will open. Enter the View name and Description. From the dropdown list, choose the View Type and click Finish.
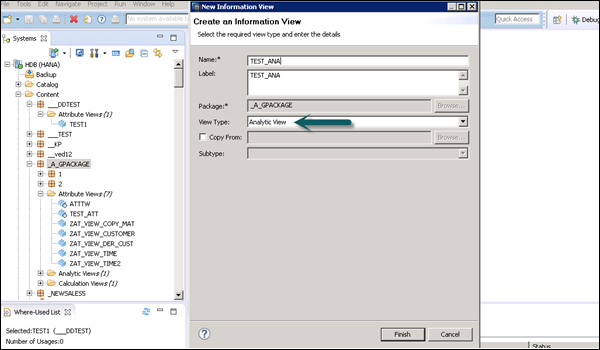
When you click Finish, you can see an Analytic View with Data Foundation and Star Join option.
Click Data Foundation to add Dimension and Fact tables. Click Star Join to add Attribute Views.
Add Dimension and Fact tables to Data Foundation using + sign. In the following example, 3 dimension tables have been added DIM_CUSTOMER, DIM_PRODUCT, DIM_REGION, and 1 Fact table FCT_SALES to the Details Pane. Joining the Dimension table to Fact table using Primary Keys is stored in Fact table.
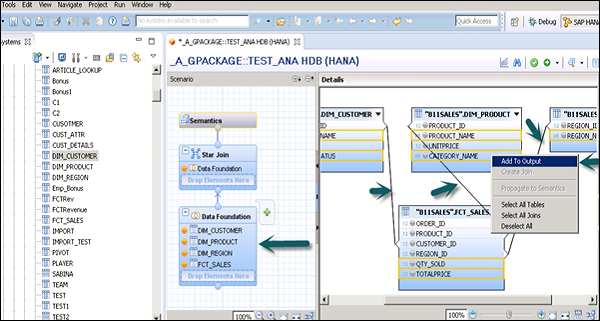
Select Attributes from Dimension and Fact table to add to the Output pane as shown in the above screenshot. Now, change the data type of Facts from the Fact table to measures.
Click the Semantic layer, choose facts and click the measures sign as shown in the following screenshot to change datatype to measures, and activate the view.
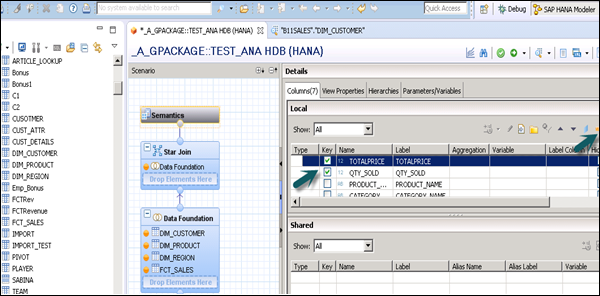
Once you activate the view and click Data Preview, all attributes and measures will be added under the list of available objects. Add attributes to the Labels Axis and measure to the Value Axis for analysis purpose.
There is an option to choose different types of chart and graphs.
SAP HANA Calculation View
Calculation View is used to consume other analytic, attribute, and other calculation views and base column tables. These are used to perform complex calculations which are not possible with other types of Views. Following are a few characteristics of Calculation View −
Calculation View is used to consume Analytic, Attribute, and other Calculation Views.
They are used to perform complex calculations which are not possible with other Views.
There are two ways to create Calculation Views - SQL Editor or Graphical Editor.
Built-in Union, Join, Projection and Aggregation nodes.
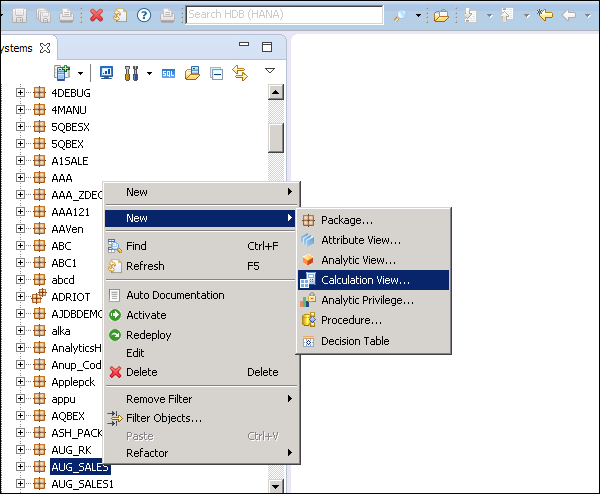
Create a Calculation View
Choose the Package name under which you want to create a Calculation View. Right-click on Package → New → Calculation View. When you click on Calculation View, a new window will open.
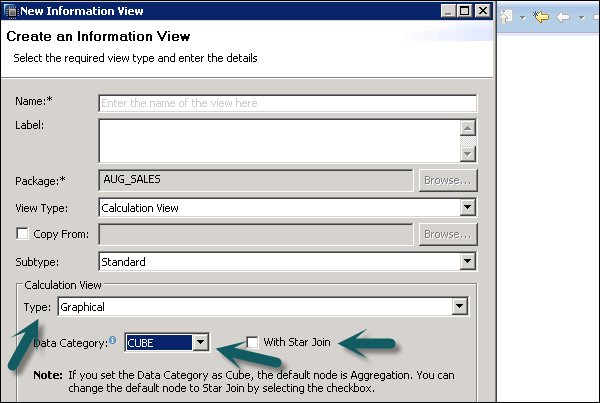
Enter the View name, Description and choose the View type as Calculation View, Subtype Standard or Time (this is special kind of View which adds time dimension). You can use two types of Calculation View: Graphical and SQL Script.
Graphical Calculation Views − It has default nodes like aggregation, Projection, Join and Union. It is used to consume other Attribute, Analytic, and other Calculation views.
SQL Script based Calculation Views − It is written in SQL scripts that are built on SQL commands or HANA defined functions.
Data Category − Cube, in this default node is Aggregation. You can choose Star join with Cube dimension. Dimension, in this default node is Projection.
You can check for more details on native HANA modeling in our SAP HANA Tutorial.
SAP BW on HANA - BW Data Warehousing
BI objects is divided into multiple BI content areas so that they can be used in an efficient way. This includes the content area from all the key modules in an organization - SCM, CRM, HR, Finance Management, Product Lifecycle, Industry solutions, Non-SAP data sources, etc.
Star Schema and Extended Star Schema
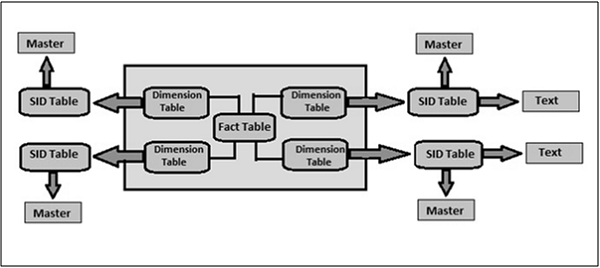
In Extended Star Schema, fact tables are connected to the dimension tables and the dimension table is connected to the SID table. The SID table is connected to the master data tables. In Extended Star Schema, Fact and Dimension tables are inside the cube; however, SID tables are outside the cube. When you load the transactional data into the Info cube, Dim Ids are generated based on SIDs and these Dim ids are used in the fact tables.
In Extended Star Schema, one fact table can connect to 16 dimension tables and each dimension table is assigned with 248 maximum SID tables. SID tables are also called Characteristics and each characteristic can have master data tables like ATTR, Text, etc.
ATTR − It is used to store all the attribute data.
Text − It is used to store description in multiple languages.
InfoArea and InfoObjects
InfoObjects are known as the smallest unit in SAP BI and are used in InfoProviders, DSOs, Multi providers, etc. Each InfoProvider contains multiple InfoObjects.
InfoObjects are used in reports to analyze the data stored and to provide information to decision makers. InfoObjects can be categorized into the following categories −
- Characteristics like customer, product, etc.
- Units like quantity sold, currency, etc.
- Key figures like total revenue, profit, etc.
- Time characteristics like year, quarter, etc.
InfoObjects are created in the InfoObject catalog. It is possible that an InfoObject can be assigned to a different Info Catalog.
InfoArea in SAP BI is used to group similar types of objects together. InfoArea is used to manage InfoCubes and InfoObjects. Each InfoObject resides in an InfoArea and you can define it in a folder which is used to hold similar files together.
Transformation Process
Transformation process is used to perform data consolidation, cleansing and data integration. When data is loaded from one BI object to other BI object, transformation is applied on the data. Transformation is used to convert a field of source into the target object format.
SAP BW on HANA - BW Database Version
SAP BW can run on different databases like Oracle, SQL Server, HANA or any other database. When SAP BW is powered by HANA, you can check in SAP NetWeaver - version of NW and database on which it is installed.
Check on Which Database the BW System is Installed On and its Version
Go to BI on HANA SAP system and login.
To check SAP NetWeaver version and the DB on which it is installed, click System → Status.
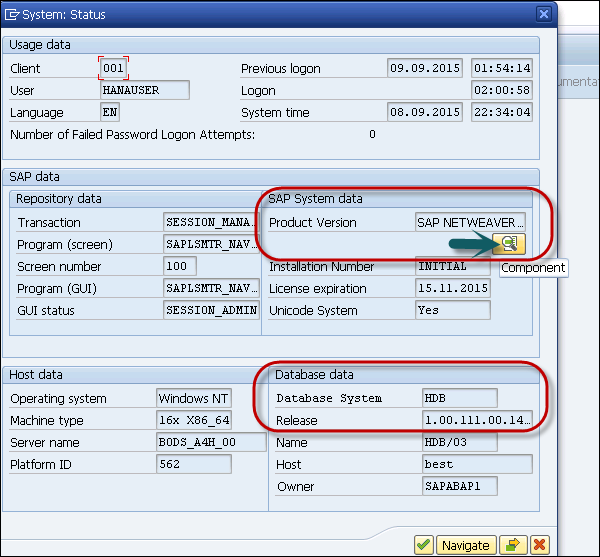
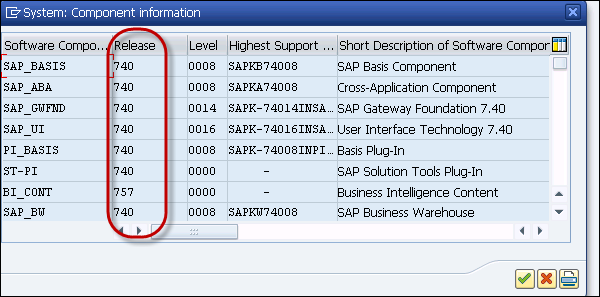
To check the version of SAP NetWeaver system, click the magnifying glass. You can see the Database version - HDB Release 1.0 SPS 11.
SAP BW on HANA - Modeling Tools
You can install BW Modeling tools on your system - SAP GUI, SAP HANA Studio. To install BW modeling tools, you need the following components −
Operating System Windows 7 or Windows 8 or Apple Mac OS X 10.8 or higher, or Linux distribution.
Internet Explorer 7.0 or higher or Firefox 4.0 or higher has to be installed.
SAP GUI for Windows 7.3 or SAP GUI for Windows 7.4 has to be installed on your local drive. You can download this from SAP Marketplace.
To communicate with the backend system, you need Microsoft Runtime DLLs VS2010 (for Windows OS) is installed on your local system.
SAP HANA Studio (32-Bit or 64-Bit for Windows) SP08 or higher.
Create a New BW Project in HANA Studio
Open SAP HANA Studio and create a new project. Go to Windows → Open Perspective → Other.
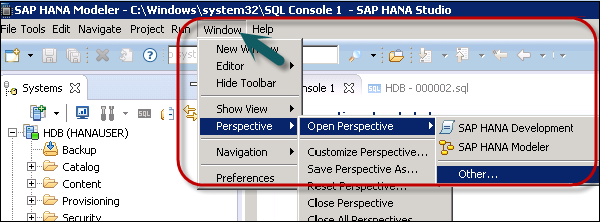
Select BW Modeling → Click OK as shown in the following screenshot.
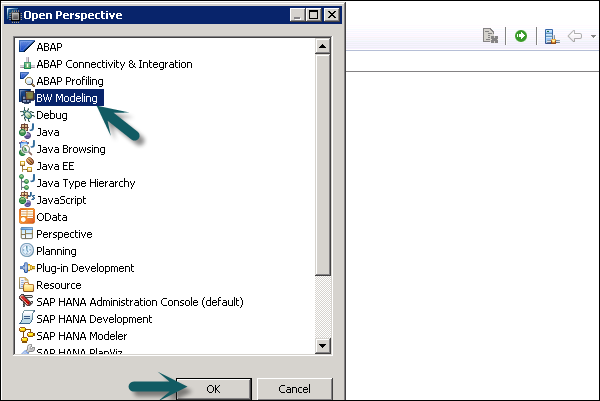
Next go to File → New → Project.
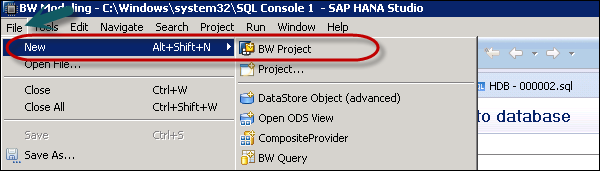
In the next window, select SAP connection. You can select an existing connection or define a connection manually to add a new connection.
System connections are maintained in the SAP Logon. Click Ok.
In the next screen, as shown in the following screenshot enter client, username and password. Click Next.
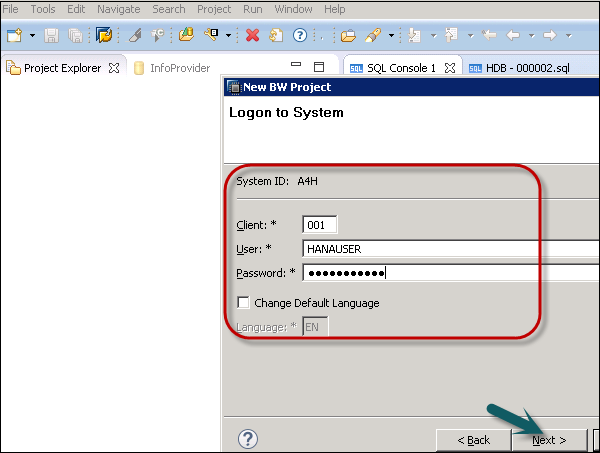
You can enter the project name and click Finish.
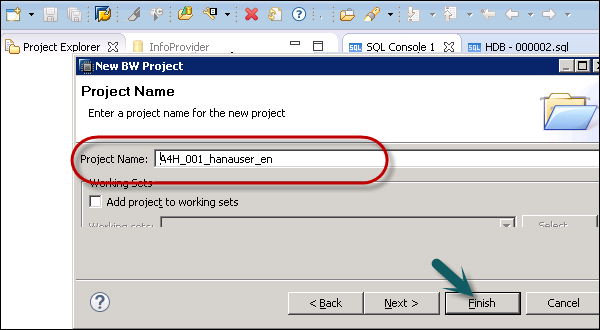
Now, right-click on your new root project folder and choose Attach SAP HANA System. Choose the preconfigured HANA system HDB and click Finish.
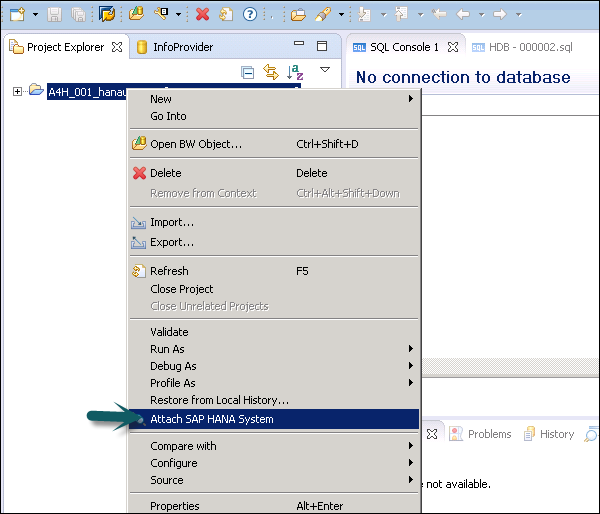
Only connected SAP HANA system can be attached. Select HANA system → Finish.
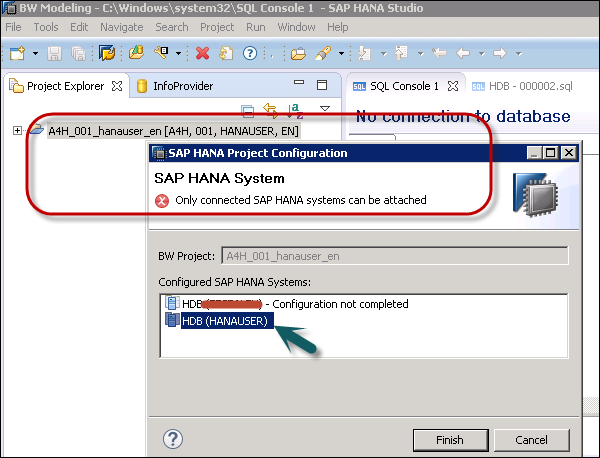
To define a BW query on your InfoCube, select the InfoCube in BW Modeling Perspective, right-click and click New → BW Query and select the InfoProvider.
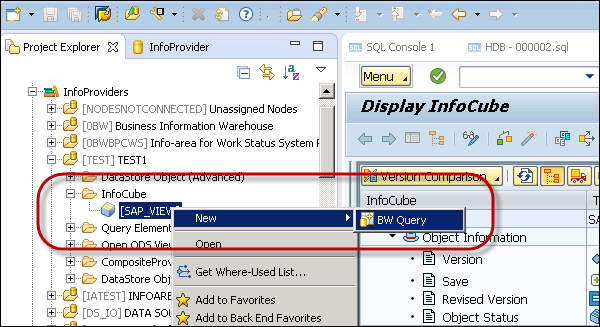
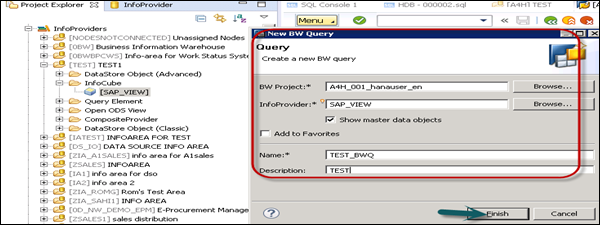
Enter the name and description and click Finish. This is how you can add a BW query.
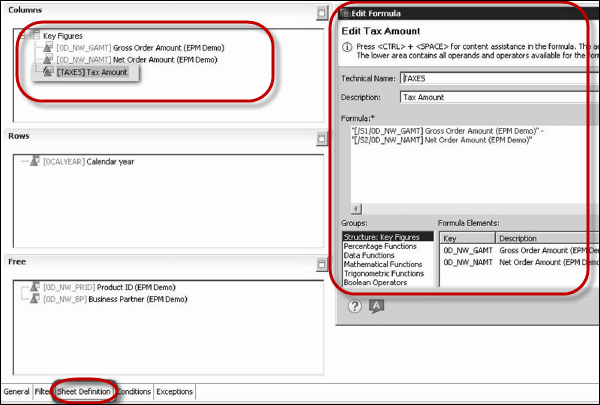
You can apply different functions in BW query. You can apply filters, define local formulas for calculation, etc.
To save a BW query, click the save icon.

To preview your BW query, click the BW Reporting Preview in HANA Studio.
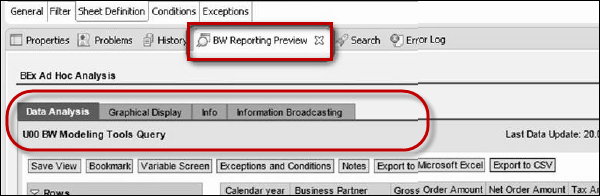
SAP BW on HANA - Migration
When you plan migration of BW system to HANA, you need to perform various checks that help in successful migration. You can refer to different SAP notes that are available on SAP support Launchpad.
Before migration, you need to perform a feasibility check to understand the load process and to see performance improvements. As SAP HANA requires Unicode, you need to perform Unicode conversion if you have a non-Unicode system or you can also plan Unicode conversion as part of the migration.
To perform database migration, you have to perform a hardware check. To migrate BW system to HANA, you have to perform hardware sizing and that can be performed using report /SDF/HANA_BW_SIZING.
To access the complete checklist tool, you can refer SAP Note: 1729988 on support.sap.com. Search a Knowledge base article.
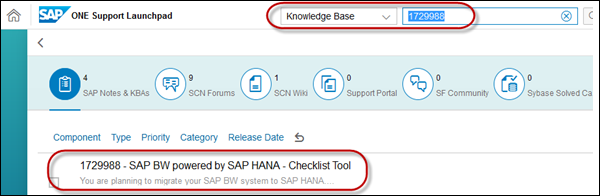
This tool automates the check of best practice guidelines for operations and pre-requisites for migration of an existing SAP BW deployment to the SAP HANA platform.
You can also check the other K-base SAP Notes i.e., refers to, referred by this SAP Note as shown in the following screenshot.
Issues During Migration
While performing SAP HANA migration, you can encounter different types of errors. Following are some SAP Notes that you can refer during the migration process −
SAP Note 1846872 − "No space left on device" error reported from HANA
SAP Note 1787489 − SAP HANA Database: Performance Trace
SAP Note 1786918 − Required information to investigate high memory consumption
SAP Note 1747042 − Providing support access to HANA database instance
SAP Note 1740136 − SAP HANA: wrong mount option may lead to corrupt persistency
SAP Note 1897157 − Install or upgrade failed due to hdbnsutil failure
SAP Note 1894412 − SAP HANA nameserver crash after revision upgrade
SAP Note 1634848 − SAP HANA database service connections
SAP Note 1592925 − SAP HANA Studio service connection
SAP BW on HANA - Migration Tools
To perform the migration of SAP BW system to HANA, you can use the following migration tools −
Software Provisioning Manager
Software Provisioning Manager allows you to perform various provision tasks and covers a broad range of platforms with different productions. Software Provisioning Manager can be used to set up a standalone engine, for migration of systems, or to copy a NetWeaver system.
Software Provisioning Manager 1.0 supports the following provisioning scenarios for SAP systems based on SAP NetWeaver −
- Installation of new systems, instances, and standalone engines
- System copy of existing systems
- Transformation of systems such as via System Rename and Dual-Stack Split
- Deletion of systems, instances, and standalone engines
Software Provisioning Manager 1.0 supports the following SAP NetWeaver releases, SAP Business Suite products, and SAP Solution Manager Releases based on them.
You can get the latest version from the following URL: https://help.sap.com/docs/SOFTWARE_LOGISTICS_TOOLSET?version=1.0
1680045 - Release Note for Software Provisioning Manager 1.0 SP17
SAP BW Migration Cockpit for SAP HANA
This tool is used to get an easy access to the most used and useful tools for migrating your SAP BW systems to and optimizing it for SAP HANA.
The SAP BW Migration Cockpit for SAP HANA combines several tools to make the migration of an existing SAP BW deployment to the SAP HANA platform smooth and easy to perform.
To use the cockpit, install and run ABAP program. In order to use the Check for Updates function, you might have to maintain the proxy settings in lines 21 and 22 of the code.
Program: ZBW_HANA_MIGRATION_COCKPIT
This tool can be used with SAP BW release 3.5 or higher.
To get the tool, you can refer to SAP Notes 1909597 - SAP BW Migration Cockpit for SAP HANA.
Go to the attachment tab and you can download the zip file.
In case any of the tool is not available on your local system, you can refer to the documentation tab and you can access online help and available SAP Notes.
This SAP Note is referred by −
| Number | Title |
|---|---|
| 1729988 | SAP BW powered by SAP HANA - Checklist Tool |
| 1736976 | Sizing Report for BW on HANA |
| 1908367 | SAP BW Transformation Finder |
| 1847431 | SAP BW ABAP Routine Analyzer |
Data Migration Option of SUM
Data Migration Option (DMO) under Software Update Manager (SUM) simplifies the Unicode conversion, system update, and database migration in one tool.
SAP Note 2257362 - Database Migration Option (DMO) of SUM 1.0 SP17
To perform database migration using DMO, SAP HANA version 8.5 or higher is required. Target database SAP HANA depends on the source database with different requirements to perform an upgrade.
| Source Database | Requirements/Restriction |
|---|---|
| Oracle | Oracle version 11.2 or higher |
| MaxDB | MaxDB 7.7: Version 7.7.07.47 or higher MaxDB 7.8: Version 7.8.02.028 or higher MaxDB 7.9 or higher: No restriction Target release SAP_BASIS 740 SP11 not supported |
| MS SQL | MS SQL 2005 (available on request), or a higher version Source SAP release must base on SAP_BASIS 700 or higher |
| DB2 (DB2 for z/OS) | Target release of SAP_BASIS is 740 SP12 or higher |
| DB4 (DB2 for i) |
Source SAP release must base on SAP_BASIS 700 or higher DB4 i7.1 or higher Target SAP release must base on SAP_BASIS 740 SP10 or higher |
| DB6 (DB2 for Linux, UNIX, and Windows) |
DB6 version 09.01.0000 or higher, if target SAP_BASIS release is lower than 740 SP8 DB6 version 09.7 FP5 or higher, if target SAP_BASIS release is 740 SP8 or higher |
| SAP HANA | SAP HANA as source database is not supported |
| SAP |
SAP ASE Version 16.0 SP02 patch level 02 or higher, if target release of SAP_BASIS is 750 or higher According to PAM, if target release of SAP_BASIS is lower than 750 |
SAP BW on HANA - Data Management
When your SAP BW system runs on HANA database, the cost of putting all the data in HANA in-memory is high. Also not all data from SAP BW is required in HANA database and only 30-40% of data from BW is actively required for reporting and operations. This data should only be put to HANA in-memory capabilities.
SAP BW on HANA provides a setting for active and non-active data so that you can manage the lower total cost of ownership. Data can be classified into following 3 categories as per data temperature −
Hot Data
In this area, all data under hot data is stored in HANA in-memory database and is available for reporting and operations. In SAP BW, this is InfoCubes and DSOs that comes under hot data as they are frequently used for reporting and operations.
This data is frequently used and it typically belongs to past 2-3 years and hence this data has to be put as real hot data and has to be put in in-memory database to get the best performance for reporting purposes.
Following are the key properties of hot data −
Access − Very frequent, every few seconds or minutes
Response − Fast access, performance to be high
Data Type − Data from InfoCubes, standard DSOs, open DSOs, and all master data
Cold Data
Cold data is considered as archived data which is rarely accessed and all data is stored on secondary database. In SAP BW, standard DSOs and InfoCubes contain the data for operations and reporting. However, in normal scenario only past few years data is frequently accessed for reporting. Data older than 3 years can be normally stored on lower TCO plan as it is infrequently accessed.
Following are the key properties of cold data −
Access − Data that is older than 3 years and is infrequently accessed for reporting and operations.
Response − Slower as compared to hot and warm data.
Data Type − Older data from InfoCubes and Standard DSOs.
Warm Data
Warm data is the data stored in the disk storage of HANA database and is available for access all the time. This allows you to access less recent data efficiently in HANA database.
This data is available for read, write and insert, and provides lower total cost of ownership.
There are two types of data under warm data −
- Non-Active data
- Active/Dynamic tiering
Non-Active Data
This data type is applied to Persistence Staging Area (PSAs) and Write Optimized (W/O) DSOs. In SAP BW, PSAs and W/O DSOs are considered as low priority object, and in case of memory shortage non-active data is first removed from the memory.
Following are the key properties of non-active data −
Access − Medium frequent data. Data which is accessed more frequently than cold data.
Response − The response is quick when all the partitions are in-memory. When the data is to be loaded to partition, the response time depends on the volume of data.
Data Type − PSAs and W/O DSOs
Note − The Non-active concept is available since SAP BW 7.3 SP8 and you can use it to efficiently manage memory in HANA Database.
Active/Dynamic Tiering
In dynamic tiering, there is no concept of displacing data from partition to low TCO memory and involves an integrated mechanism to access all the data with optimal performance time.
All data - PSAs and W/O DSOs - are stored in the disk and is available for SAP BW 7.4 SP8 and HANA 1.0 SP9 or higher version.
Following are the key properties of active/dynamic tiering data −
Access − Medium frequent data. Data which is accessed more frequently than cold data.
Response − Slightly slower than hot data
Data Type − PSAs, W/O DSOs and Advanced DSOs
Monitor Non-Active Data Concept in SAP BW System
Open active/non-active data monitor, run Transaction Code: RSHDBMON or you can navigate to Administration Workbench → Administration → Monitors → Active/Non-Active data.
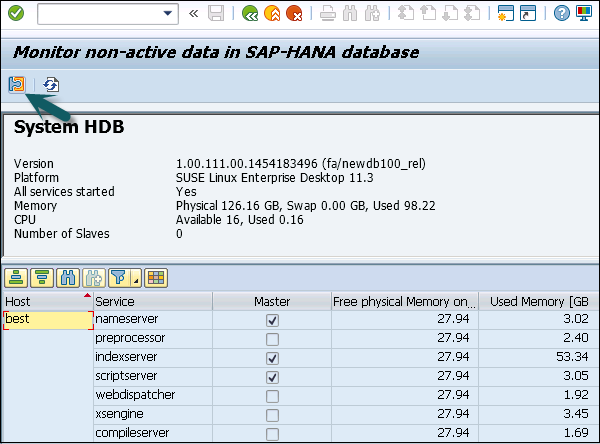
Next is to click the Detailed view to check early unload settings. You can check early unload settings for the following Objects −
- Standard DSOs
- W/O DSOs
- InfoCube
- Data Source
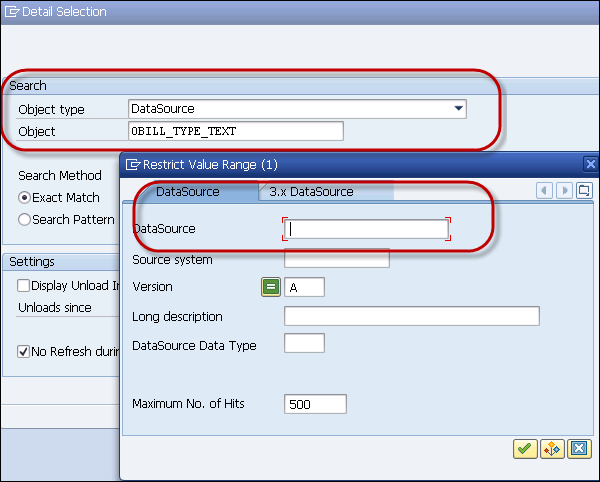
From the data selection, select the data source from the dropdown. Select Object and click Execute.
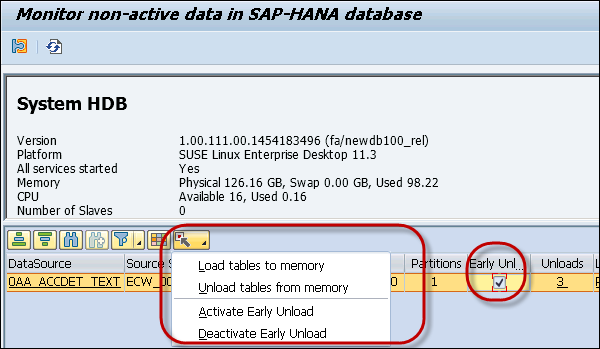
PSA tables and write-optimized DSOs are marked as Warm by SAP in BW by default. It means that the flag is set as active by default.
This allows these tables to be removed from the main memory with higher priority compared to other tables of persistent BW InfoProviders. You can customize this setting using Early Unload flag in the window as shown in the following screenshot.
HANA Optimized InfoCubes
When you use SAP BW on HANA, you can create your existing InfoCubes to HANA Optimized InfoCubes. When InfoCubes are moved to HANA database, they become column-based tables and act like BWA Indexed InfoCubes.
When SAP HANA optimized InfoCubes are used, characteristics and key figures are assigned to dimensions. To improve the system performance, Surrogate IDs (SIDs) are used in fact tables.
When you convert standard InfoCubes to HANA optimized InfoCubes, the layout changes at the time of conversion and it has to be adjusted manually.
To view InfoCubes in the BW system, you can use Transaction: LISTSCHEMA

You can select your InfoCube and check the various dimension tables. Select InfoCube type −
- Aggregate Cube
- Standard InfoCube
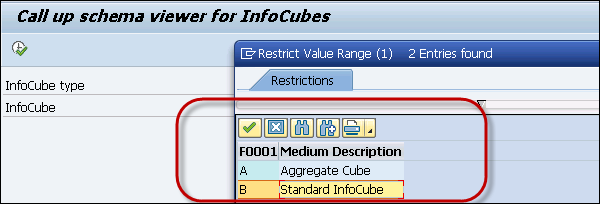
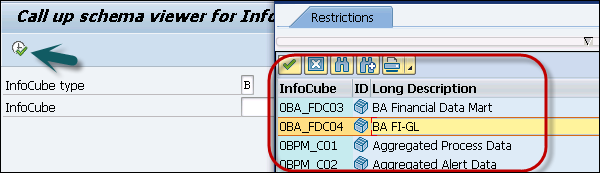
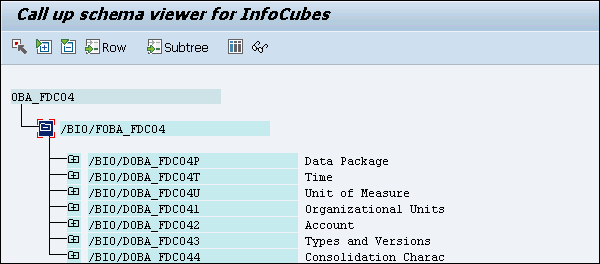
There are two ways to convert standard InfoCube to HANA optimized InfoCube.
Go to InfoCube and click to open the editing screen. Select Conversion to SAP HANA optimized checkbox. You can also check this property under InfoCube properties → Subtype. Open InfoCube and you can see the subtype as HANA optimized InfoCube.
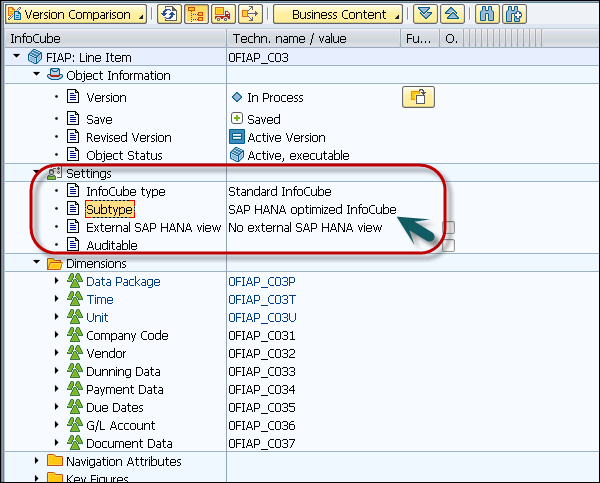
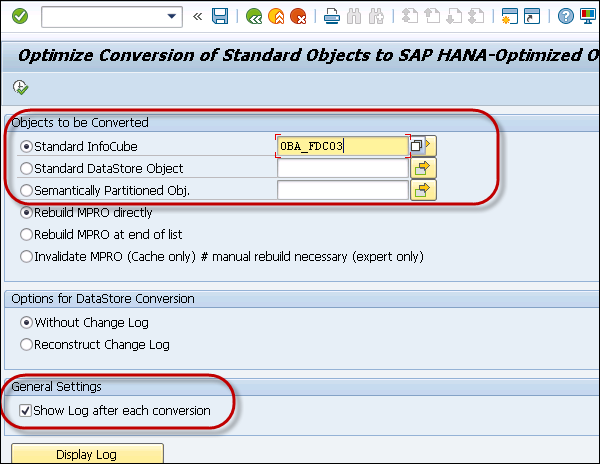
You can also call Transaction RSMIGRHANADB in BW system. This transaction will directly open the screen to convert objects to HANA optimized objects.

You can select the object type and enter the name of the object. In the following screen, I have selected a standard InfoCube to convert to HANA Optimized InfoCube.
You can also select an option to view the logs after conversion.
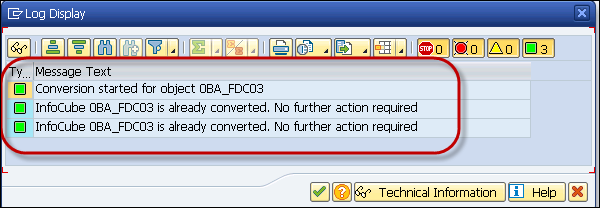
When the selected object is already HANA optimized object, or conversion is done, you will get the message as shown in the following screenshot.
SAP BW on HANA - Composite Providers
Composite Providers are used to combine multiple InfoProviders using Join or Union operations. When you use SAP BW on HANA, one of the InfoProvider should use in-memory database and the data in composite providers can be used for reporting and analysis.
When you use SAP BW with non-HANA database, then BWA is a prerequisite to create Composite Providers. The primary advantage of Composite Providers is that you can create new complex business scenarios by combining InfoProviders using Join operation.
Create Composite Providers
You can create Composite Providers in Administration workbench using Transaction: RSLIMOBW
In Composite Provider screen, enter the name of the Composite Provider (up to 10 characters) and click the Create button.
The graphical modeling environment appears.
You can drag and drop the required InfoProviders (from the InfoProvider tree on the left of the screen) onto the modeling area.
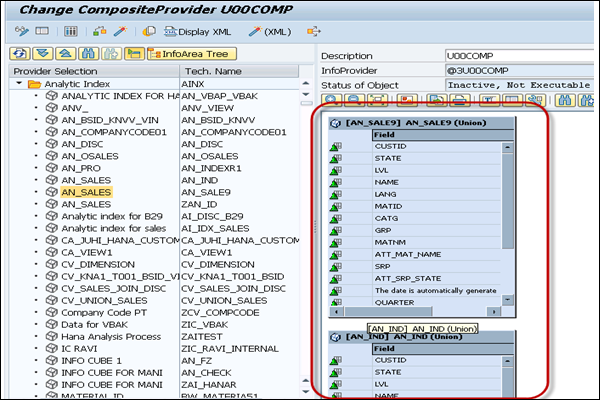
When you drag the InfoProviders, you can define binding type - Union or Join and click OK.
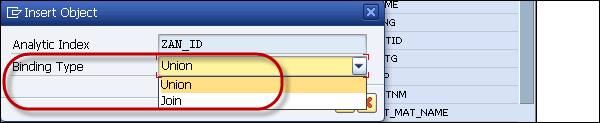
Next is to drag the fields from the InfoProviders → Composite Provider. These lines show the InfoProviders fields that are used in Composite Provider. When you use data binding as Join, it is labeled with name Join.
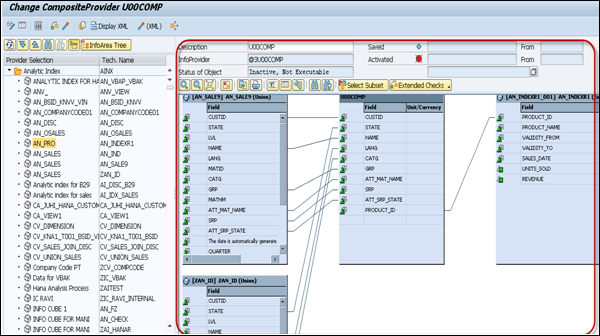
You can also change the name of the field or can add a description. To change the field name, right-click on the field name → Change Property → Change.
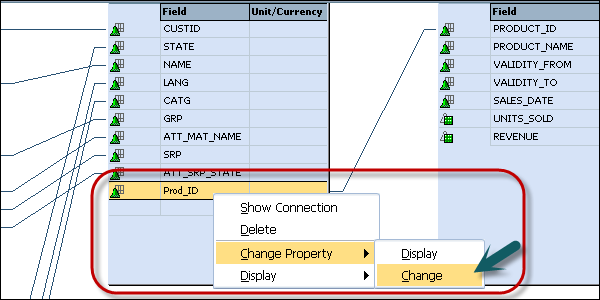
You can also assign a currency or unit from a characteristic to key figures. To do so, go to Context menu of Key figure → Change Property → Change.
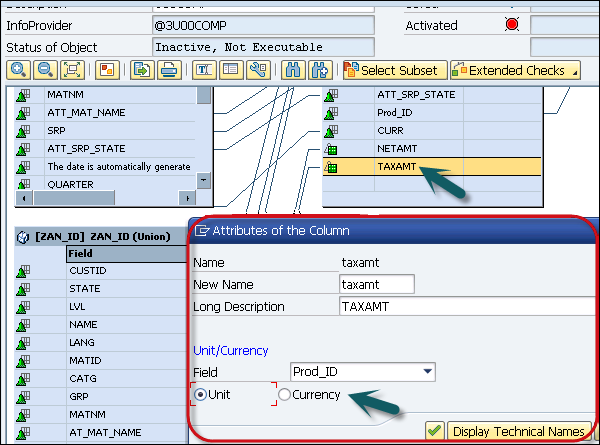
You can also see XML structure of composite provider using display XML option.
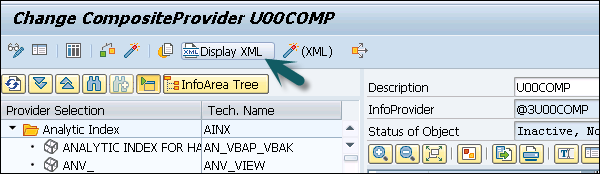
The next step is to activate the CompositeProvider. When the CompositeProvider is activated, the data is stored in BW Accelerator or the SAP HANA database.
Composite Providers in HANA Studio
You can also create Composite Providers in SAP HANA Studio → BW Modeling.
Log on to the BW Modeling Perspective with your BW credentials and attach your HANA system using the context menu on your top project level folder, choosing the option Attach HANA system, without which you will not be able to include native SAP HANA models in your Composite Provider.
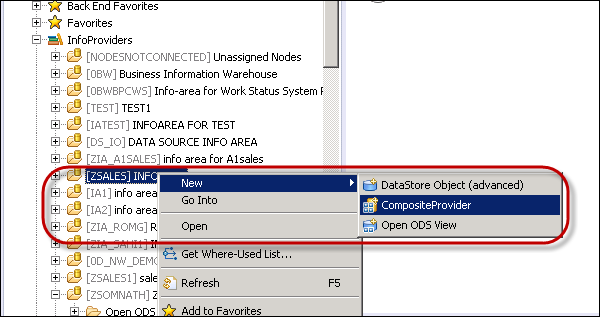
Navigate to InfoArea under BW Project → Context menu → New → Composite Provider.
Enter the Composite Provider name and description. Click Finish.
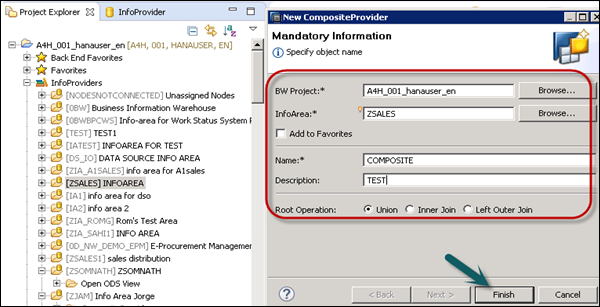
In Editor, you can see the following tabs −
General − Shows the properties of Composite Provider.
Scenario − In this tab you add InfoProviders and HANA Views to Composite Provider. Go to Scenario tab and you will see the default binding type. Click the Add sign.
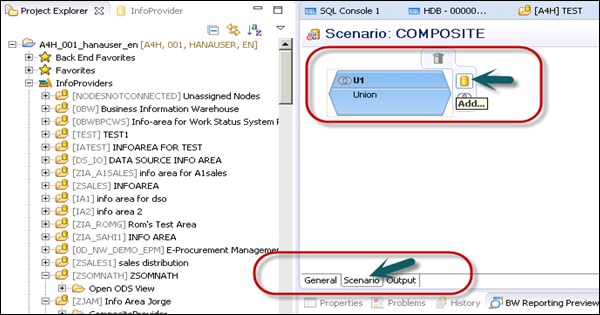
When you click the Add sign, you will be prompted if you want to select an InfoProvider or HANA view. To perform a search, enter * and you will see a list of available objects. Select any object that you want to add to the Composite Provider.
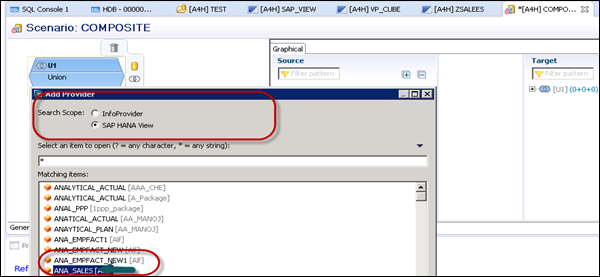
Similarly, add an InfoProvider to your Composite Provider. Next is to add the fields from Source to Target by dragging the fields. You can use Expand all to expand all the objects added. You can also apply a filter to search a particular field.
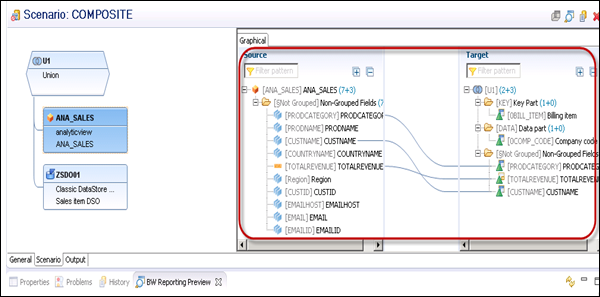
Go to the output tab and you can see the mapping of added objects.
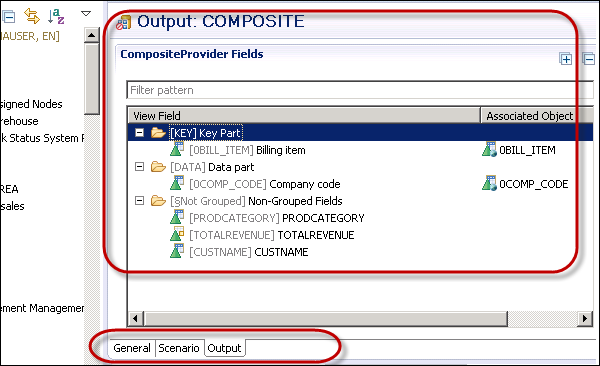
Next is to check and activate BW object.

You can also analyze the result in the Problems log of this perspective.
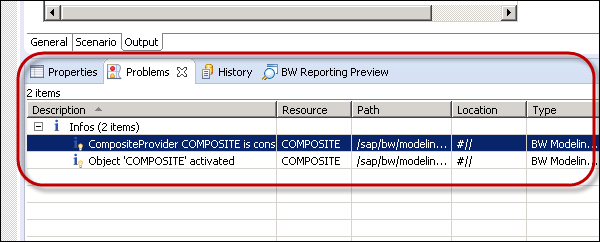
To preview the data in HANA Studio, use the magnifying glass icon in the upper right corner → Show Preview.

SAP BW on HANA - Advanced DSOs
Using HANA optimized objects, you can achieve better performance for analytical reporting and data analysis. DSOs of SAP BW are automatically optimized for activation in SAP HANA database. When you migrate SAP BW on HANA, all standard DSOs are moved to SAP HANA database in a column storage.
To use advanced DSOs, you should have SAP HANA database support pack 08 or higher version and in the backend you should have SAP BW 7.4 SPS9.
Create an Advanced DSO Based on HANA Database
Go to SAP HANA studio → BW Modeling Tools
To create an Advanced DSO, right-click on your InfoArea and choose New DataStoreObject (advanced).
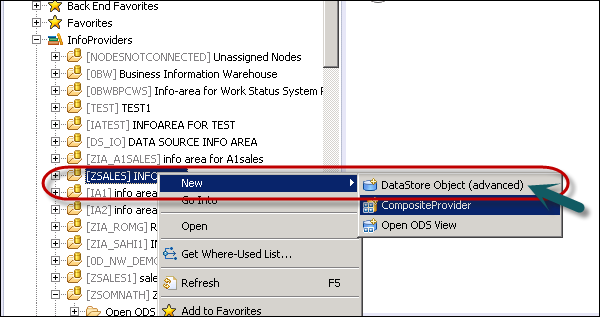
Provide the following details and click Finish.
Enter the name of DataStore - The technical name can be between three and nine characters long. If you have a namespace for the DataStore object (advanced), the name can only be eight characters long.
Description of the DataStore
Select an Object Template
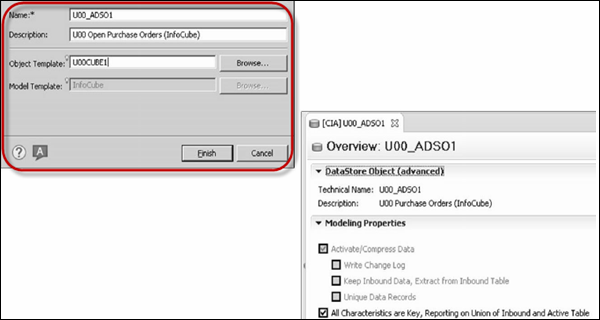
You can create a Transformation from your standard DSO to Advanced DSO that you have created in HANA database. Go to SAP BW system, expand InfoCube and copy transformation from the existing DSO to the new Advanced DSO.
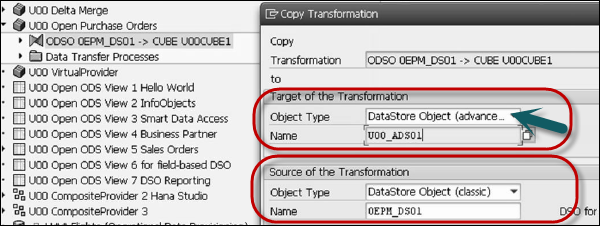
You can create a new transformation and load the data to new Advanced Data Store Object.
SAP BW on HANA - Hybrid Modeling
Using Hybrid provider, you can quickly access the data because of Hybrid architecture and the old historical data is mixed with new data. Hybrid provider provides a high level of system performance for analyzing data in queries.
Following types of Hybrid Providers can be used −
Hybrid Provider Based on DataStore Object
These hybrid providers are based on the combination of DSOs and InfoCube. As part of the Hybrid architecture, new data is stored in DSO and InfoCube provides aggregate.
When you execute a BEx query on HybridProvider, the data is read directly from the InfoCube. If you want to read the data from DSO, you have to change the request in BEx designer.
Go to Properties → Advanced in BEx Query Designer and choose the request status as 2.
The DSO and InfoCube transformation is 1:1 and you cant change this transformation.
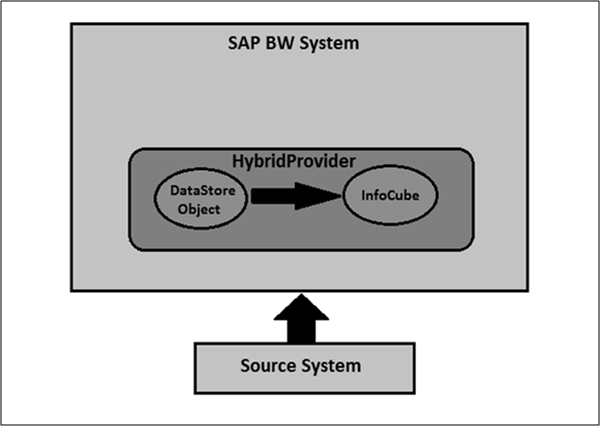
In Hybrid Provider, data can be loaded from any type of source. All of the data is stored in the BW system or in the BW Accelerator.
Hybrid Provider Based on Direct Access
In this hybrid provider, data is based on the combination of Virtual Providers and InfoCube. The new data is directly read from the source system using Virtual Providers.
This allows you to access real-time data without any delay. You can load the data only from specific data source.
HANA Views for BW InfoProviders
When you use SAP BW on HANA system, you can use the following HANA optimized objects: DataStore Objects, InfoObjects, queries as InfoProviders and CompositeProviders in BW workspace and queries.
When you create Information views in SAP HANA, data from BW data is published. These SAP HANA views point directly to data and tables that are managed by the BW.
The data from SAP BW can be directly consumed in HANA Modeling views. You can generate SAP HANA views for queries as InfoProviders in HANA database.
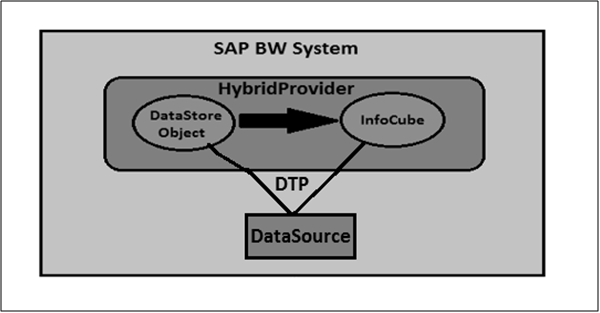
Create SAP HANA Views for Queries as InfoProvider
The first step is to create SAP HANA index. You can do this by using Transaction: RSDDB or by using Transaction RSA1 to open BW Workbench.
You can call up index maintenance for the object using the following options −
Method 1 − First method is to call the SAP BW Workbench using Transaction RSA1.
Select InfoProvider in the navigation. Right-click and select Maintain BW Accelerator Index. This opens SAP HANA/BWA index administration screen.
Method 2 − Other ways to directly call SAP HANA/BWA index maintenance screen by using Transaction RSDDB.
This opens the SAP HANA/BWA index maintenance screen. Select the BW object type - VirtualProvider or Query as InfoProvider using the push button option.
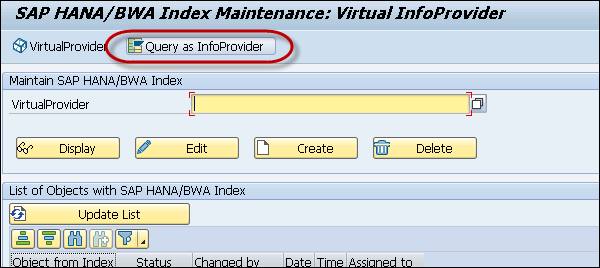
Select the query that you want to generate SAP HANA view for → Create.
In the lower part of the screen, the system displays a list of all objects that already have a SAP HANA index.
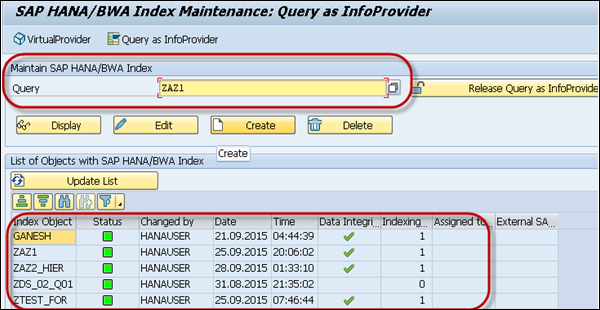
You cant index a query result, if the query meets any of the following conditions −
When a query contains a temporal join as a result, it cant be stored in flat index because of hierarchy.
When local aggregations are used.
When the name of the query is more than 20 letters.
When the query is an input-ready query.
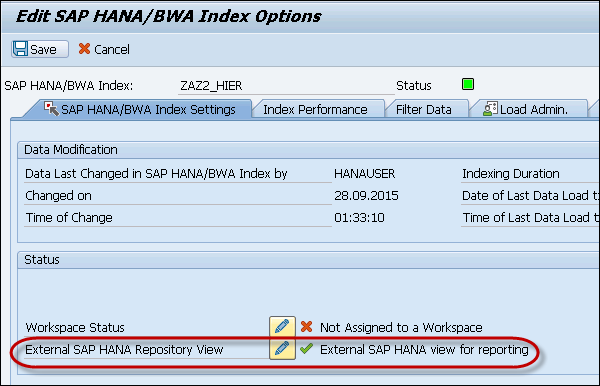
Select External SAP HANA Repository View. When you activate the index, SAP HANA view corresponding to the structure of the object is generated on the SAP HANA database.
SAP BW on HANA Live
SAP HANA Live provides improved analysis quality on all business suite applications. There is no requirement of BW modeling or ABAP programming and you can access the reporting framework using open standards - SQL and MDX.
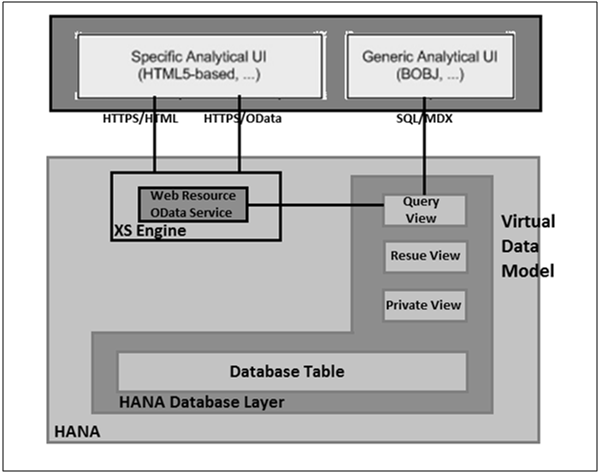
Use of Virtual Data Models hide the complexity of SAP business suite applications and data is available with ease of access on data models. Virtual Data Model consists of the following types of view −
Query View
They are used for direct use in a HTML5 based Analytical application or to be used in an Analytical tool like BusinessObjects. Query views are normally not reused in other views and always remain on the top of hierarchy.
Reuse View
These views are the heart of virtual data models and are reused in other views. They are not designed to be directly used in other analytical tools - Business Objects.
Private View
They are based on database tables, other private views, or reuse views. They do not contain any clear business scenario so they are not classified as reuse views and hence cannot be used with other views.
HANA Live Architecture
SAP HANA Live virtual data models are designed on the top of SAP Business suite tables. The data provided by virtual data models can be used using HTML5 based applications or with analytical tools like SAP BusinessObjects.
Following is the diagrammatic representation of the architecture of SAP HANA Live.
All reporting in SAP HANA Live is based on the underlying computing engine and on realtime data from SAP Business suite applications, hence there is no need to wait for data load.
In case, customers want to create new reports to enhance the existing ones, they just need to make changes to virtual data models or create new HANA models to support the report development quickly.
Technical System Landscape for SAP HANA Live
Following two approaches can be used for the deployment of SAP HANA Live on SAP Business suite.
Side by Side Scenario
In this scenario, you have two systems and data replications occur using SAP Landscape Transformation. To execute SAP HANA Live views, you need to replicate the corresponding tables in HANA database.
Integration Scenario
SAP HANA Live and Business Suite system shares the same SAP HANA appliance and this scenario is suitable for applications, which run directly on SAP HANA.
SAP BW on HANA - Data Provisioning
Data Provisioning deals with replication of data into HANA database to be used in HANA Modeling and to be consumed using Reporting tools. There are various data provisioning methods that are supported in SAP HANA system data replication.
SAP HANA Replication allows migration of data from source systems to SAP HANA database. A simple way to move data from the existing SAP system to HANA is by using various data replication techniques.
System replication can be set up on the console via command line or by using HANA studio. The primary ECC or transaction systems can stay online during this process. There are three types of data replication methods in HANA system −
- SAP Landscape Transformation (SLT) Replication method
- ETL tool SAP Business Object Data Service (BODS) method
- Direct Extractor Connection (DXC)method
SAP BW on HANA - SLT Replication HANA
SAP Landscape Transformation (SLT) Replication is a trigger based data replication method in HANA system. It is a perfect solution for replicating real-time data or schedule-based replication from SAP and non-SAP sources. It has SAP LT Replication server, which takes care of all trigger requests. The replication server can be installed as a standalone server or can run on any SAP system with SAP NW 7.02 or above.
There is a Trusted RFC connection between HANA DB and ECC transaction system which enables trigger based data replication in HANA system environment. In the following image, you can see SAP HANA SLT replication scenario for real-time data replication.
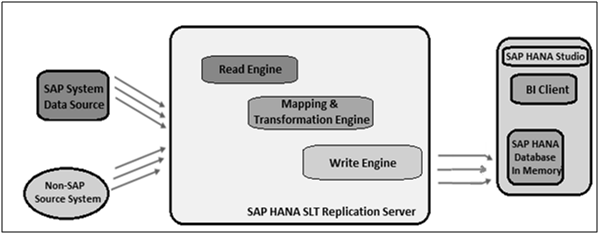
Advantage of SLT Replication
Following are the advantages of SLT Replication.
SLT Replication method allows data replication from multiple source systems to one HANA system and also from one source system to multiple HANA systems.
SAP LT uses trigger-based approach. It has no measurable performance impact on the source system.
It also provides data transformation and filtering capability before loading to HANA database.
It allows real-time data replication, replicating only relevant data into HANA from SAP and non-SAP source systems.
It is fully integrated with HANA System and HANA studio.
Create a Trusted RFC connection in ECC System
On your source SAP system AA1, you want to set up a trusted RFC towards the target system BB1. When it is done, it would mean that when you are logged onto AA1 and your user has enough authorization in BB1. You can use the RFC connection and log on to BB1 without having to re-enter the username and password.
Using RFC trusted/trusting relationship between two SAP systems, RFC from a trusted system to a trusting system, password is not required for logging on to the trusting system.
Open the SAP ECC system using SAP logon. Enter transaction number sm59. This is the transaction number to create a new Trusted RFC connection → Click the third icon to open a new connection wizard → Click Create and a new window will open.

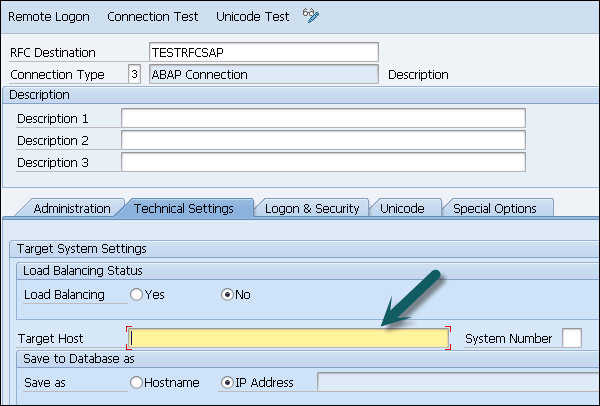
RFC Destination ECCHANA (enter name of RFC destination) Connection Type: 3 (for ABAP system)
Go to Technical Setting: Enter Target host: ECC system name, IP and enter System number.
Go to Logon & Security tab, Enter Language, Client, ECC system username and password.
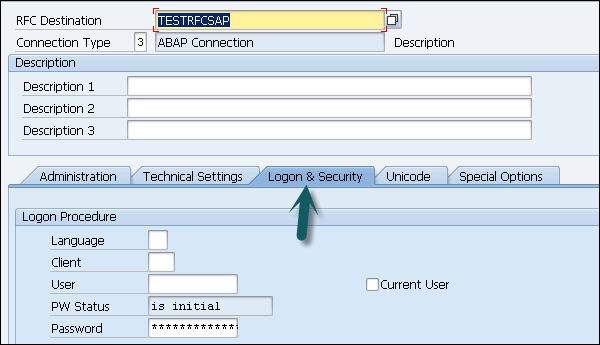
Click the Save option at the top of the screen.

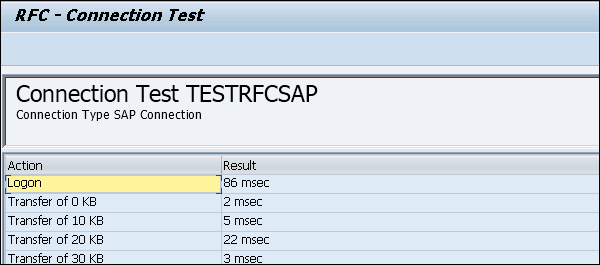
Click the Test Connection and it will successfully test the connection.
Configure RFC Connection
Run transaction: ltr (to configure RFC connection). A new browser will open. Enter ECC system username and password and log on.

Click New. A new window will open. Enter the configuration name. Click Next. Enter RFC Destination (connection name created earlier), use search option, choose name and click next.
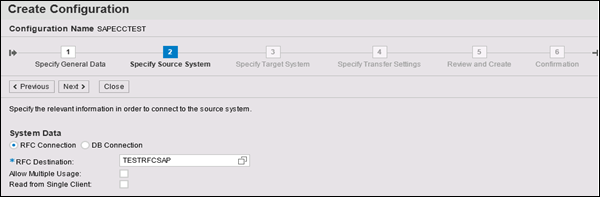
In Specify Target system, enter HANA system admin username and password, host name, Instance number and click Next. Enter the No. of Data transfer jobs like 007 (it cant be 000) → Next → Create Configuration.
Now go to HANA Studio to use this connection and follow the path: Go to HANA Studio → Click on Data Provisioning → Choose HANA system.
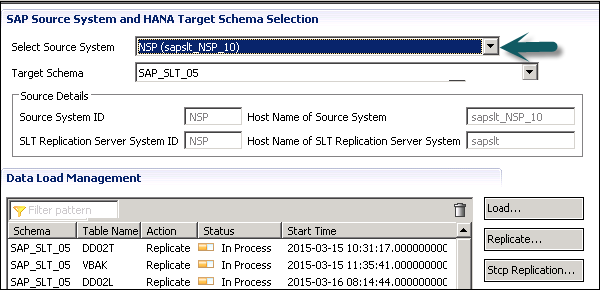
Select the source system (name of trusted RFC connection) and target schema name where you want to load the tables from ECC system. Select the tables you want to move to HANA database → ADD → Finish.
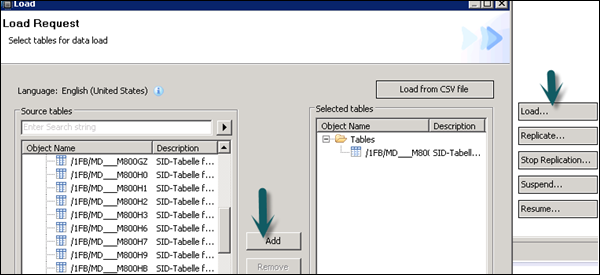
The selected tables will move to the chosen schema under HANA database.
There are different modes under SLT data replication −
Load − To schedule the data load to HANA database.
Replicate − To replicate the scheduling.
Suspend − To suspend the replication process.
Resume − To resume the stopped replication to complete the data load.
SAP BW on HANA - SLT Replication BW
SLT replication trigger-based approach is very common with SAP BW system for real-time data replication on any database as per Product Availability Matrix (PAM).
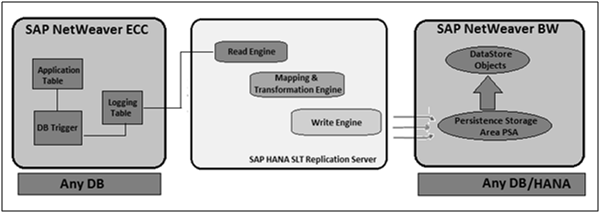
In the above figure, you can see the simple architecture of SLT data replication with SAP BW system. SLT data replication is suggested for simple tables without any join or transformation. SLT replication server can be used by SAP BW customers and it is independent of underneath database.
SLT Replication server is used to administrate and manage data provisioning.
SAP BW on HANA - DB Connect
DB Connect is used to define other database connection in addition to default connection and these connections are used to transfer data into the BI system from tables or views.
To connect an external database, you should have the following information −
- Tools
- Source Application Knowledge
- SQL Syntax in Database
- Database Functions
Prerequisites
In case, your source Database management system is different from BI DBMS, you need to install database client for source DBMS on BI application server.
DB Connect key features include loading of data into BI from a database that is supported by SAP. When you connect a database to BI as the source system, it requires creating a direct point of access to the external relational database management system.
DB Architecture
SAP NetWeaver component multiconnect function allows you to open extra database connections in addition to SAP default connection and you can use this connection to connect to the external database.
DB Connect can be used to establish a connection of this type as a source system connection to BI. The DB Connect enhancements to the database allows you to load the data to BI from the database tables or views of external applications.
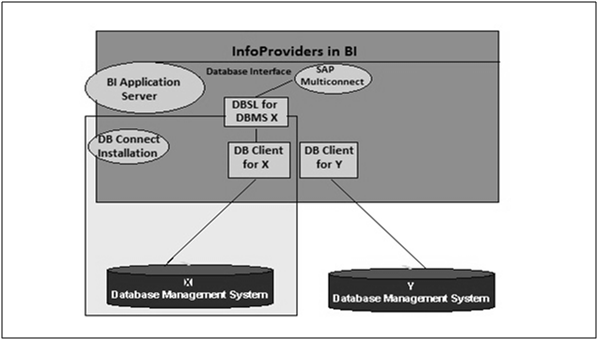
For default connection, DB Client and DBSL are preinstalled for Database Management System (DBMS). To use DB Connect to transfer data into the BI system from other database management systems, you need to install database-specific DB Client and database-specific DBSL on the BI application server that you are using to run DB connect.
Create DBMS as a Source System
Go to RSA1 → Administration workbench. Under modeling tab → Source Systems
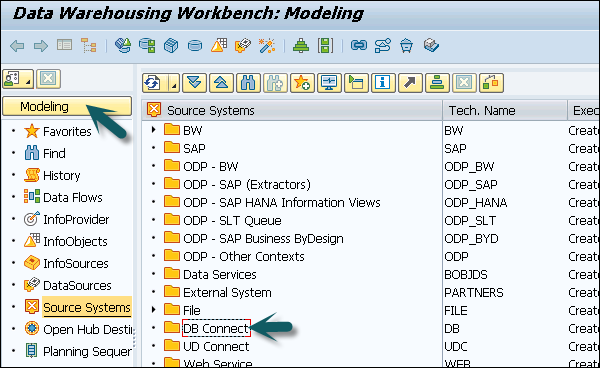
Go to DB Connect → Right click → Create
Enter logical system name (DB Connect) and description. Click Continue.
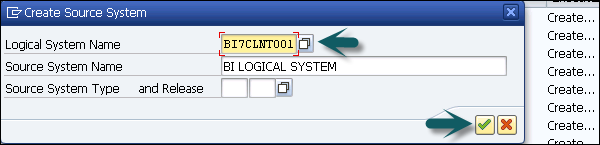
Enter the DBMS that you want to use to manage the database.
Enter the database user under whose name you want the connection to be opened and the DB Password has to enter for authentication by the database.
In Connection Info, you have to enter the technical information required to open the database connection.
Permanent Indicator − You can set this indicator to maintain a permanent connection to database. If the first transaction is ended, each transaction is checked to see if the connection can be reinitiated.
You can use this option, If the DB connection has to be accessed frequently.
Save this configuration and you can click go back to see in the table.
SAP BW on HANA - HANA View for InfoCube
You can create HANA Modeling views based on InfoCubes in SAP BW system. To do this you have to open InfoCube in edit mode and activate flag External SAP HANA View.
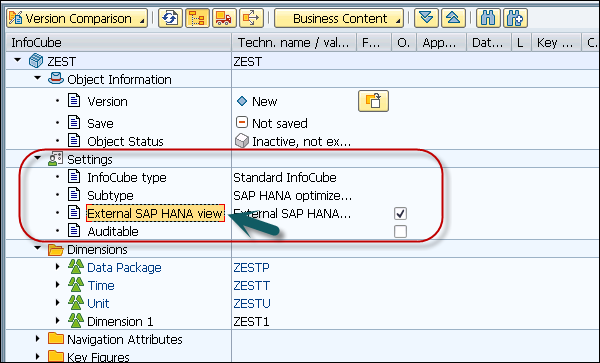
Next is to activate the InfoCube.

Then, go to SAP HANA Studio → Go to Package: system-local → BW → BW2HANA
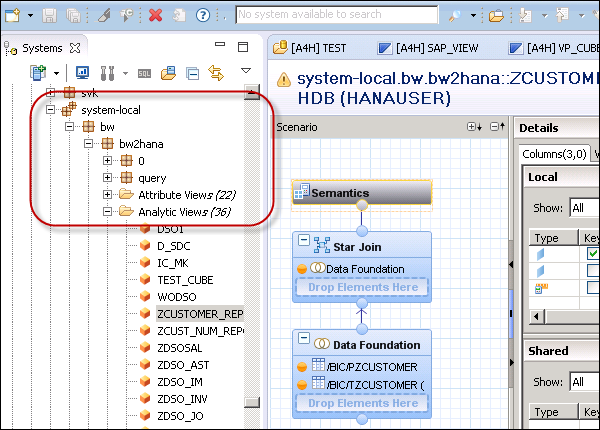
Search for Analytical view with the name as InfoCube. Right-click → Open Definition. You can select the auto layout function.
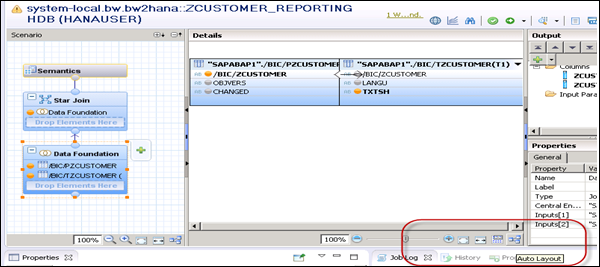
SAP BW on HANA - Process Chain
When you migrate from SAP BW to HANA database, there are various process types that are obsolete. If you use SAP HANA database, the following process types in the process chain are not required −
- Filling of New Aggregates
- BWA Indexes
- Adjust Time Dependent Aggregates
- Build Index
- Delete Index
You dont need to modify the process chains to remove these process types. The process chain continues to run without errors. When you check the log of Process Chain, you will see these steps are not executed.
Different Transactions are available to monitor the Process Chain runs.
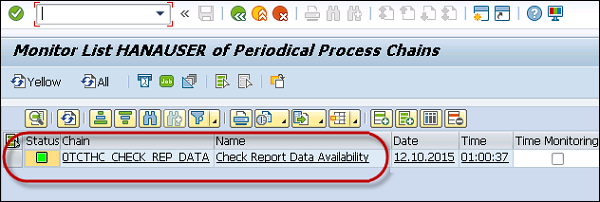
Monitor Periodic Process Chains
Use Transaction: RSPCM
You can monitor the status of current runs for selected process chains. You can also navigate to the detailed view of the process chain runs from this transaction.
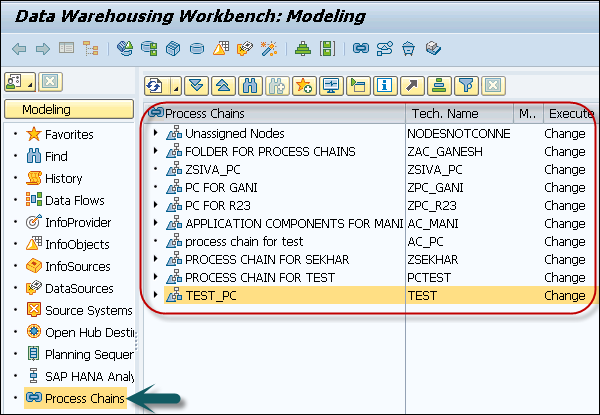
View the Log for Runs of a Process Chain
Use Transaction: RSPC. It will display one or more runs for a process chain.
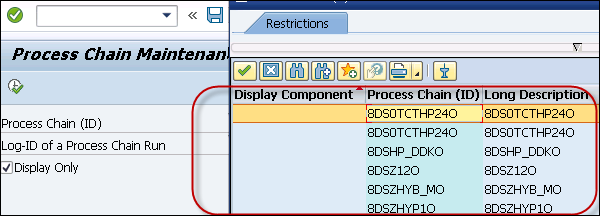
Perform Process Chain Maintenance for a Process Chain Run
Use Transaction: RSPC1. This transaction is used to view the log for this run by mentioning the log id of the concrete process chain.
HANA vs BWA
BW Accelerator (BWA) and HANA both are in-memory tools and provide you the options to accelerate the query performance by persisting copies of InfoCube in-memory. BWA was the first to bring in-memory concept to Data Warehousing and SAP HANA allows the entire applications to run on HANA in-memory database.
Following are the key differences between SAP HANA and BWA −
BW Accelerator (BWA)
BW Accelerator is specifically designed for Business Warehouse system 7.0 or higher to accelerate the query performance. It reduces the data acquisition time by persisting copies of InfoCube data in-memory.
BWA is a solution to achieve better performance without making any changes to BI/BW application.
It reads SAP BW/BI data and provides accelerated read process and feeds the results to BI/BW queries.
You can create BEx reports or reporting in Analytical tool like BusinessObjects or even Dashboards using accelerated queries with BWA.
SAP HANA In-Memory
SAP HANA is an in-memory database and platform to provide high performance analytical applications. Data can be replicated to HANA database from SAP and non-SAP data sources and viewed and analyzed using BusinessObjects reporting tools.
SAP HANA supports real-time data load and reporting using SLT replication triggerbased data provisioning.
Data sets are loaded to SAP HANA and using BI tools you can consume HANA data models for data analysis and reporting.
You can access SAP and non-SAP data in SAP HANA, including SAP BW.
Data is stored in column-based storage and hence provides data compression and less time to perform aggregations. There is no need to save aggregated data and aggregations can be performed on the fly.
Note −
When you migrate SAP BW powered by HANA, BWA is obsolete. You can check with the BWA hardware vendor to credit BWA license. Few hardware vendors allow you to credit BWA hardware when you get a new hardware appliance of SAP HANA.
Query run-time on SAP BW on HANA and BWA is comparable. In some scenarios, queries run faster on BW on HANA as compared to BWA.
When you use BW on HANA, all BWA index build is eliminated. When data load is performed, it is immediately available.
SAP BW on HANA - Authorization
When you create SAP HANA views based on BW system, there are certain type of privileges that are required to run the views in HANA. Different level of securities can be applied to objects in SAP HANA and BW system.
In SAP HANA, analytical privileges are used to limit the row level access on modeling views. Analytic privileges are handled as filters for database queries. Users only see the data for which they have an analytic privilege.
You can assign different types of right to different users on different component of a View in Analytic Privileges.
Sometimes, it is required that data in the same view shouldnt be accessible to other users who do not have any relevant requirement for that data.
Example
Suppose you have an Analytic view EmpDetails that has details about the employees of an organization - Emp name, Emp Id, Dept, Salary, Date of Joining, Emp logon, etc. Now if you dont want your Report developer to see Salary details or Emp logon details of all employees, you can hide this by using the Analytic privileges option.
Analytic Privileges are only applied to attributes in an Information View. We cannot add measures to restrict access in Analytic Privileges.
Analytic Privileges are used to control read access on SAP HANA Information views. Hence, we can restrict data by Empname, EmpId, Emp logon or by Emp Dept and not by numerical values like salary and bonus.
Create Analytic Privileges in SAP HANA
Right-click on Package name and go to new Analytic Privilege or you can open using HANA Modeler quick launch.
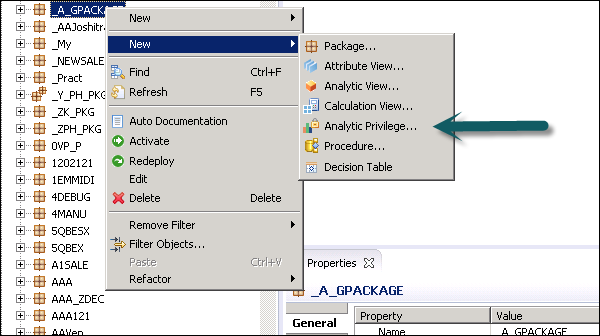
Enter the name and Description of Analytic Privilege → Finish. A new window will open.
You can click the Next button and add Modeling view in this window before you click on Finish. There is also an option to copy an existing Analytic Privilege package.
In BW, the users can only execute BEx queries on which they are authorized. In case you dont have a permission to run a query, an error message is displayed.
To create SAP HANA views from InfoProviders, the following approach can be used: XML- based Analytical Privilege.
When SAP HANA views are created from InfoProviders from SAP HANA, you can use XMLbased analytical privilege to be applied: SQL-based Analytical Privilege.
When SAP HANA views are created from BW InfoProviders from SAP BW, SQL-based analytical privileges are used.
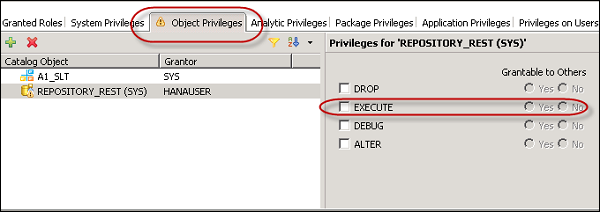
Object Privilege in SAP HANA
To access SAP HANA views that are generated from SAP BW, you need to have the following authorization −
Object privilege − SELECT on _SYS_BI
Object privilege − EXECUTE on REPOSITORY_REST(SYS)
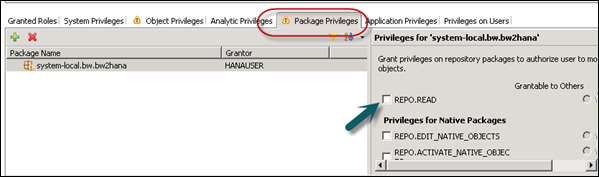
Package privilege − REPO.READ on the content package where generated SAP HANA views are stored.
Consultant Responsibilities
A person should have good experience in SAP BW with expert level knowledge on SAP BW on SAP HANA projects. He/she should have worked in projects involving SAP BW modelling with respect to SAP HANA using composite providers, Advance DSOs, ODP, LSA ++ and using BW objects exposed as HANA views.
Following are some of the other experiences and capabilities required.
BW on HANA project experience and at least 2 end-to-end BW implementation or development experience.
Implementing SAP BW on HANA specific modelling like Composite Providers and exposing BW objects in HANA Views, Operational Data Provisioning, LSA++, etc.
Work on HANA Studio - Schemas and tables on HANA, attribute view, analytical view and Calculation views.
Developing and handling hybrid scenarios - BW data models and HANA views as per the requirement.
Manage SAP BW tables in HANA distribution environment.
Experience in integration with BW/BO/HANA is highly required.
Knowledge on BOBJ tools like WEBI, Lumira, and Design studio is a plus.
SAP BW 7.0 & above Certified.
SAP BW on HANA Certified.
