
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Evolution of ILP Processors in Computer Architecture
The evolution of Von Neumann processors can be attributed to two areas of development improvement in technology, marked by increasing clock rates and the functional evolution of processors. Functional evolution has been achieved primarily by increasing the degree of parallelism of the internal operations, the issues, and the execution of instructions.
This occurred in three consecutive evolution phases as the first phase is represented by traditional von Neumann processors, which are characterized by sequential issues and sequential execution of instructions as shown in the figure.
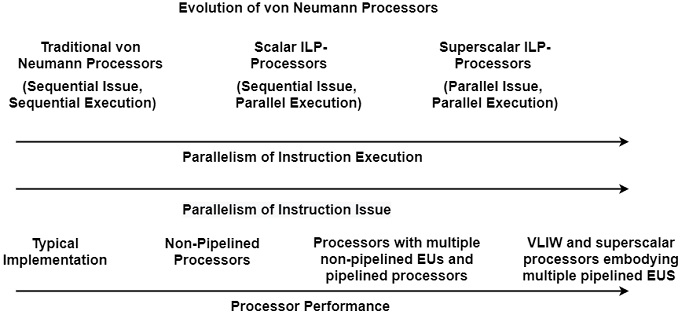
The search for greater implementation gave advance to the introduction of parallel instruction execution. Parallel execution was achieved by using one of two orthogonal concepts by the introduction of multiple (non-pipelined) execution units, or by emerge. Due to early ILP-processors used sequential instruction problems, the second procedure of the evolution is characterized by scalar ILP-Processors.
In this evolution, the degree of parallel execution was increased even further by making use of multiple pipelined execution units. Although this increased the parallelism of the execution, it soon became clear that the sequential instruction issue was no longer able to feed enough instructions to pipelined execution units operating in parallel.
Instruction issues evolve into a bottleneck, as Flynn (1966) had foreseen long earlier. Therefore, the third stage in the evolution of the von Neumann processor became certain when sequential instruction issues had to be restored with a parallel issue. As a result, superscalar ILP-processors start to occur. They were first executed as statistically scheduled VLIW architectures, which issue multi-operation instructions.
Instruction issues and execution are closely related. The more parallel the instruction execution, the higher the condition for the parallelism of instruction issue. Thus, the evolution of von Neumann processors is marked by the continuous and harmonious increase of the parallelism of instruction issues and execution.
Pipelining offers higher performance at a cost of increased hardware complexity. Accordingly, pipelined processors were first employed in very expensive super and vector processors, around 1970. Subsequently, pipelined instruction processing became the standard implementation in mainframes and, in the 1980s in microprocessors.
Most dedicated functional units such as FX or FP EUs also became pipelined. At current, pipelined EUs are generally used as building blocks of advanced processors, such as VLIWs or superscalar processors. For example, the PowerPC 601 has three pipelined EUs, one each for FX, FP, and branch execution.
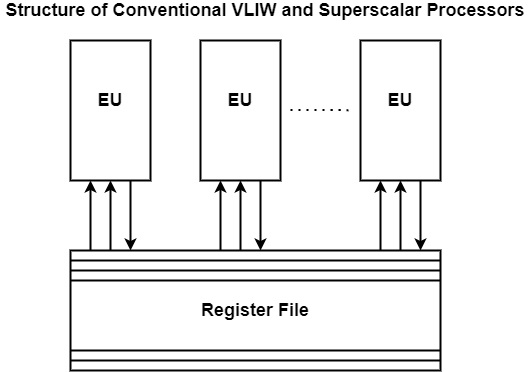
The other class of ILP-processors consisting of VLIW and superscalar processors, differs substantially from pipelined processors in that they use replication that is multiple EUs. The basic structure of both VLIW and superscalar processors includes several EUs, each adequate of parallel operations on data fetched from a register file as displayed in the figure. In both types of processors, various EUs execute instructions and write back results into the register file together.

745 Views
