- CUDA - Home
- CUDA - Introduction
- CUDA - Introduction to the GPU
- Fixed Functioning Graphics Pipelines
- CUDA - Key Concepts
- Keywords and Thread Organization
- CUDA - Installation
- CUDA - Matrix Multiplication
- CUDA - Threads
- CUDA - Performance Considerations
- CUDA - Memories
- CUDA - Memory Considerations
- Reducing Global Memory Traffic
- CUDA - Caches
CUDA - Key Concepts
In this chapter, we will learn about a few key concepts related to CUDA. We will understand data parallelism, the program structure of CUDA and how a CUDA C Program is executed.
Data Parallelism
Modern applications process large amounts of data that incur significant execution time on sequential computers. An example of such an application is rendering pixels. For example, an application that converts sRGB pixels to grayscale. To process a 1920x1080 image, the application has to process 2073600 pixels.
Processing all those pixels on a traditional uniprocessor CPU will take a very long time since the execution will be done sequentially. (The time taken will be proportional to the number of pixels in the image). Further, it is very inefficient since the operation that is performed on each pixel is the same, but different on the data (SPMD). Since processing one pixel is independent of the processing of any other pixel, all the pixels can be processed in parallel. If we use 2073600 threads (workers) and each thread processes one pixel, the task can be reduced to constant time. Millions of such threads can be launched on modern GPUs.
As has already been explained in the previous chapters, GPU is traditionally used for rendering graphics. For example, per-pixel lighting is a highly parallel, and data-intensive task and a GPU is perfect for the job. We can map each pixel with a thread and they all can be processed in O(1) constant time.
Image processing and computer graphics are not the only areas in which we harness data parallelism to our advantage. Many high-performance algebra libraries today such as CU-BLAS harness the processing power of the modern GPU to perform data intensive algebra operations. One such operation, matrix multiplication has been explained in the later sections.
Program Structure of CUDA
A typical CUDA program has code intended both for the GPU and the CPU. By default, a traditional C program is a CUDA program with only the host code. The CPU is referred to as the host, and the GPU is referred to as the device. Whereas the host code can be compiled by a traditional C compiler as the GCC, the device code needs a special compiler to understand the api functions that are used. For Nvidia GPUs, the compiler is called the NVCC (Nvidia C Compiler).
The device code runs on the GPU, and the host code runs on the CPU. The NVCC processes a CUDA program, and separates the host code from the device code. To accomplish this, special CUDA keywords are looked for. The code intended to run of the GPU (device code) is marked with special CUDA keywords for labelling data-parallel functions, called Kernels. The device code is further compiled by the NVCC and executed on the GPU.
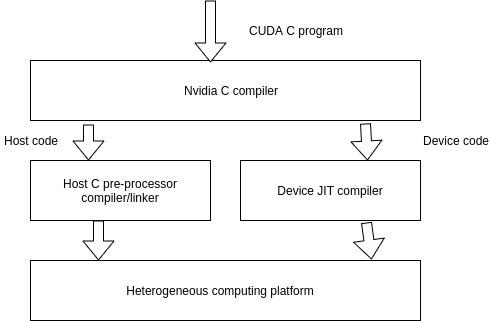
Execution of a CUDA C Program
How does a CUDA program work? While writing a CUDA program, the programmer has explicit control on the number of threads that he wants to launch (this is a carefully decided-upon number). These threads collectively form a three-dimensional grid (threads are packed into blocks, and blocks are packed into grids). Each thread is given a unique identifier, which can be used to identify what data it is to be acted upon.
Device Global Memory and Data Transfer
As has been explained in the previous chapter, a typical GPU comes with its own global memory (DRAM- Dynamic Random Access Memory). For example, the Nvidia GTX 480 has DRAM size equal to 4G. From now on, we will call this memory the device memory.
To execute a kernel on the GPU, the programmer needs to allocate separate memory on the GPU by writing code. The CUDA API provides specific functions for accomplishing this. Here is the flow sequence −
After allocating memory on the device, data has to be transferred from the host memory to the device memory.
After the kernel is executed on the device, the result has to be transferred back from the device memory to the host memory.
The allocated memory on the device has to be freed-up. The host can access the device memory and transfer data to and from it, but not the other way round.
CUDA provides API functions to accomplish all these steps.
