
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is the implementation of a Lexical Analyzer?
Lexical Analysis is the first step of the compiler which reads the source code one character at a time and transforms it into an array of tokens. The token is a meaningful collection of characters in a program. These tokens can be keywords including do, if, while etc. and identifiers including x, num, count, etc. and operator symbols including >,>=, +, etc., and punctuation symbols including parenthesis or commas. The output of the lexical analyzer phase passes to the next phase called syntax analyzer or parser.
The syntax analyser or parser is also known as parsing phase. It takes tokens as input from lexical analyser phase. The syntax analyser groups tokens together into syntactic structures. The output of this phase is parse tree.
Function of Lexical Analysis
The main function of lexical analysis are as follows −
It can separate tokens from the program and return those tokens to the parser as requested by it.
It can eliminate comments, whitespaces, newline characters, etc. from the string.
It can insert the token into the symbol table.
Lexical Analysis will return an integer number for each token to the parser.
Stripping out the comments and whitespace (tab, newline, blank, and other characters that are used to separate tokens in the input).
The correlating error messages that are produced by the compiler during lexical analyzer with the source program.
It can implement the expansion of macros, in the case of macro, pre-processors are used in the source code.
LEX generates Lexical Analyzer as its output by taking the LEX program as its input. LEX program is a collection of patterns (Regular Expression) and their corresponding Actions.
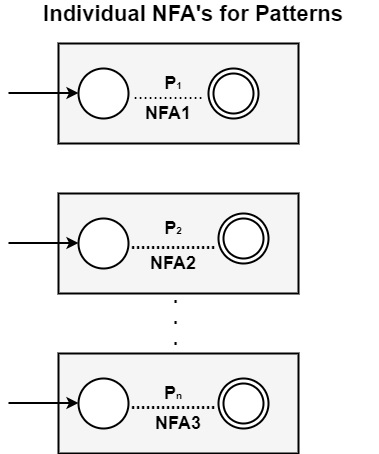
Patterns represent the tokens to be recognized by the lexical analyzer to be generated. For each pattern, a corresponding NFA will be designed.
There can be n number of NFAs for n number of patterns.
Example − If patterns are { }
P<sub>1</sub> { }
P<sub>2</sub> { }
P<sub>n</sub> { }
Then NFA’s for corresponding patterns will be −
A start state is taken and using ? transition, and all these NFAs can be connected to make combined NFA −
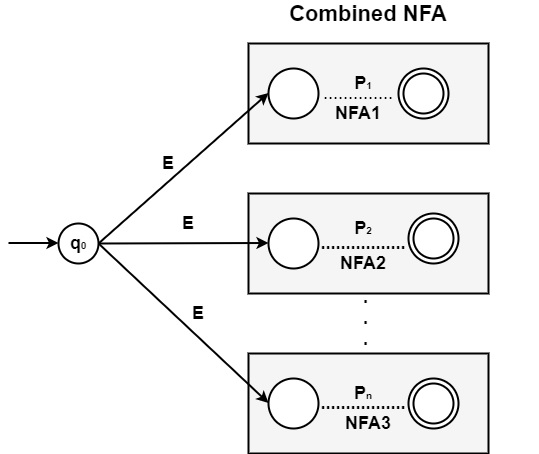
The final state of each NFA shows that it has found its token Pi.
It converts the combined NFA to DFA as it is always easy to simulate the behavior of DFA with a program.
The final state shows which token we have found. If none of the states of DFA includes any final states of NFA then control returns to an error condition.
If the final state of DFA includes more than one final state of NFA, then the final state, for the pattern coming first in the Translation rules has priority.

13K+ Views
