- CUDA - Home
- CUDA - Introduction
- CUDA - Introduction to the GPU
- Fixed Functioning Graphics Pipelines
- CUDA - Key Concepts
- Keywords and Thread Organization
- CUDA - Installation
- CUDA - Matrix Multiplication
- CUDA - Threads
- CUDA - Performance Considerations
- CUDA - Memories
- CUDA - Memory Considerations
- Reducing Global Memory Traffic
- CUDA - Caches
CUDA - Memories
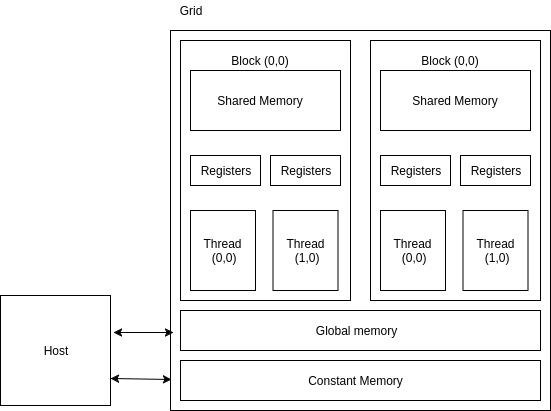
Apart from the device DRAM, CUDA supports several additional types of memory that can be used to increase the CGMA ratio for a kernel. We know that accessing the DRAM is slow and expensive. To overcome this problem, several low-capacity, high-bandwidth memories, both on-chip and off-chip are present on a CUDA GPU. If some data is used frequently, then CUDA caches it in one of the low-level memories. Thus, the processor does not need to access the DRAM every time. The following figure illustrates the memory architecture supported by CUDA and typically found on Nvidia cards −
Device code
- R/W per-thread registers
- R/W per-thread local memory
- R/W per-block shared memory
- R/W per-grid global memory
- Read only per-grid constant memory
Host code
This helps in transferring data to/from per grid global and constant memories.
The global memory is a high-latency memory (the slowest in the figure). To increase the arithmetic intensity of our kernel, we want to reduce as many accesses to the global memory as possible. One thing to note about global memory is that there is no limitation on what threads may access it. All the threads of any block can access it. There are no restrictions, like there are in the case of shared memory or registers.
The constant memory can be written into and read by the host. It is used for storing data that will not change over the course of kernel execution. It supports short-latency, high-bandwidth, read-only access by the device when all threads simultaneously access the same location. There is a total of 64K constant memory on a CUDA capable device. The constant memory is cached. For all threads of a half warp, reading from the constant cache, as long as all threads read the same address, is no slower than reading from a register. However, if threads of the half-warp access different memory locations, the access time scales linearly with the number of different addresses read by all threads within the half-warp.
How does constant memory work?
For devices with CUDA capabilities 1.x, the following are the steps that are followed when a constant memory access is done by a warp −
The request is broken into two parts, one for each half-wrap. That is, two constant memory accesses will take place for a single request.
The request for each half-warp is split into as many discrete requests as there are different memory addresses in the initial request, decreasing the throughput by a factor equal to the number of separate requests. The cost increases linearly. If there is just one memory address that is accessed, then the access is as fast as it is from a register.
If there is a cache hit, then the resulting data is serviced at the bandwidth of the cache.
In case of a cache miss, the resulting data is serviced at the bandwidth of the DRAM.
The __constant__ keyword can be used to store a variable in constant memory. They are always declared as global variables.
Registers and shared-memory are on-chip memories. Variables that are stored in these memories are accessed at a very high speed in a highly parallel manner. A thread is allocated a set of registers, and it cannot access registers that are not parts of that set. A kernel generally stores frequently used variables that are private to each thread in registers. The cost of accessing variables from registers is less than that required to access variables from the global memory.
SM 2.0 GPUs support up to 63 registers per thread. If this limit is exceeded, the values will be spilled from local memory, supported by the cache hierarchy. SM 3.5 GPUs expand this to up to 255 registers per thread.
Shared Memory
All threads of a block can access its shared memory. Shared memory can be used for inter-thread communication. Each block has its own shared-memory. Just like registers, shared memory is also on-chip, but they differ significantly in functionality and the respective access cost.
While accessing data from the shared memory, the processor needs to do a memory load operation, just like accessing data from the global memory. This makes them slower than registers, in which the LOAD operation is not required. Since it resides on-chip, shared memory has shorter latency and higher bandwidth than global memory. Shared memory is also called scratchpad memory in computer architecture parlance.
Variable Lifetime
Lifetime of a variable tells the portion of the programs execution duration when it is available for use. If a variables lifetime is within the kernel, then it will be available for use only by the kernel code. An important point to note here is that multiple invocations of the kernel do not maintain the value of the variable across them.
Automatic Variables
Automatic variables are those variables for which a copy exists for each thread. In the matrix multiplication example, row and col are automatic variables. A private copy of row and col exists for each thread, and once the thread finishes execution, its automatic variables are destroyed.
The following table summarizes the lifetime, scope and memory of different types of CUDA variables −
| Variable declaration | Memory | Scope | Lifetime |
|---|---|---|---|
| Automatic variables other than arrays | Register | Thread | Kernel |
| Automatic array variables | Local | Thread | Kernel |
| __device__ __shared__ int sharedVar | Shared | Block | Kernel |
| __device__ int globalVar | Global | Grid | Application |
| __device__ __constant__ int constVar | Constant | Grid | Application |
Constant variables are stored in the global memory (constant memory), but are cached for efficient access. They can be accessed in a highly-parallel manner at high-speeds. As their lifetime equals the lifetime of the application, and they are visible to all the threads, declaration of constant variables must be done outside any function.
Memory as a Bottleneck
Although shared memory and registers are high-speed memories with huge bandwidth, they are available in limited amounts in a CUDA device. A programmer should be careful not to overuse these limited resources. The limited amount of these resources also caps the number of threads that can actually execute in parallel in a SM for a given application. The more resources a thread requires, the less the number of threads that can simultaneously reside in the SM. It is simply because there is a dearth of resources.
Let us suppose that each SM can accommodate upto 1536 threads and has 16,384 registers. To accommodate 1536 threads, each thread can use no more than 16,384/1536 = 10 registers. If each threads requires 12 registers, the number of threads that can simultaneously reside in the SM is reduced. Such reduction is done per block. If each block contains 128 threads, the reduction of threads will be done by reducing 128 threads at a time.
Shared memory usage can also limit the number of threads assigned to each SM. Suppose that a CUDA GPU has 16k/SM of shared memory. Suppose that each SM can support upto 8 blocks. To reach the maximum, each block must use no more than 2k of shared memory. If each block uses 5k of shared memory, then no more than 3 blocks can live in a SM.
