
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is the Microarchitectural implementation of branch processing?
Branch processing comprises basic tasks, such as instruction fetch, decode and BTA calculation, and possibly additional dedicated tasks to speed up branch processing. These dedicated tasks may be early branch detection, branch prediction, or an advanced scheme for accessing target paths.
Usually, the dedicated tasks are executed using dedicated hardware, like a BTAC, BTIC, or BHT. There are two methods to the basic tasks. All earlier pipelined processors and many recent processors execute branches by utilizing the pipeline stages available for common instruction processing as shown in the figure −
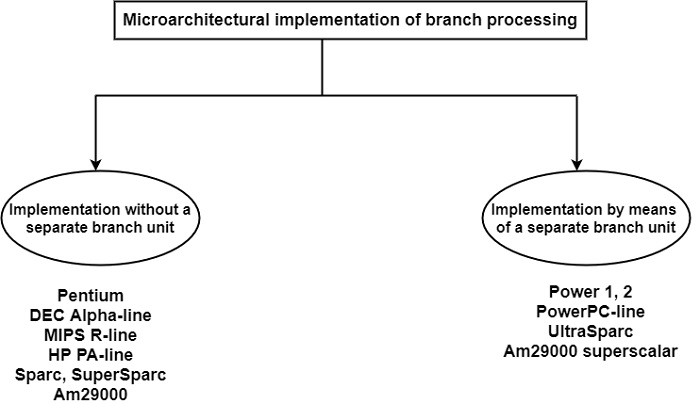
By contrast, some recent processors provide a separate unit, usually called a branch unit, to execute the basic tasks of branch processing. This approach decouples branch processing from general data manipulations and results in a more symmetrical structure of the microarchitecture. Furthermore, this approach also contributes to increased performance, since other units are released from subtasks of basic branch processing, such as address calculations.
Thus, branches can be processed in parallel with data manipulations. As shown in the figure, it shows the Power1, Power2, and PowerPC models follow this approach. Examples are the UltraSparc and Am29000 superscalar processors.
Branch penalties of processors using prediction
There is an effective technique to sharply reduce or to avoid, penalties for correctly predicted branches, such as the BTAC or the successor index in the I-cache schemes. Using these schemes, even zero-cycle branching is achievable as shown in the table. This table contains data on branch penalties in recent processors that use true static or dynamic prediction.
Branch Penalties in processors employing static or dynamic prediction
| Processor type | Penalty of a correctly predicted branch (cycles) | Penalty of a mispredicted branch (cycles) |
|---|---|---|
| MC 88110 (1993) | 0 | 2 |
| MC 68060 (1993) | Z | 7 |
| Pentium (1993) | 0 | 3-4 |
| Gmicro/500 (1993) | z/21 | n.a. |
| PA 7200 (1995) | n.a. | 0-1 |
| PA 8000 (1996) | z/22,3 | 5 |
| R 8000 (1994) | n.a. | 3 |
| R 10000(1996) | 13 | 1−46 |
| α21164(1995) | 0 | 5 |
| PowerPC 604 (1995) | $\frac{0^1}{1}$ −22 | 3 |
| PowerPC 620 (1996) | $\frac{0^1}{1^3}$ | 2 |
| Nx586 (1995) | Z | 54−195 |
If the branch address hints at the BTAC.
If the branch address does not hit the BTAC.
If there is enough instruction in the decoded queue, this latency may be partly or entirely hidden.
If the reservation station queues are empty.
If the reservation station queues are full (14 entries).
The R10000 allows at most 4 embedded pending predictions. The actual value of the misprediction penalty depends on the depth of misprediction.
Z means zero-cycle branching.
As shown in the table, its shows that although these techniques reduce misprediction penalties considerably, most recent processors require at least two or three cycles for recovery. The PA7200 and R10000 have in certain cases, only one or even no penalty cycles.
However, a misprediction penalty contributes to the effective branch penalty depends heavily on the prediction accuracy. The higher the prediction accuracy, the less a misprediction penalty impedes processor performance. For instance, for 90% prediction accuracy, a misprediction penalty of two cycles causes only a 0.1*2=0.2 cycle increase in the average branch penalty.

371 Views
