- CUDA - Home
- CUDA - Introduction
- CUDA - Introduction to the GPU
- Fixed Functioning Graphics Pipelines
- CUDA - Key Concepts
- Keywords and Thread Organization
- CUDA - Installation
- CUDA - Matrix Multiplication
- CUDA - Threads
- CUDA - Performance Considerations
- CUDA - Memories
- CUDA - Memory Considerations
- Reducing Global Memory Traffic
- CUDA - Caches
CUDA - Introduction
CUDA − Compute Unified Device Architecture. It is an extension of C programming, an API model for parallel computing created by Nvidia. Programs written using CUDA harness the power of GPU. Thus, increasing the computing performance.
Parallelism in the CPU
Gordon Moore of Intel once famously stated a rule, which said that every passing year, the clock frequency of a semiconductor core doubles. This law held true until recent years. Now, as the clock frequencies of a single core reach saturation points (you will not find a single core CPU with a clock frequency of say, 5GHz, even after 2 years from now), the paradigm has shifted to multi-core and many-core processors.
In this chapter, we will study how parallelism is achieved in CPUs. This chapter is an essential foundation to studying GPUs (it helps in understanding the key differences between GPUs and CPUs).
Following are the five essential steps required for an instruction to finish −
- Instruction fetch (IF)
- Instruction decode (ID)
- Instruction execute (Ex)
- Memory access (Mem)
- Register write-back (WB)
This is a basic five-stage RISC architecture.
There are multiple ways to achieve parallelism in the CPU. First, we will discuss about ILP (Instruction Level Parallelism), also known as pipelining.
Pipelining
A CPU pipeline is a series of instructions that a CPU can handle in parallel per clock. A basic CPU with no ILP will execute the above five steps sequentially. In fact, any CPU will do that. It will first fetch the instructions, decode them, execute them, then access the RAM, and then write-back to the registers. Thus, it needs at least five CPU cycles to execute an instruction. During this process, there are parts of the chip that are sitting idle, waiting for the current instruction to finish. This is highly inefficient and this is exactly what instruction pipelining tries to address. Instead now, in one clock cycle, there are many steps of different instructions that execute in parallel. Thus the name, Instruction Level Parallelism.
The following figure will help you understand how Instruction Level Parallelism works −
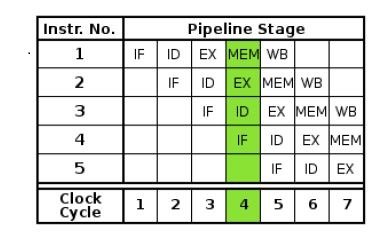
Using instruction pipelining, the instruction throughput has increased. Now, we can process many instructions in one-clock cycle. But for ILP, the resources of a chip would have been sitting idle.
In a pipe-lined chip, the instruction throughput increased. Initially, one instruction completed after every 5 cycles. Now, at the end of each cycle (from the 5th cycle onwards, considering each step takes 1 cycle), we get a completed instruction.
Note that in a non-pipelined chip, where it is assumed that the next instruction begins only when the current has finished, there is no data hazard. But since such is not the case with a pipelined chip, hazards may arise. Consider the situation below −
- I1 − ADD 1 to R5
- I2 − COPY R5 to R6
Now, in a pipeline processor, I1 starts at t1, and finishes at t5. I2 starts at t2 and finishes at t6. 1 is added to R5 at t5 (at the WB stage). The second instruction reads the value of R5 at its second step (at time t3). Thus, it will not fetch the update value, and this presents a hazard.
Modern compilers decode high-level code to low-level code, and take care of hazards.
Superscalar
ILP is also implemented by implementing a superscalar architecture. The primary difference between a superscalar and a pipelined processor is (a superscalar processor is also pipeline) that the former uses multiple execution units (on the same chip) to achieve ILP whereas the latter divides the EU in multiple phases to do that. This means that in superscalar, several instructions can simultaneously be in the same stage of the execution cycle. This is not possible in a simple pipelined chip. Superscalar microprocessors can execute two or more instructions at the same time. They typically have at least 2 ALUs.
Superscalar processors can dispatch multiple instructions in the same clock cycle. This means that multiple instructions can be started in the same clock cycle. If you look at the pipelines architecture above, you can observe that at any clock cycle, only one instruction is dispatched. This is not the case with superscalars. But we have only one instruction counter (in-flight, multiple instructions are tracked). This is still just one process.
Take the Intel i7 for instance. The processor boasts of 4 independent cores, each implementing the full x86 ISA. Each core is hyper-threaded with two hardware cores.
Hyper-threading is a dope technology, proprietary to Intel, using which the operating system see a single core as two virtual cores, for increasing the number of hardware instructions in the pipeline (note that not all operating systems support HT, and Intel recommends that in such cases, HT be disabled). So, the Intel i7 has a total of 8 hardware threads.
SMT
HT is just a technology to utilize a processor core better. Many a times, a processor core is utilizing only a fraction of its resources to execute instructions. What HT does is that it takes a few more CPU registers, and executes more instructions on the part of the core that is sitting idle. Thus, one core now appears as two core. It is to be considered that they are not completely independent. If both the cores need to access the CPU resource, one of them ends up waiting. That is the reason why we cannot replace a dual-core CPU with a hyper-threaded, single core CPU. A dual core CPU will have truly independent, out-of-order cores, each with its own resources. Also note that HT is Intels implementation of SMT (Simultaneous Multithreading). SPARC has a different implementation of SMT, with identical goals.
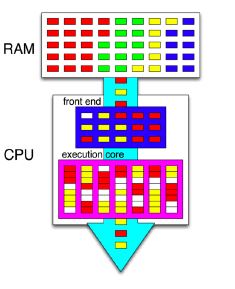
The pink box represents a single CPU core. The RAM contains instructions of 4 different programs, indicated by different colors. The CPU implements the SMT, using a technology similar to hyper-threading. Hence, it is able to run instructions of two different programs (red and yellow) simultaneously. White boxes represent pipeline stalls.
So, there are multi-core CPUs. One thing to notice is that they are designed to fasten-up sequential programs. A CPU is very good when it comes to executing a single instruction on a single datum, but not so much when it comes to processing a large chunk of data. A CPU has a larger instruction set than a GPU, a complex ALU, a better branch prediction logic, and a more sophisticated caching/pipeline schemes. The instruction cycles are also a lot faster.
