
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Implementation of Global Instruction Scheduling in computer architecture
The implementation of global instruction scheduling is a technique called trace scheduling. Trace scheduling was first employed in the Bulldog compiler, developed for the experimental VLIW machine ELI-512 at Yale (Fisher et al, 1984), and subsequently in the Trace scheduling compiler of the commercial TRACE family of VLIW machines (Colwell et al, 1987).
A more recently published novel global schedule technique is FRGS (Finite Resource Global Scheduling), developed and experimentally implemented by IBM for VLIW and superscalar processor (Moon and Ebcioglu, 1992, Moon et al, 1993).
Trace Scheduling
This technique originates like most instruction scheduling techniques, in the schedule for horizontally microcoded machines (Fisher, 1981). Subsequently, trace scheduling was reimplemented as instruction scheduling for VLIW machines (Fisher et al, 1984).
Trace scheduling is based on the concept of trace. A trace is an execution path within a loop, such that a trace can include conditional branches and join points. As shown figure (a) it shows the traces identified in a flow graph.
A trace scheduler first identifies the traces in a program and then selects the most likely trace and schedules it as an entity. Then it selects the next most likely trace and repeats the process until the whole program is scheduled as shown in figure (b) – (d).
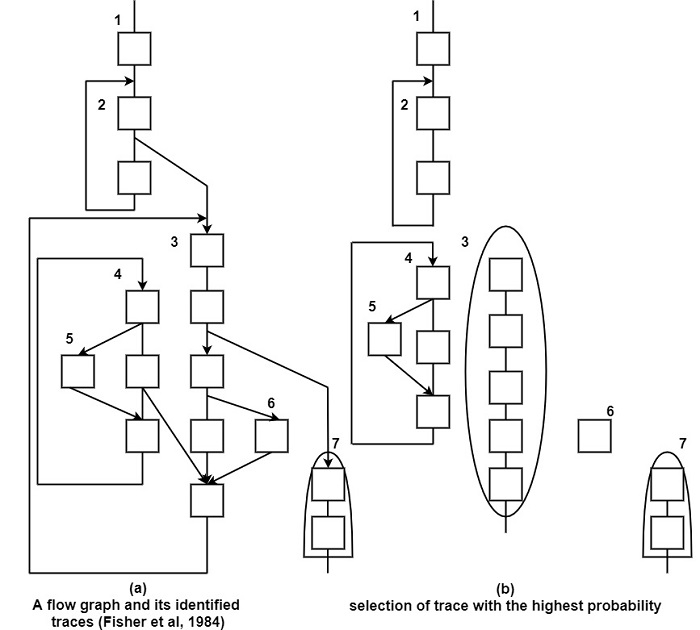
In selecting the most likely trace, the compiler uses dynamic branch prediction as well as hints supplied by the programmer. As shown in figure (a), let us assume that trace no.3 has the highest probability, and therefore it will be scheduled first as shown in figure (b).
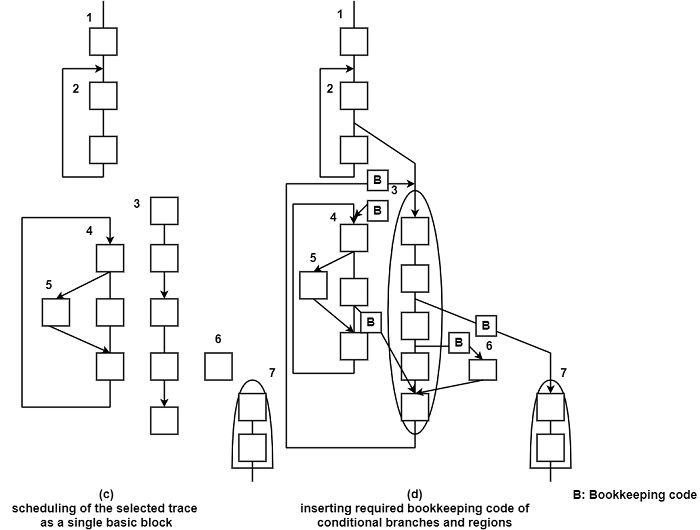
Each trace is scheduled as if it were a single basic block as shown in figure (c). In this case, scheduling is global, during scheduling independent instructions can be moved across conditional branches or join points. Bookkeeping code will also be generated and placed into the appropriate path of conditional branches and joints as shown in figure (d).
After completing the schedule for trace no 3, the next most probable trace is selected, say trace no 4, then this trace is scheduled, and so on.
FRGS (Finite Resource Global Scheduling)
This global scheduling method is intended to avoid the serious inefficiency problems of the existing VLIW compilers caused by long compilation times and code explosion (Moon et Ebcioglu, 1992). It can be applied for both VLIWs and a superscalar processor such that this method first delivers a superscalar code and it required, in a second step VLIW code can be obtained through a local transformation.
There are 16 general-purpose ALUs, with eight of them able to execute memory load/store operations. ALU and load/store operations for the same unit are exclusive. There are 128 general-purpose registers and 16 condition code registers.
FRGS is quite a complex method. First, in each cycle, FRGS selects all operations available for a schedule (so-called greedy selection). A software window is used to limit the required amount of computation. Then a simple heuristics are used to select an operation from the availability list for the next schedule, to utilize the hardware resources as far as possible.

947 Views
