- AWS ElastiCache Tutorial
- Home
- Overview
- Environment
- Interfaces
- Launching Cluster
- Viewing Cluster Details
- Cluster Endpoints
- Accessing Cluster
- Modifying Cluster
- Rebooting Cluster
- Adding Nodes
- Removing Nodes
- Scaling the Clusters
- Delete Cluster
- Redis Shards
- Parameter Group
- Listing Parameters
- Deleting Parameters
- Engine Parameters
- Backup and Restore
- Monitoring Node - Metrics
- Memcached & Redis
- Accessing Memcached Cluster
- Lazy Loading
- Write Through
- Add TTL
- Memcached VPC
- Creating Memcached Cluster
- Connecting to Cluster in VPC
- Delete Memcached Cluster
- IAM policies
- SNS Notifications
- Events
- Managing Tags
- Managing Costs
- AWS ElastiCache - Resources
- Quick Guide
- Useful Resources
- Discussion
WS ElastiCache - Backup and Restore
AWS ElastiCache clusters running Redis can be used to create back up which then can be used to restore a cluster or seed a new cluster. The backup is made up of the cluster's metadata, along with all of the data in the cluster. All backups are written to Amazon Simple Storage Service (Amazon S3). At any time, you can restore your data by creating a new Redis cluster and populating it with data from a backup. One backup for each cluster is stored free of charge but additional backups have a cost associated with them.
Below are the steps for creating the backup.
Selecting the Cluster
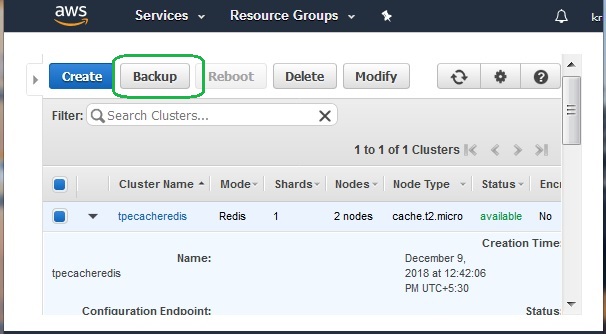
We login to the AWS console and go to the ElastiCache dashboard. From the dashboard in the left we choose the cluster type as Redis. Then we see the name of the cluster as a hyperlink in the ElastiCache dashboard. We click on the check box to the left of the name of the cluster. This shows the option to back up the cluster along with other options.
Creating Backup
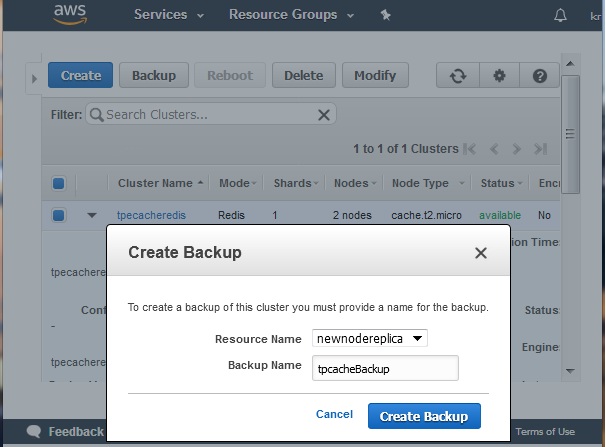
Next, we click on the backup button to configure the backup process by providing the name for the backup cluster. The backup method is selected automatically based upon available memory. If there is sufficient available memory, a child process is spawned which writes all changes to the cache's reserved memory while the cache is being backed up.
If there is insufficient memory available, a forkless, cooperative background process is employed. The forkless method can impact both latency and throughput.
On clicking the backup button, the backup process starts, and it continues for a while. As we can see in the diagram below, the status of the process remains as creating. It also mentions the cache size and backup type as manual.
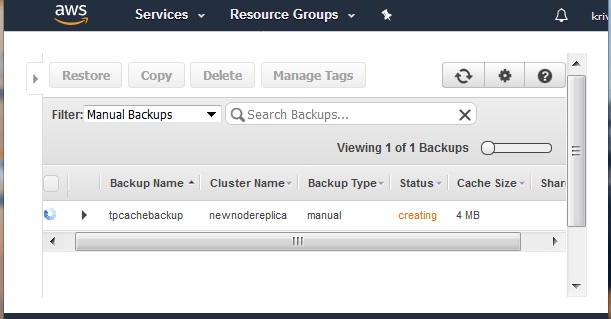
After a while the status of the new backup cluster changes to available. This indicates the completion of the backup process.
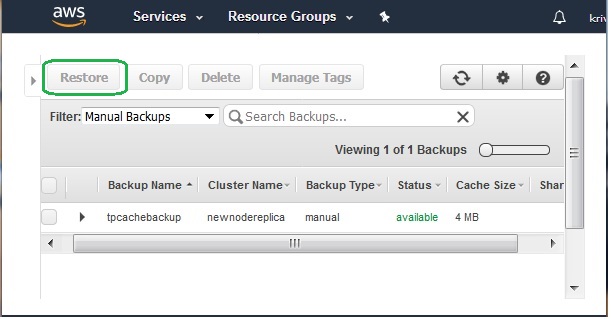
Restore from Backup
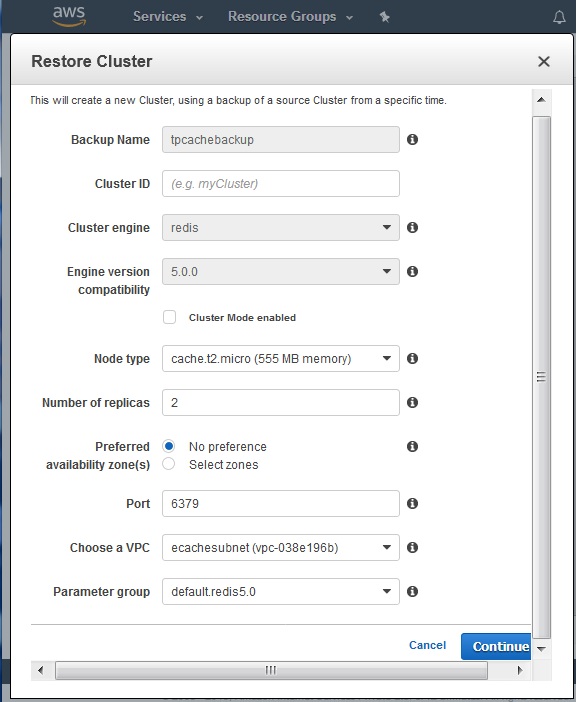
To use the backup for restoring data, we create a new cluster from the above backup. This new copy will be used for the restore command which will bring in data from backup to the newly created cluster.
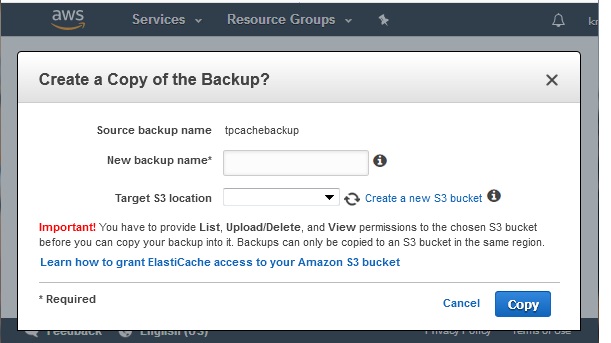
After the creation of the new cluster, we finally use the restore button. In the diagram below, we supply the values for the restore option.