
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What are the different levels of Code Scheduling in computer architecture?
Code scheduling is used to cover dependency detection and resolution and parallel optimization. Code scheduling is generally adept in conjunction with traditional compilation. A code scheduler gets as input a set, or a sequence, of executable instruction, and a set of precedence constraints enforced on them, frequently in the form of a DAG. As output, it undertakes to deliver, in each scheduling phase, an instruction that is dependency-free and defines the best option for the schedule to manage the precise available execution time.
Traditional non-optimizing compilers can be treated as including two major parts. The front-end part of the compiler implements scanning, parsing, and semantic analysis of the source string and makes an intermediate representation. This intermediate form is generally described by an attributed abstract tree and a symbol table. The back-end part, in turn, creates the object code.
Traditional optimizing compilers speed up sequential execution and reduce the needed memory space generally by removing redundant operations. Sequential optimization needs a program analysis, which includes control flow, data flow, and dependency analysis in the front-end part.
There are two different approaches to merging traditional compilation and code scheduling. In the first, code scheduling is integrated into the compilation procedure. In this method, the code scheduler facilitates the results of the program analysis make by the front-end part of the compiler.
The code scheduler generally follows the traditional sequential optimizer in the back-end part, before register allocation and subsequent code generation. This type of code scheduling is known as pre-pass scheduling. The other approach is to help a traditional (sequentially) optimizing compiler and carry out code scheduling afterward called post-pass scheduling.
Code scheduling can be implemented at three different levels such as basic block, loop, and global level, as displayed in the figure.
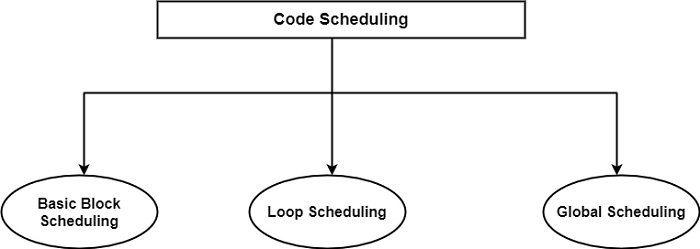
The associated scheduling techniques are known as basic block (or local), loop, and global techniques. These techniques increase performance in the order listed.
Basic Block Scheduling In this case, scheduling and code optimization is accomplished independently for each basic block, one after another.
Loop-Level Scheduling The next level of scheduling is loop-level scheduling. Therefore, instructions belonging to ensuing iterations of a loop can generally be overlapped, resulting in considerable speed-up.
It is generally accepted that loops are an important source of parallelism, particularly in mathematical programs. Hence, it is possible that for highly parallel ILP processors, including VLIW architectures, compilers must implement scheduling at least at the loop level. Therefore, a huge number of techniques have been developed for scheduling at this level.
Global Scheduling − The most efficient method to schedule is to do it at the largest possible level, using global scheduling techniques. Therefore, parallelism is desired and derived beyond basic blocks and simple loops, in such constructs as compound program methods containing loops and conditional control constructs.

3K+ Views
