
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Why is git branching fast compared to other version control systems?
Branching allows us to diverge from the main line of work and work on something else in isolation. Conceptually, we can think of a branch as a separate isolated workspace. We have a main workspace called the master.
We can create a feature branch and work separately on the feature branch to add more features to the project without affecting the main line of work. If there is some error in the feature branch, we can fix it without affecting other collaborator’s work. Once everything is working properly in the feature branch, we can merge it with the main line of work, that is the master branch.
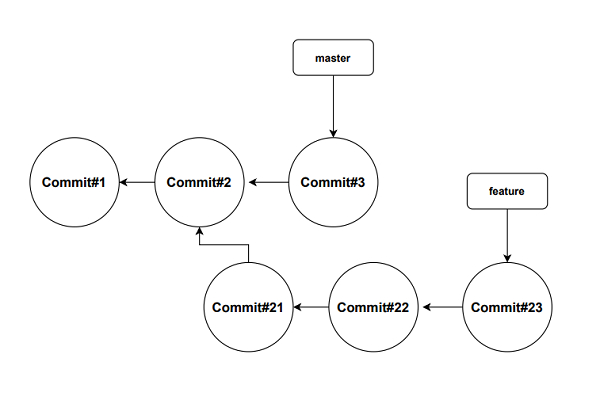
The above diagram shows there are two branches the master and one feature branch. The ‘commit#21’ is derived from the ‘commit#2’, so the feature branch contains all commits from ‘commit#1’ to ‘commit#23’ and the master branch contains ‘commit#1’,’commit#2’ and ‘commit#3’. The master and feature branches can work in isolation.
Branching allows us to work on different work items without messing up the code base of the main line of work. We keep the main line of work as stable as possible, so we can release it to production at any time. If a new developer joins the team, the new member can start using the stable code base from the master. That is the idea of branching.
How does Git manage branches differently?
If we use a Centralized Version Control System (CVCS) like ‘subversion’, when a new branch is created it will copy all contents from the main branch. This will result in a performance bottleneck if we have a large code base. Many people don't use branching in CVCS due to the fact that branching is slow and takes a lot of disk space.
Git branching is super−fast and cheap. In Git, branching is just a symbolic name pointing to the last commit. So, the master branch is always a pointer to the last commit in the main line of work. As we perform a new commit, Git moves the master reference forward automatically similar to a linked list.
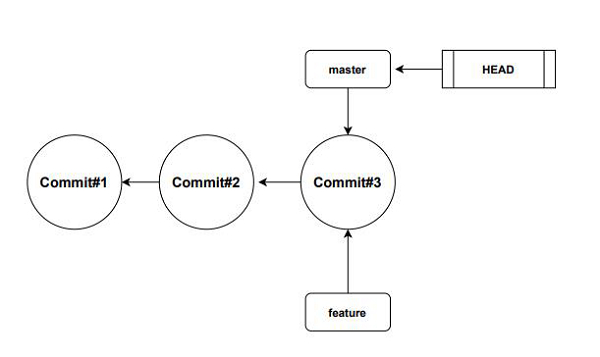
When we create a new branch, Git will create a new pointer (here, feature) pointing to the last commit. From the below diagram we can see that featureis just a pointer to the last commit. So, git branches are not copying any commit data, it just creates a pointer.
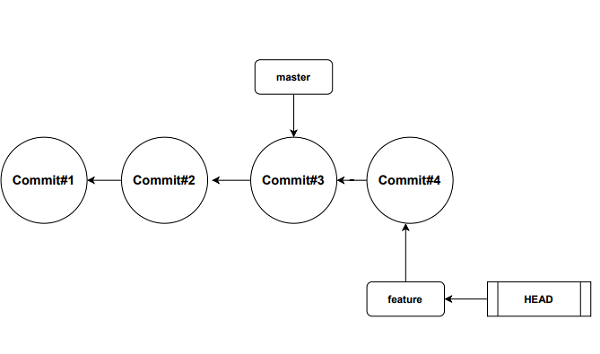
Now when we commit new changes in a newly created feature branch, the master pointer will remain intact, but the feature pointer will move ahead. This is shown in the diagram below. Initially, both the master and feature pointed to ‘commit#3’. Then we switched to the feature branch and performed a commit ‘commit#4’. So, the feature pointer moved ahead but the master branch pointer remained where it is. The HEAD pointer points to the current working branch.
432 Views
