- DSA - Home
- DSA - Overview
- DSA - Environment Setup
- DSA - Algorithms Basics
- DSA - Asymptotic Analysis
- Data Structures
- DSA - Data Structure Basics
- DSA - Data Structures and Types
- DSA - Array Data Structure
- DSA - Skip List Data Structure
- Linked Lists
- DSA - Linked List Data Structure
- DSA - Doubly Linked List Data Structure
- DSA - Circular Linked List Data Structure
- Stack & Queue
- DSA - Stack Data Structure
- DSA - Expression Parsing
- DSA - Queue Data Structure
- DSA - Circular Queue Data Structure
- DSA - Priority Queue Data Structure
- DSA - Deque Data Structure
- Searching Algorithms
- DSA - Searching Algorithms
- DSA - Linear Search Algorithm
- DSA - Binary Search Algorithm
- DSA - Interpolation Search
- DSA - Jump Search Algorithm
- DSA - Exponential Search
- DSA - Fibonacci Search
- DSA - Sublist Search
- DSA - Hash Table
- Sorting Algorithms
- DSA - Sorting Algorithms
- DSA - Bubble Sort Algorithm
- DSA - Insertion Sort Algorithm
- DSA - Selection Sort Algorithm
- DSA - Merge Sort Algorithm
- DSA - Shell Sort Algorithm
- DSA - Heap Sort Algorithm
- DSA - Bucket Sort Algorithm
- DSA - Counting Sort Algorithm
- DSA - Radix Sort Algorithm
- DSA - Quick Sort Algorithm
- Matrices Data Structure
- DSA - Matrices Data Structure
- DSA - Lup Decomposition In Matrices
- DSA - Lu Decomposition In Matrices
- Graph Data Structure
- DSA - Graph Data Structure
- DSA - Depth First Traversal
- DSA - Breadth First Traversal
- DSA - Spanning Tree
- DSA - Topological Sorting
- DSA - Strongly Connected Components
- DSA - Biconnected Components
- DSA - Augmenting Path
- DSA - Network Flow Problems
- DSA - Flow Networks In Data Structures
- DSA - Edmonds Blossom Algorithm
- DSA - Maxflow Mincut Theorem
- Tree Data Structure
- DSA - Tree Data Structure
- DSA - Tree Traversal
- DSA - Binary Search Tree
- DSA - AVL Tree
- DSA - Red Black Trees
- DSA - B Trees
- DSA - B+ Trees
- DSA - Splay Trees
- DSA - Range Queries
- DSA - Segment Trees
- DSA - Fenwick Tree
- DSA - Fusion Tree
- DSA - Hashed Array Tree
- DSA - K-Ary Tree
- DSA - Kd Trees
- DSA - Priority Search Tree Data Structure
- Recursion
- DSA - Recursion Algorithms
- DSA - Tower of Hanoi Using Recursion
- DSA - Fibonacci Series Using Recursion
- Divide and Conquer
- DSA - Divide and Conquer
- DSA - Max-Min Problem
- DSA - Strassen's Matrix Multiplication
- DSA - Karatsuba Algorithm
- Greedy Algorithms
- DSA - Greedy Algorithms
- DSA - Travelling Salesman Problem (Greedy Approach)
- DSA - Prim's Minimal Spanning Tree
- DSA - Kruskal's Minimal Spanning Tree
- DSA - Dijkstra's Shortest Path Algorithm
- DSA - Map Colouring Algorithm
- DSA - Fractional Knapsack Problem
- DSA - Job Sequencing with Deadline
- DSA - Optimal Merge Pattern Algorithm
- Dynamic Programming
- DSA - Dynamic Programming
- DSA - Matrix Chain Multiplication
- DSA - Floyd Warshall Algorithm
- DSA - 0-1 Knapsack Problem
- DSA - Longest Common Sub-sequence Algorithm
- DSA - Travelling Salesman Problem (Dynamic Approach)
- Hashing
- DSA - Hashing Data Structure
- DSA - Collision In Hashing
- Disjoint Set
- DSA - Disjoint Set
- DSA - Path Compression And Union By Rank
- Heap
- DSA - Heap Data Structure
- DSA - Binary Heap
- DSA - Binomial Heap
- DSA - Fibonacci Heap
- Tries Data Structure
- DSA - Tries
- DSA - Standard Tries
- DSA - Compressed Tries
- DSA - Suffix Tries
- Treaps
- DSA - Treaps Data Structure
- Bit Mask
- DSA - Bit Mask In Data Structures
- Bloom Filter
- DSA - Bloom Filter Data Structure
- Approximation Algorithms
- DSA - Approximation Algorithms
- DSA - Vertex Cover Algorithm
- DSA - Set Cover Problem
- DSA - Travelling Salesman Problem (Approximation Approach)
- Randomized Algorithms
- DSA - Randomized Algorithms
- DSA - Randomized Quick Sort Algorithm
- DSA - Karger’s Minimum Cut Algorithm
- DSA - Fisher-Yates Shuffle Algorithm
- Miscellaneous
- DSA - Infix to Postfix
- DSA - Bellmon Ford Shortest Path
- DSA - Maximum Bipartite Matching
- DSA Useful Resources
- DSA - Questions and Answers
- DSA - Selection Sort Interview Questions
- DSA - Merge Sort Interview Questions
- DSA - Insertion Sort Interview Questions
- DSA - Heap Sort Interview Questions
- DSA - Bubble Sort Interview Questions
- DSA - Bucket Sort Interview Questions
- DSA - Radix Sort Interview Questions
- DSA - Cycle Sort Interview Questions
- DSA - Quick Guide
- DSA - Useful Resources
- DSA - Discussion
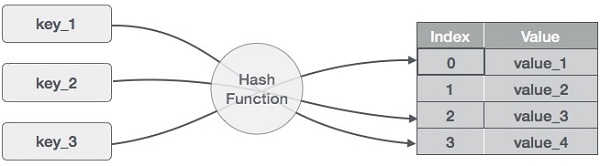
Hash Table Data structure

Hash Table is a data structure which stores data in an associative manner. In a hash table, data is stored in an array format, where each data value has its own unique index value. Access of data becomes very fast if we know the index of the desired data.
Thus, it becomes a data structure in which insertion and search operations are very fast irrespective of the size of the data. Hash Table uses an array as a storage medium and uses hash technique to generate an index where an element is to be inserted or is to be located from.
Hashing
Hashing is a technique to convert a range of key values into a range of indexes of an array. We're going to use modulo operator to get a range of key values. Consider an example of hash table of size 20, and the following items are to be stored. Item are in the (key,value) format.
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Key | Hash | Array Index |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
Linear Probing
As we can see, it may happen that the hashing technique is used to create an already used index of the array. In such a case, we can search the next empty location in the array by looking into the next cell until we find an empty cell. This technique is called linear probing.
| Sr.No. | Key | Hash | Array Index | After Linear Probing, Array Index |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Basic Operations
Following are the basic primary operations of a hash table.
Search − Searches an element in a hash table.
Insert − Inserts an element in a hash table.
Delete − Deletes an element from a hash table.
DataItem
Define a data item having some data and key, based on which the search is to be conducted in a hash table.
struct DataItem {
int data;
int key;
};
Hash Method
Define a hashing method to compute the hash code of the key of the data item.
int hashCode(int key){
return key % SIZE;
}
Search Operation
Whenever an element is to be searched, compute the hash code of the key passed and locate the element using that hash code as index in the array. Use linear probing to get the element ahead if the element is not found at the computed hash code.
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
Example
Following are the implementations of this operation in various programming language −
#include <stdio.h>
#define SIZE 10 // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem *hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
struct DataItem *search(int key) {
// get the hash
int hashIndex = hashCode(key);
// move in array until an empty slot is found or the key is found
while (hashArray[hashIndex] != NULL) {
// If the key is found, return the corresponding DataItem pointer
if (hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
// go to the next cell
++hashIndex;
// wrap around the table
hashIndex %= SIZE;
}
// If the key is not found, return NULL
return NULL;
}
int main() {
// Initializing the hash table with some sample DataItems
struct DataItem item2 = {25}; // Assuming the key is 25
struct DataItem item3 = {64}; // Assuming the key is 64
struct DataItem item4 = {22}; // Assuming the key is 22
// Calculate the hash index for each item and place them in the hash table
int hashIndex2 = hashCode(item2.key);
hashArray[hashIndex2] = &item2;
int hashIndex3 = hashCode(item3.key);
hashArray[hashIndex3] = &item3;
int hashIndex4 = hashCode(item4.key);
hashArray[hashIndex4] = &item4;
// Call the search function to test it
int keyToSearch = 64; // The key to search for in the hash table
struct DataItem *result = search(keyToSearch);
printf("The element to be searched: %d", keyToSearch);
if (result != NULL) {
printf("\nElement found");
} else {
printf("\nElement not found");
}
return 0;
}
Output
The element to be searched: 64 Element found
#include <iostream>
#include <unordered_map>
using namespace std;
#define SIZE 10 // Define the size of the hash table
struct DataItem {
int key;
};
unordered_map<int, DataItem*> hashMap; // Define the hash table as an unordered_map
int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
DataItem* search(int key) {
// get the hash
int hashIndex = hashCode(key);
// move in the map until an empty slot is found or the key is found
while (hashMap[hashIndex] != nullptr) {
// If the key is found, return the corresponding DataItem pointer
if (hashMap[hashIndex]->key == key)
return hashMap[hashIndex];
// go to the next cell
++hashIndex;
// wrap around the table
hashIndex %= SIZE;
}
// If the key is not found, return nullptr
return nullptr;
}
int main() {
// Initializing the hash table with some sample DataItems
DataItem item2 = {25}; // Assuming the key is 25
DataItem item3 = {64}; // Assuming the key is 64
DataItem item4 = {22}; // Assuming the key is 22
// Calculate the hash index for each item and place them in the hash table
int hashIndex2 = hashCode(item2.key);
hashMap[hashIndex2] = &item2;
int hashIndex3 = hashCode(item3.key);
hashMap[hashIndex3] = &item3;
int hashIndex4 = hashCode(item4.key);
hashMap[hashIndex4] = &item4;
// Call the search function to test it
int keyToSearch = 64; // The key to search for in the hash table
DataItem* result = search(keyToSearch);
cout<<"The element to be searched: "<<keyToSearch;
if (result != nullptr) {
cout << "\nElement found";
} else {
cout << "\nElement not found";
}
return 0;
}
Output
The element to be searched: 64 Element found
import java.util.HashMap;
public class Main {
static final int SIZE = 10; // Define the size of the hash table
static class DataItem {
int key;
}
static HashMap<Integer, DataItem> hashMap = new HashMap<>(); // Define the hash table as a HashMap
static int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
static DataItem search(int key) {
// get the hash
int hashIndex = hashCode(key);
// move in map until an empty slot is found or the key is found
while (hashMap.get(hashIndex) != null) {
// If the key is found, return the corresponding DataItem
if (hashMap.get(hashIndex).key == key)
return hashMap.get(hashIndex);
// go to the next cell
++hashIndex;
// wrap around the table
hashIndex %= SIZE;
}
// If the key is not found, return null
return null;
}
public static void main(String[] args) {
// Initializing the hash table with some sample DataItems
DataItem item2 = new DataItem();
item2.key = 25; // Assuming the key is 25
DataItem item3 = new DataItem();
item3.key = 64; // Assuming the key is 64
DataItem item4 = new DataItem();
item4.key = 22; // Assuming the key is 22
// Calculate the hash index for each item and place them in the hash table
int hashIndex2 = hashCode(item2.key);
hashMap.put(hashIndex2, item2);
int hashIndex3 = hashCode(item3.key);
hashMap.put(hashIndex3, item3);
int hashIndex4 = hashCode(item4.key);
hashMap.put(hashIndex4, item4);
// Call the search function to test it
int keyToSearch = 64; // The key to search for in the hash table
DataItem result = search(keyToSearch);
System.out.print("The element to be searched: " + keyToSearch);
if (result != null) {
System.out.println("\nElement found");
} else {
System.out.println("\nElement not found");
}
}
}
Output
The element to be searched: 64 Element found
SIZE = 10 # Define the size of the hash table
class DataItem:
def __init__(self, key):
self.key = key
hashMap = {} # Define the hash table as a dictionary
def hashCode(key):
# Return a hash value based on the key
return key % SIZE
def search(key):
# get the hash
hashIndex = hashCode(key)
# move in map until an empty slot is found or the key is found
while hashIndex in hashMap:
# If the key is found, return the corresponding DataItem
if hashMap[hashIndex].key == key:
return hashMap[hashIndex]
# go to the next cell
hashIndex = (hashIndex + 1) % SIZE
# If the key is not found, return None
return None
# Initializing the hash table with some sample DataItems
item2 = DataItem(25) # Assuming the key is 25
item3 = DataItem(64) # Assuming the key is 64
item4 = DataItem(22) # Assuming the key is 22
# Calculate the hash index for each item and place them in the hash table
hashIndex2 = hashCode(item2.key)
hashMap[hashIndex2] = item2
hashIndex3 = hashCode(item3.key)
hashMap[hashIndex3] = item3
hashIndex4 = hashCode(item4.key)
hashMap[hashIndex4] = item4
# Call the search function to test it
keyToSearch = 64 # The key to search for in the hash table
result = search(keyToSearch)
print("The element to be searched: ", keyToSearch)
if result:
print("Element found")
else:
print("Element not found")
Output
The element to be searched: 64 Element found
Insert Operation
Whenever an element is to be inserted, compute the hash code of the key passed and locate the index using that hash code as an index in the array. Use linear probing for empty location, if an element is found at the computed hash code.
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
Example
Following are the implementations of this operation in various programming languages −
#include <stdio.h>
#include <stdlib.h>
#define SIZE 4 // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem *hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
void insert(int key) {
// Create a new DataItem using malloc
struct DataItem *newItem = (struct DataItem*)malloc(sizeof(struct DataItem));
if (newItem == NULL) {
// Check if malloc fails to allocate memory
fprintf(stderr, "Memory allocation error\n");
return;
}
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != NULL) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
}
int main() {
// Call the insert function with different keys to populate the hash table
insert(42); // Insert an item with key 42
insert(25); // Insert an item with key 25
insert(64); // Insert an item with key 64
insert(22); // Insert an item with key 22
// Output the populated hash table
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != NULL) {
printf("Index %d: Key %d\n", i, hashArray[i]->key);
} else {
printf("Index %d: Empty\n", i);
}
}
return 0;
}
Output
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
#include <iostream>
#include <vector>
#define SIZE 4 // Define the size of the hash table
struct DataItem {
int key;
};
std::vector<DataItem*> hashArray(SIZE, nullptr); // Define the hash table as a vector of DataItem pointers
int hashCode(int key)
{
// Return a hash value based on the key
return key % SIZE;
}
void insert(int key)
{
// Create a new DataItem using new (dynamic memory allocation)
DataItem *newItem = new DataItem;
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != nullptr) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
}
int main()
{
// Call the insert function with different keys to populate the hash table
insert(42); // Insert an item with key 42
insert(25); // Insert an item with key 25
insert(64); // Insert an item with key 64
insert(22); // Insert an item with key 22
// Output the populated hash table
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != nullptr) {
std::cout << "Index " << i << ": Key " << hashArray[i]->key << std::endl;
} else {
std::cout << "Index " << i << ": Empty" << std::endl;
}
}
return 0;
}
Output
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
import java.util.Arrays;
public class Main {
static final int SIZE = 4; // Define the size of the hash table
static class DataItem {
int key;
}
static DataItem[] hashArray = new DataItem[SIZE]; // Define the hash table as an array of DataItem pointers
static int hashCode(int key) {
// Return a hash value based on the key
return key % SIZE;
}
static void insert(int key) {
// Create a new DataItem
DataItem newItem = new DataItem();
newItem.key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != null) {
// Move to the next cell
hashIndex++;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
}
public static void main(String[] args) {
// Call the insert function with different keys to populate the hash table
insert(42); // Insert an item with key 42
insert(25); // Insert an item with key 25
insert(64); // Insert an item with key 64
insert(22); // Insert an item with key 22
// Output the populated hash table
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != null) {
System.out.println("Index " + i + ": Key " + hashArray[i].key);
} else {
System.out.println("Index " + i + ": Empty");
}
}
}
}
Output
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
SIZE = 4 # Define the size of the hash table
class DataItem:
def __init__(self, key):
self.key = key
hashArray = [None] * SIZE # Define the hash table as a list of DataItem pointers
def hashCode(key):
# Return a hash value based on the key
return key % SIZE
def insert(key):
# Create a new DataItem
newItem = DataItem(key)
# Initialize other data members if needed
# Calculate the hash index for the key
hashIndex = hashCode(key)
# Handle collisions (linear probing)
while hashArray[hashIndex] is not None:
# Move to the next cell
hashIndex += 1
# Wrap around the table if needed
hashIndex %= SIZE
# Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem
# Call the insert function with different keys to populate the hash table
insert(42) # Insert an item with key 42
insert(25) # Insert an item with key 25
insert(64) # Insert an item with key 64
insert(22) # Insert an item with key 22
# Output the populated hash table
for i in range(SIZE):
if hashArray[i] is not None:
print(f"Index {i}: Key {hashArray[i].key}")
else:
print(f"Index {i}: Empty")
Output
Index 0: Key 64 Index 1: Key 25 Index 2: Key 42 Index 3: Key 22
Delete Operation
Whenever an element is to be deleted, compute the hash code of the key passed and locate the index using that hash code as an index in the array. Use linear probing to get the element ahead if an element is not found at the computed hash code. When found, store a dummy item there to keep the performance of the hash table intact.
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
Example
Following are the implementations of the deletion operation for Hash Table in various programming languages −
#include <stdio.h>
#include <stdlib.h>
#define SIZE 5 // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem *hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Implement your hash function here
// Return a hash value based on the key
}
void insert(int key) {
// Create a new DataItem using malloc
struct DataItem *newItem = (struct DataItem*)malloc(sizeof(struct DataItem));
if (newItem == NULL) {
// Check if malloc fails to allocate memory
fprintf(stderr, "Memory allocation error\n");
return;
}
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != NULL) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
// Print the inserted item's key and hash index
printf("Inserted key %d at index %d\n", newItem->key, hashIndex);
}
void delete(int key) {
// Find the item in the hash table
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != NULL) {
if (hashArray[hashIndex]->key == key) {
// Mark the item as deleted (optional: free memory)
free(hashArray[hashIndex]);
hashArray[hashIndex] = NULL;
return;
}
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// If the key is not found, print a message
printf("Item with key %d not found.\n", key);
}
int main() {
// Call the insert function with different keys to populate the hash table
printf("Hash Table Contents before deletion:\n");
insert(1); // Insert an item with key 42
insert(2); // Insert an item with key 25
insert(3); // Insert an item with key 64
insert(4); // Insert an item with key 22
int ele1 = 2;
int ele2 = 4;
printf("The key to be deleted: %d and %d", ele1, ele2);
delete(ele1); // Delete an item with key 42
delete(ele2); // Delete an item with key 25
// Print the hash table's contents after delete operations
printf("\nHash Table Contents after deletion:\n");
for (int i = 1; i < SIZE; i++) {
if (hashArray[i] != NULL) {
printf("Index %d: Key %d\n", i, hashArray[i]->key);
} else {
printf("Index %d: Empty\n", i);
}
}
return 0;
}
Output
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The key to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
#include <iostream>
using namespace std;
const int SIZE = 5; // Define the size of the hash table
struct DataItem {
int key;
};
struct DataItem* hashArray[SIZE]; // Define the hash table as an array of DataItem pointers
int hashCode(int key) {
// Implement your hash function here
// Return a hash value based on the key
// A simple hash function (modulo division)
return key % SIZE;
}
void insert(int key) {
// Create a new DataItem using new
struct DataItem* newItem = new DataItem;
newItem->key = key;
// Initialize other data members if needed
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != nullptr) {
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = newItem;
// Print the inserted item's key and hash index
cout << "Inserted key " << newItem->key << " at index " << hashIndex << endl;
}
void deleteItem(int key) {
// Find the item in the hash table
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != nullptr) {
if (hashArray[hashIndex]->key == key) {
// Mark the item as deleted (optional: free memory)
delete hashArray[hashIndex];
hashArray[hashIndex] = nullptr;
return;
}
// Move to the next cell
++hashIndex;
// Wrap around the table if needed
hashIndex %= SIZE;
}
// If the key is not found, print a message
cout << "Item with key " << key << " not found." << endl;
}
int main() {
// Call the insert function with different keys to populate the hash table
cout<<"Hash Table Contents before deletion:\n";
insert(1); // Insert an item with key 42
insert(2); // Insert an item with key 25
insert(3); // Insert an item with key 64
insert(4); // Insert an item with key 22
int ele1 = 2;
int ele2 = 4;
cout<<"The key to be deleted: "<<ele1<<" and "<<ele2<<"\n";
deleteItem(2); // Delete an item with key 42
deleteItem(4); // Delete an item with key 25
cout<<"Hash Table Contents after deletion:\n";
// Print the hash table's contents after delete operations
for (int i = 1; i < SIZE; i++) {
if (hashArray[i] != nullptr) {
cout << "Index " << i << ": Key " << hashArray[i]->key << endl;
} else {
cout << "Index " << i << ": Empty" << endl;
}
}
return 0;
}
Output
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The key to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
public class Main {
static final int SIZE = 5; // Define the size of the hash table
static class DataItem {
int key;
DataItem(int key) {
this.key = key;
}
}
static DataItem[] hashArray = new DataItem[SIZE]; // Define the hash table as an array of DataItem objects
static int hashCode(int key) {
// Implement your hash function here
// Return a hash value based on the key
return key % SIZE; // A simple hash function using modulo operator
}
static void insert(int key) {
// Calculate the hash index for the key
int hashIndex = hashCode(key);
// Handle collisions (linear probing)
while (hashArray[hashIndex] != null) {
// Move to the next cell
hashIndex = (hashIndex + 1) % SIZE;
}
// Insert the new DataItem at the calculated index
hashArray[hashIndex] = new DataItem(key);
// Print the inserted item's key and hash index
System.out.println("Inserted key " + key + " at index " + hashIndex);
}
static void delete(int key) {
// Find the item in the hash table
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null) {
if (hashArray[hashIndex].key == key) {
// Mark the item as deleted (optional: free memory)
hashArray[hashIndex] = null;
// Print the deleted item's key and hash index
return;
}
// Move to the next cell
hashIndex = (hashIndex + 1) % SIZE;
}
// If the key is not found, print a message
System.out.println("Item with key " + key + " not found.");
}
public static void main(String[] args) {
// Call the insert function with different keys to populate the hash table
System.out.println("Hash Table Contents before deletion: ");
insert(1); // Insert an item with key 1
insert(2); // Insert an item with key 2
insert(3); // Insert an item with key 3
insert(4); // Insert an item with key 4
int ele1 = 2;
int ele2 = 4;
System.out.print("The keys to be deleted: " + ele1 + " and " + ele2);
delete(ele1); // Delete an item with key 2
delete(ele2); // Delete an item with key 4
// Print the hash table's contents after delete operations
System.out.println("\nHash Table Contents after deletion:");
for (int i = 1; i < SIZE; i++) {
if (hashArray[i] != null) {
System.out.println("Index " + i + ": Key " + hashArray[i].key);
} else {
System.out.println("Index " + i + ": Empty");
}
}
}
}
Output
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The keys to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
SIZE = 5 # Define the size of the hash table
class DataItem:
def __init__(self, key):
self.key = key
def hashCode(key):
# Implement your hash function here
# Return a hash value based on the key
return key % SIZE
def insert(key):
global hashArray # Access the global hashArray variable
# Calculate the hash index for the key
hashIndex = hashCode(key)
# Handle collisions (linear probing)
while hashArray[hashIndex] is not None:
# Move to the next cell
hashIndex = (hashIndex + 1) % SIZE
# Insert the new DataItem at the calculated index
hashArray[hashIndex] = DataItem(key)
# Print the inserted item's key and hash index
print(f"Inserted key {key} at index {hashIndex}")
def delete(key):
global hashArray # Access the global hashArray variable
# Find the item in the hash table
hashIndex = hashCode(key)
while hashArray[hashIndex] is not None:
if hashArray[hashIndex].key == key:
# Mark the item as deleted (optional: free memory)
hashArray[hashIndex] = None
return
# Move to the next cell
hashIndex = (hashIndex + 1) % SIZE
# If the key is not found, print a message
print(f"Item with key {key} not found.")
# Initialize the hash table as a list of None values
hashArray = [None] * SIZE
print("Hash Table Contents before deletion:")
# Call the insert function with different keys to populate the hash table
insert(1) # Insert an item with key 1
insert(2) # Insert an item with key 2
insert(3) # Insert an item with key 3
insert(4) # Insert an item with key 4
ele1 = 2
ele2 = 4
print("The keys to be deleted: ", ele1, " and ", ele2)
delete(2) # Delete an item with key 2
delete(4) # Delete an item with key 4
# Print the hash table's contents after delete operations
print("Hash Table Contents after deletion:")
for i in range(1, SIZE):
if hashArray[i] is not None:
print(f"Index {i}: Key {hashArray[i].key}")
else:
print(f"Index {i}: Empty")
Output
Hash Table Contents before deletion: Inserted key 1 at index 1 Inserted key 2 at index 2 Inserted key 3 at index 3 Inserted key 4 at index 4 The keys to be deleted: 2 and 4 Hash Table Contents after deletion: Index 1: Key 1 Index 2: Empty Index 3: Key 3 Index 4: Empty
Complete implementation
Following are the complete implementations of the above operations in various programming languages −
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define SIZE 20
struct DataItem {
int data;
int key;
};
struct DataItem* hashArray[SIZE];
struct DataItem* dummyItem;
struct DataItem* item;
int hashCode(int key) {
return key % SIZE;
}
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void display() {
int i = 0;
for(i = 0; i<SIZE; i++) {
if(hashArray[i] != NULL)
printf("(%d,%d) ",hashArray[i]->key,hashArray[i]->data);
}
printf("\n");
}
int main() {
dummyItem = (struct DataItem*) malloc(sizeof(struct DataItem));
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
printf("Insertion done: \n");
printf("Contents of Hash Table: ");
display();
int ele = 37;
printf("The element to be searched: %d", ele);
item = search(ele);
if(item != NULL) {
printf("\nElement found: %d\n", item->key);
} else {
printf("\nElement not found\n");
}
delete(item);
printf("Hash Table contents after deletion: ");
display();
}
Output
Insertion done: Contents of Hash Table: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (37,97) The element to be searched: 37 Element found: 37 Hash Table contents after deletion: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (-1,-1)
#include <iostream>
#include <vector>
using namespace std;
using namespace std;
#define SIZE 20
struct DataItem {
int data;
int key;
};
std::vector<DataItem*> hashArray(SIZE, nullptr);
DataItem* dummyItem;
DataItem* item;
int hashCode(int key) {
return key % SIZE;
}
DataItem* search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while (hashArray[hashIndex] != nullptr) {
if (hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
//wrap around the table
hashIndex = (hashIndex + 1) % SIZE;
}
return nullptr;
}
void insert(int key, int data) {
DataItem* item = new DataItem;
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while (hashArray[hashIndex] != nullptr && hashArray[hashIndex]->key != -1) {
hashIndex = (hashIndex + 1) % SIZE;
}
hashArray[hashIndex] = item;
}
DataItem* deleteItem(DataItem* item) {
int key = item->key;
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != nullptr) {
if (hashArray[hashIndex]->key == key) {
DataItem* temp = hashArray[hashIndex];
hashArray[hashIndex] = dummyItem;
return temp;
}
hashIndex = (hashIndex + 1) % SIZE;
}
return nullptr;
}
void display() {
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != nullptr)
cout << " (" << hashArray[i]->key << "," << hashArray[i]->data << ")";
}
cout << std::endl;
}
int main() {
dummyItem = new DataItem;
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
cout<<"Insertion Done";
cout<<"\nContents of Hash Table: ";
display();
int ele = 37;
cout<<"The element to be searched: "<<ele;
item = search(ele);
if (item != nullptr) {
cout << "\nElement found: " << item->key;
} else {
cout << "\nElement not found" << item->key;
}
// Clean up allocated memory
delete(item);
cout<<"\nHash Table contents after deletion: ";
display();
}
Output
Insertion Done Contents of Hash Table: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (37,97) The element to be searched: 37 Element found: 37 Hash Table contents after deletion: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (5,1666768001)
public class HashTableExample {
static final int SIZE = 20;
static class DataItem {
int data;
int key;
DataItem(int data, int key) {
this.data = data;
this.key = key;
}
}
static DataItem[] hashArray = new DataItem[SIZE];
static DataItem dummyItem = new DataItem(-1, -1);
static DataItem item;
static int hashCode(int key) {
return key % SIZE;
}
static DataItem search(int key) {
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null) {
if (hashArray[hashIndex].key == key)
return hashArray[hashIndex];
hashIndex = (hashIndex + 1) % SIZE;
}
return null;
}
static void insert(int key, int data) {
DataItem item = new DataItem(data, key);
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null && hashArray[hashIndex].key != -1) {
hashIndex = (hashIndex + 1) % SIZE;
}
hashArray[hashIndex] = item;
}
static DataItem deleteItem(DataItem item) {
int key = item.key;
int hashIndex = hashCode(key);
while (hashArray[hashIndex] != null) {
if (hashArray[hashIndex].key == key) {
DataItem temp = hashArray[hashIndex];
hashArray[hashIndex] = dummyItem;
return temp;
}
hashIndex = (hashIndex + 1) % SIZE;
}
return null;
}
static void display() {
for (int i = 0; i < SIZE; i++) {
if (hashArray[i] != null)
System.out.print(" (" + hashArray[i].key + "," + hashArray[i].data + ")");
}
System.out.println();
}
public static void main(String[] args) {
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
System.out.print("Insertion done");
System.out.print("\nContents of Hash Table:");
display();
int ele = 37;
System.out.print("The element to be searched: " + ele);
item = search(37);
if (item != null) {
System.out.println("\nElement found: " + item.key);
} else {
System.out.println("\nElement not found");
}
deleteItem(item);
System.out.print("Hash Table contents after deletion:");
display();
}
}
Output
Insertion done Contents of Hash Table: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (37,97) The element to be searched: 37 Element found: 37 Hash Table contents after deletion: (1,20) (2,70) (42,80) (4,25) (12,44) (13,78) (14,32) (17,11) (-1,-1)
SIZE = 20
class DataItem:
def __init__(self, data, key):
self.data = data
self.key = key
# Initialize the hash array with None values
hashArray = [None] * SIZE
# Create a dummy item to mark deleted cells in the hash table
dummyItem = DataItem(-1, -1)
# Variable to hold the item found in the search operation
item = None
# Hash function to calculate the hash index for the given key
def hashCode(key):
return key % SIZE
# Function to search for an item in the hash table by its key
def search(key):
# Calculate the hash index using the hash function
hashIndex = hashCode(key)
# Traverse the array until an empty cell is encountered
while hashArray[hashIndex] is not None:
if hashArray[hashIndex].key == key:
# Item found, return the item
return hashArray[hashIndex]
# Move to the next cell (linear probing)
hashIndex = (hashIndex + 1) % SIZE
# If the loop terminates without finding the item, it means the item is not present
return None
# Function to insert an item into the hash table
def insert(key, data):
# Create a new DataItem object
item = DataItem(data, key)
# Calculate the hash index using the hash function
hashIndex = hashCode(key)
# Handle collisions using linear probing (move to the next cell until an empty cell is found)
while hashArray[hashIndex] is not None and hashArray[hashIndex].key != -1:
hashIndex = (hashIndex + 1) % SIZE
# Insert the item into the hash table at the calculated index
hashArray[hashIndex] = item
# Function to delete an item from the hash table
def deleteItem(item):
key = item.key
# Calculate the hash index using the hash function
hashIndex = hashCode(key)
# Traverse the array until an empty or deleted cell is encountered
while hashArray[hashIndex] is not None:
if hashArray[hashIndex].key == key:
# Item found, mark the cell as deleted by replacing it with the dummyItem
temp = hashArray[hashIndex]
hashArray[hashIndex] = dummyItem
return temp
# Move to the next cell (linear probing)
hashIndex = (hashIndex + 1) % SIZE
# If the loop terminates without finding the item, it means the item is not present
return None
# Function to display the hash table
def display():
for i in range(SIZE):
if hashArray[i] is not None:
# Print the key and data of the item at the current index
print(" ({}, {})".format(hashArray[i].key, hashArray[i].data), end="")
else:
# Print ~~ for an empty cell
print(" ~~ ", end="")
print()
if __name__ == "__main__":
# Test the hash table implementation
# Insert some items into the hash table
insert(1, 20)
insert(2, 70)
insert(42, 80)
insert(4, 25)
insert(12, 44)
insert(14, 32)
insert(17, 11)
insert(13, 78)
insert(37, 97)
print("Insertion done")
print("Hash Table contents: ");
# Display the hash table
display()
display()
# Search for an item with a specific key (37)
item = search(37)
# Check if the item was found or not and print the result
if item is not None:
print("Element found:", item.data)
else:
print("Element not found")
# Delete the item with key 37 from the hash table
deleteItem(item)
# Search again for the item with key 37 after deletion
item = search(37)
# Check if the item was found or not and print the result
if item is not None:
print("Element found:", item.data)
else:
print("Element not found")
Output
~~ (1, 20) (2, 70) (42, 80) (4, 25) ~~ ~~ ~~ ~~ ~~ ~~ ~~ (12, 44) (13, 78) (14, 32) ~~ ~~ (17, 11) (37, 97) ~~ Element found: 97 Element not found
