
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is the Pipelined execution of Load/Store Instructions in Computer Architecture?
Load and Stores are frequent operations, especially in RISC code. While executing RISC code we can expect to encounter about 25-35% load instructions and about 10% store instructions. Hence, it is one of big significance to execute load and store instructions effectively.
It can summarize the subtasks which have to be performed during a load or store instructions as shown in the figure.
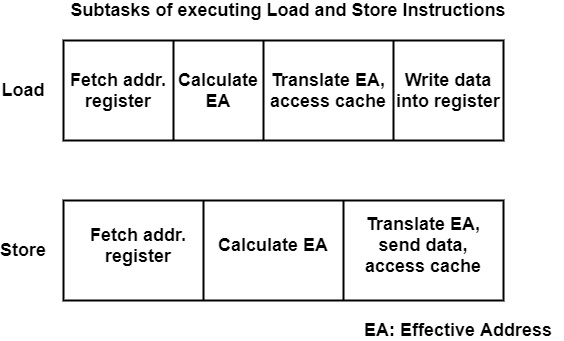
Let us first consider a load instruction. Its execution begins with the determination of the effective memory address (EA) from where data is to be fetched. In this case, like RISC processors, this can be done in two steps: fetching the referenced address register(s) and calculating the effective address.
In the CISC processor, address calculation may be a difficult task, requiring multiple subsequent registers fetches and address calculations, as in the case of indexed, post-incremented, relative addresses. Once the effective address is available, the next step is usually to forward the effective (virtual) address to the MMU for translation and to access the data cache.
In traditional pipeline implementations, load and store instructions are processed by the master pipeline. These loads and stores are executed sequentially with other instructions as shown in the figure.
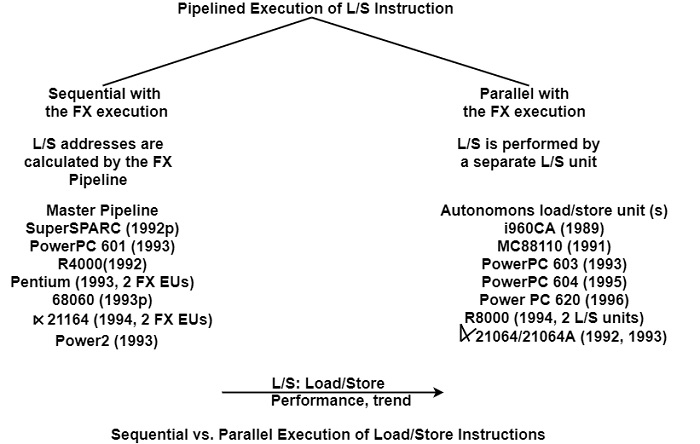
In this case, the required address calculation of a load/store instruction can be performed by the adder of the execution stage. However, one instruction slot is needed for each load or store instruction.
Representatives of this low-cost implementation approach are the MIPS R4000, Pentium (with two integer units), PowerPC 601, Power2, and DEC α 21164 (also with two integer units). At first glance, it is surprising that the α 21164 uses a sequential load/store processing technique when the preceding α 21064 and α 21064A provided a dedicated autonomous load/store unit.
A more effective address technique for load/store instructions processing is to do it in parallel with data manipulation as shown in the figure. This approach assumes the existence of an autonomous load/store unit that can perform address calculation on its own.
There is an increasing number of superscalar processors that implement an autonomous load/store unit. Examples of early designs are the i80960 CA or MC 88110. Most recent examples are the DEC α 21064, DEC α 21064A, PowerPC 603, PowerPC 604, PowerPC 620, and MIPS R8000.
Autonomous load/store units can either be operated lock-stepped with the processing of other instructions or work decoupled. In the lockstep, load and store requests to the memory (cache) are issued in order. Alternatively, the execution of load and stores can be decoupled from the execution of other instructions to boost performance. This can be achieved by providing queues for pending loads and stores and executing those operations from the queues.

2K+ Views
