
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is Implementation of Syntax Directed Translators?
A syntax-directed translation scheme is a context-free grammar in which attributes are related to the grammar symbol and semantic actions enclosed within braces ({ }). These semantic actions are the subroutines that are known by the parser at the suitable time for translation. The location of the semantic actions on the right side of production denotes the time when it will be known for implementation by the parser.
When it can produce a translation scheme, it should provide that an attribute value is available when the action defines it. This needed that
Inherited attributes of a symbol on the right side of the production should be calculated in an action directly preceding (to the left of) that symbol because it can be defined as an action evaluating the inherited attribute of the symbol to the right of it.
An action that evaluates the synthesized attribute of a non-terminal on the left side of production should be located at the end of the right side of the production because it can defines the attributes of any of the right side grammar symbols.
Consider an example that consists of the production and its semantic action. The production is
E → E1 + E2
and its semantic action will be
{E. Val = E1. Val + E2. Val}
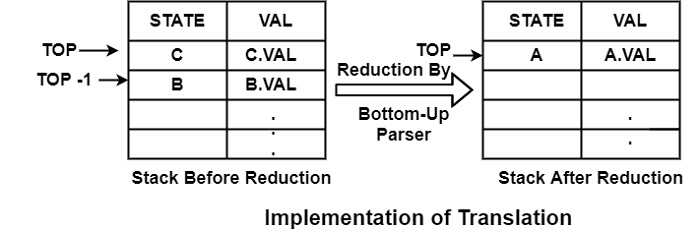
Syntax-directed translation provides a method for describing an input-output mapping and that description is independent of implementation. To implement Syntax Directed Translation, It can use a stack that consists of a pair of arrays STATE & VAL. Each STATE entry shows a pointer to the parsing table & each VAL represents the value associated with the corresponding STATE symbol.
STATE array consists of all the variables or identifiers that appeared in Context-Free Grammar, and VAL array consists of the values for each variable.
Example − For the Production
A → BC
To compute the translation of variable A, first of all, we have to insert B and C into the stack with their corresponding values B.VAL and C.VAL, respectively.
The Bottom-Up Parser will perform the translation when BC is reduced to A.
Before Reduction − Top pointer will point to the C variable, and VAL [TOP] consists of C.VAL.VAL [TOP-1] consist of B.VAL.
After Reduction − When BC will be reduced to A, both B and C with their corresponding values B.VAL and C.VAL will be popped & the A with A.VAL will be pushed onto the stack. So after reduction, the stack will have variable A on its stack TOP & VAL [TOP] will now consist of A.VAL.
∴ For Production A → BC

3K+ Views
