- Data Structures & Algorithms
- DSA - Home
- DSA - Overview
- DSA - Environment Setup
- DSA - Algorithms Basics
- DSA - Asymptotic Analysis
- Data Structures
- DSA - Data Structure Basics
- DSA - Data Structures and Types
- DSA - Array Data Structure
- Linked Lists
- DSA - Linked List Data Structure
- DSA - Doubly Linked List Data Structure
- DSA - Circular Linked List Data Structure
- Stack & Queue
- DSA - Stack Data Structure
- DSA - Expression Parsing
- DSA - Queue Data Structure
- Searching Algorithms
- DSA - Searching Algorithms
- DSA - Linear Search Algorithm
- DSA - Binary Search Algorithm
- DSA - Interpolation Search
- DSA - Jump Search Algorithm
- DSA - Exponential Search
- DSA - Fibonacci Search
- DSA - Sublist Search
- DSA - Hash Table
- Sorting Algorithms
- DSA - Sorting Algorithms
- DSA - Bubble Sort Algorithm
- DSA - Insertion Sort Algorithm
- DSA - Selection Sort Algorithm
- DSA - Merge Sort Algorithm
- DSA - Shell Sort Algorithm
- DSA - Heap Sort
- DSA - Bucket Sort Algorithm
- DSA - Counting Sort Algorithm
- DSA - Radix Sort Algorithm
- DSA - Quick Sort Algorithm
- Graph Data Structure
- DSA - Graph Data Structure
- DSA - Depth First Traversal
- DSA - Breadth First Traversal
- DSA - Spanning Tree
- Tree Data Structure
- DSA - Tree Data Structure
- DSA - Tree Traversal
- DSA - Binary Search Tree
- DSA - AVL Tree
- DSA - Red Black Trees
- DSA - B Trees
- DSA - B+ Trees
- DSA - Splay Trees
- DSA - Tries
- DSA - Heap Data Structure
- Recursion
- DSA - Recursion Algorithms
- DSA - Tower of Hanoi Using Recursion
- DSA - Fibonacci Series Using Recursion
- Divide and Conquer
- DSA - Divide and Conquer
- DSA - Max-Min Problem
- DSA - Strassen's Matrix Multiplication
- DSA - Karatsuba Algorithm
- Greedy Algorithms
- DSA - Greedy Algorithms
- DSA - Travelling Salesman Problem (Greedy Approach)
- DSA - Prim's Minimal Spanning Tree
- DSA - Kruskal's Minimal Spanning Tree
- DSA - Dijkstra's Shortest Path Algorithm
- DSA - Map Colouring Algorithm
- DSA - Fractional Knapsack Problem
- DSA - Job Sequencing with Deadline
- DSA - Optimal Merge Pattern Algorithm
- Dynamic Programming
- DSA - Dynamic Programming
- DSA - Matrix Chain Multiplication
- DSA - Floyd Warshall Algorithm
- DSA - 0-1 Knapsack Problem
- DSA - Longest Common Subsequence Algorithm
- DSA - Travelling Salesman Problem (Dynamic Approach)
- Approximation Algorithms
- DSA - Approximation Algorithms
- DSA - Vertex Cover Algorithm
- DSA - Set Cover Problem
- DSA - Travelling Salesman Problem (Approximation Approach)
- Randomized Algorithms
- DSA - Randomized Algorithms
- DSA - Randomized Quick Sort Algorithm
- DSA - Karger’s Minimum Cut Algorithm
- DSA - Fisher-Yates Shuffle Algorithm
- DSA Useful Resources
- DSA - Questions and Answers
- DSA - Quick Guide
- DSA - Useful Resources
- DSA - Discussion
Randomized Algorithms

Randomized algorithm is a different design approach taken by the standard algorithms where few random bits are added to a part of their logic. They are different from deterministic algorithms; deterministic algorithms follow a definite procedure to get the same output every time an input is passed where randomized algorithms produce a different output every time they’re executed. It is important to note that it is not the input that is randomized, but the logic of the standard algorithm.
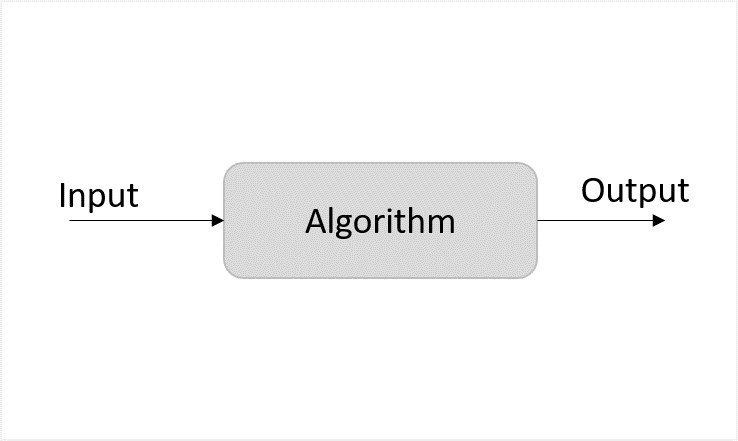
Figure 1: Deterministic Algorithm
Unlike deterministic algorithms, randomized algorithms consider randomized bits of the logic along with the input that in turn contribute towards obtaining the output.
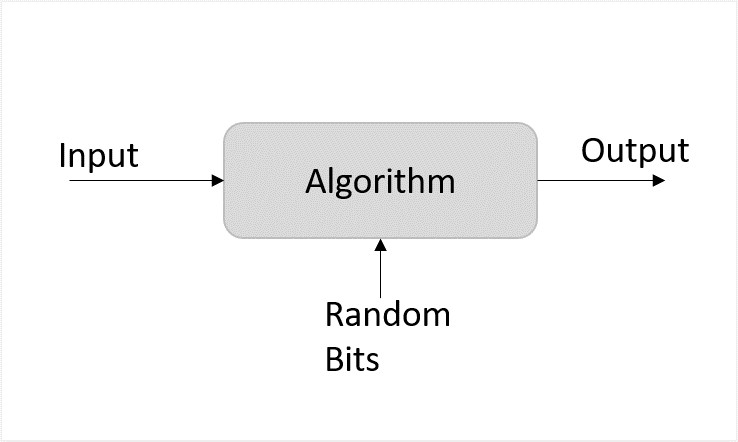
Figure 2: Randomized Algorithm
However, the probability of randomized algorithms providing incorrect output cannot be ruled out either. Hence, the process called amplification is performed to reduce the likelihood of these erroneous outputs. Amplification is also an algorithm that is applied to execute some parts of the randomized algorithms multiple times to increase the probability of correctness. However, too much amplification can also exceed the time constraints making the algorithm ineffective.
Classification of Randomized Algorithms
Randomized algorithms are classified based on whether they have time constraints as the random variable or deterministic values. They are designed in their two common forms − Las Vegas and Monte Carlo.
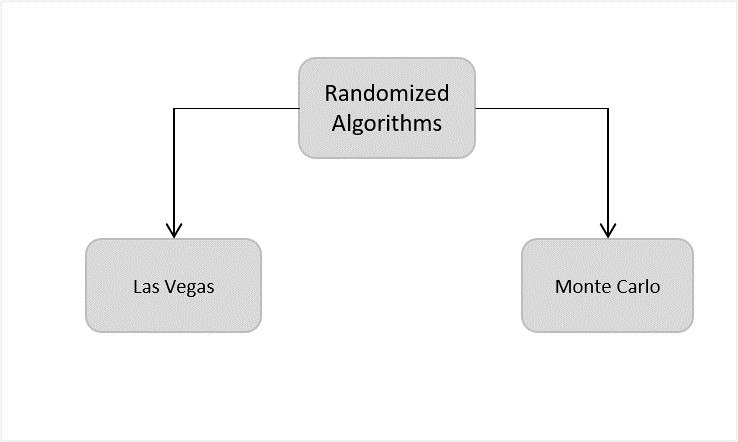
Las Vegas − The Las Vegas method of randomized algorithms never gives incorrect outputs, making the time constraint as the random variable. For example, in string matching algorithms, las vegas algorithms start from the beginning once they encounter an error. This increases the probability of correctness. Eg., Randomized Quick Sort Algorithm.
Monte Carlo − The Monte Carlo method of randomized algorithms focuses on finishing the execution within the given time constraint. Therefore, the running time of this method is deterministic. For example, in string matching, if monte carlo encounters an error, it restarts the algorithm from the same point. Thus, saving time. Eg., Karger’s Minimum Cut Algorithm
Need for Randomized Algorithms
This approach is usually adopted to reduce the time complexity and space complexity. But there might be some ambiguity about how adding randomness will decrease the runtime and memory stored, instead of increasing; we will understand that using the game theory.
The Game Theory and Randomized Algorithms
The basic idea of game theory actually provides with few models that help understand how decision-makers in a game interact with each other. These game theoretical models use assumptions to figure out the decision-making structure of the players in a game. The popular assumptions made by these theoretical models are that the players are both rational and take into account what the opponent player would decide to do in a particular situation of a game. We will apply this theory on randomized algorithms.
Zero-sum game
The zero-sum game is a mathematical representation of the game theory. It has two players where the result is a gain for one player while it is an equivalent loss to the other player. So, the net improvement is the sum of both players’ status which sums up to zero.
Randomized algorithms are based on the zero-sum game of designing an algorithm that gives lowest time complexity for all inputs. There are two players in the game; one designs the algorithm and the opponent provides with inputs for the algorithm. The player two needs to give the input in such a way that it will yield the worst time complexity for them to win the game. Whereas, the player one needs to design an algorithm that takes minimum time to execute any input given.
For example, consider the quick sort algorithm where the main algorithm starts from selecting the pivot element. But, if the player in zero-sum game chooses the sorted list as an input, the standard algorithm provides the worst case time complexity. Therefore, randomizing the pivot selection would execute the algorithm faster than the worst time complexity. However, even if the algorithm chose the first element as pivot randomly and obtains the worst time complexity, executing it another time with the same input will solve the problem since it chooses another pivot this time.
On the other hand, for algorithms like merge sort the time complexity does not depend on the input; even if the algorithm is randomized the time complexity will always remain the same. Hence, randomization is only applied on algorithms whose complexity depends on the input.
Examples
Few popular examples of the Randomized algorithms are −
The Subset Sum Problem