
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What are the operations of ILP-Processors?
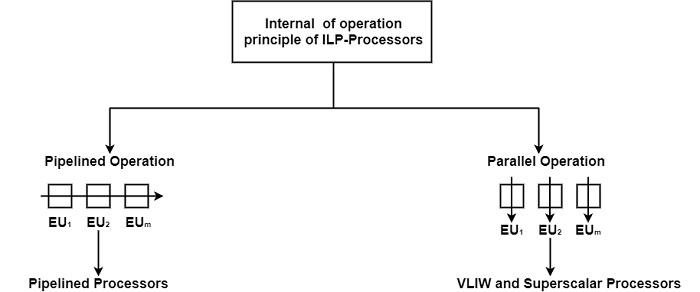
There are two types of operations of ILP-Processors such as Pipelined Processors and VLIW and Superscalar Processors. Pipelined Processors work like an assembly line, both VLIW and Superscalar processors operate basically in parallel, making use of several concurrently working EUs as shown in the figure −
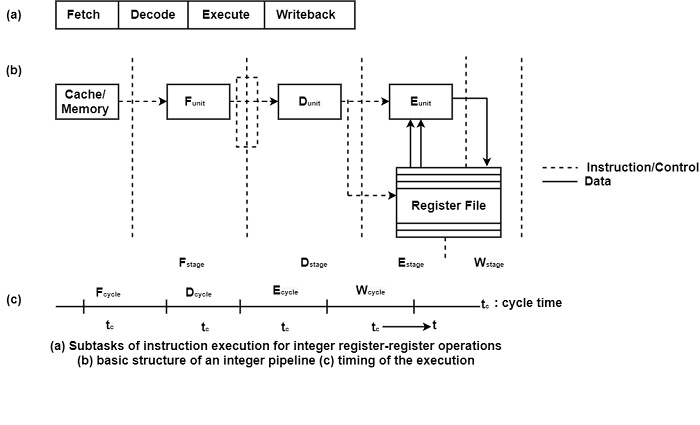
In describing the principle of operation of pipelined processors, for simplicity, it can confine itself to a straightforward pipelined processor which executes integer, RISC-like, register-register instructions. Pipelines like these operate along the following lines −
Instruction processing is subdivided into several successive subtasks: instruction Fetch (F), Decode (D), Execute (E), and writeback of the result (W), as shown in figure (a).
Each subtask is implemented by a related pipeline stage. In this example, we call them the F, D, E, and W stages as shown in figure (b). The operations in each stage are implemented by dedicated hardware. The F stage fetches an instruction from the cache or memory.
The D stage decodes the fetched instruction and performs, if needed, some additional tasks, such as checking for pipeline hazards. In the E stage, the required operation is executed using the fetched register operands. This is accomplished using the E unit, which, in our case, is a traditional integer ALU. Finally, in the W stage, the result is written back into the determined destination register. This operation does not need additional hardware, it is implemented easily by a write operation into the register file.
All the pipeline stages work like an assembly line, with synchronous timing. This means that at the beginning of every pipeline cycle each stage accepts a new input and at the same time delivers its output to the next stage excepts the last stage which writes the result into the specified destination as shown in figure (b) and (c).
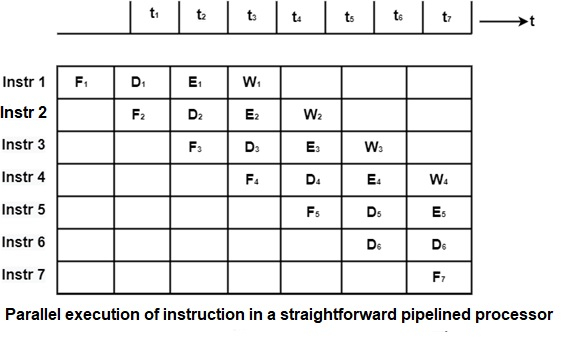
A significant feature of pipelined execution is that in each cycle a new instruction can enter the pipeline as shown in the figure. If an instruction has done the final phase of its execution, it removes. Thus, as many instructions can be implemented in parallel as there are pipeline stages.
Pipelining supports higher implementation at a cost of increased hardware complexity. Accordingly, pipelined processors were first employed in very expensive super and vector processors, around 1970. Subsequently, pipelined instruction processing became the standard implementation in mainframes and, in the 1980s in microprocessors.
Most dedicated functional units such as FX or FP EUs also became pipelined. Pipelined EUs are frequently used as building blocks of advanced processors, such as VLIWs or superscalar processors. For example, the PowerPC 601 has three pipelined EUs, one each for FX, FP, and branch execution.

903 Views
