- Home
- Overview
- Environment
- Interfaces
- Launching Cluster
- Viewing Cluster Details
- Cluster Endpoints
- Accessing Cluster
- Modifying Cluster
- Rebooting Cluster
- Adding Nodes
- Removing Nodes
- Scaling the Clusters
- Delete Cluster
- Redis Shards
- Parameter Group
- Listing Parameters
- Deleting Parameters
- Engine Parameters
- Backup and Restore
- Monitoring Node - Metrics
- Memcached & Redis
- Accessing Memcached Cluster
- Lazy Loading
- Write Through
- Add TTL
- Memcached VPC
- Creating Memcached Cluster
- Connecting to Cluster in VPC
- Delete Memcached Cluster
- IAM policies
- SNS Notifications
- Events
- Managing Tags
- Managing Costs
- AWS ElastiCache - Resources
- Quick Guide
- Useful Resources
- Discussion
AWS ElastiCache - Write Through
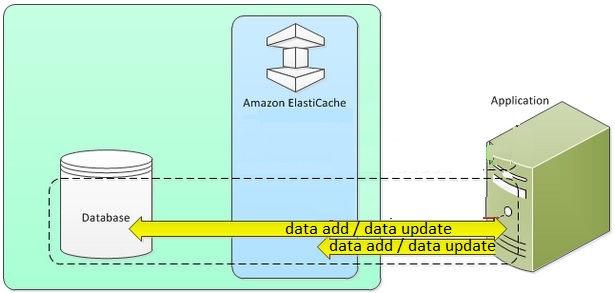
Like lazy loading, write through is another caching strategy but unlike lazy loading, it does not wait for a hit or miss. It is a straight forward strategy in which the syncing between cache and database happens as soon as some data is written into the database.
It can be easily understood from the below diagram.
Advantages of Write Through
Data in the cache is never stale − Since the data in the cache is updated every time it is written to the database, the data in the cache is always current.
Write penalty vs. Read penalty − Every write involves two trips, a write to the cache and a write to the database.
This adds latency to the process. That said, end users are generally more tolerant of latency when updating data than when retrieving data. There is an inherent sense that updates are more work and thus take longer.
Disadvantages of Write Through
Missing data − In the case of spinning up a new node, whether due to a node failure or scaling out, there is missing data which continues to be missing until it is added or updated on the database. This can be minimized by implementing Lazy Loading in conjunction with Write Through.
Cache churn − Since most data is never read, there can be a lot of data in the cluster that is never read. This is a waste of resources. By Adding TTL you can minimize wasted space, which we will see in the next chapter.
