- BigQuery - Home
- BigQuery - Overview
- BigQuery - Initial Setup
- BigQuery vs Local SQL Engines
- BigQuery - Google Cloud Console
- BigQuery - Google Cloud Hierarchy
- What is Dremel?
- What is BigQuery Studio?
- BigQuery - Datasets
- BigQuery - Tables
- BigQuery - Views
- BigQuery - Create Table
- BigQuery - Basic Schema Design
- BigQuery - Alter Table
- BigQuery - Copy Table
- Delete and Recover Table
- BigQuery - Populate Table
- Standard SQL vs Legacy SQL
- BigQuery - Write First Query
- BigQuery - CRUD Operations
- Partitioning & Clustering
- BigQuery - Data Types
- BigQuery - Complex Data Types
- BigQuery - STRUCT Data Type
- BigQuery - ARRAY Data Type
- BigQuery - JSON Data Type
- BigQuery - Table Metadata
- BigQuery - User-defined Functions
- Connecting to External Sources
- Integrate Scheduled Queries
- Integrate BigQuery API
- BigQuery - Integrate Airflow
- Integrate Connected Sheets
- Integrate Data Transfers
- BigQuery - Materialized View
- BigQuery - Roles & Permissions
- BigQuery - Query Optimization
- BigQuery - BI Engine
- Monitoring Usage & Performance
- BigQuery - Data Warehouse
- Challenges & Best Practices
BigQuery - Table Metadata
While being able to analyze and understand the scope and content of organizational data is important, it is also essential for SQL developers to understand aspects of performance and storage cost using BigQuery.
This is when querying BigQuery table metadata can be useful for developers and invaluable for organizations seeking to leverage the SQL engine to its fullest extent.
For those who have not worked extensively with metadata: Metadata is, as the name implies, data about data. Typically this relates to statistics surrounding things like resource performance or monitoring.
BigQuery offers several metadata stores that users can query to better understand how their project consumes resources, some of which include the following −
- INFORMATION_SCHEMA
- __TABLES__ view
- BigQuery audit logs
Each of these tables can be queried in the same way as stored data.
For both the INFORMATION_SCHEMA and __TABLES__ it is helpful to note there is a different syntax regarding the table reference.
Instead of following the typical: project.dataset.table notation, both INFORMATION_SCHEMA and __TABLES__ have elements that are referenced following the closing backtick.
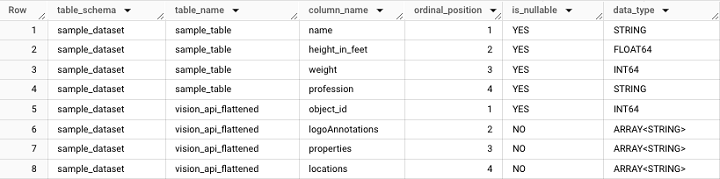
INFORMATION_SCHEMA is a data source that has several offshoot resources like COLUMNS or JOBS_BY_PROJECT
For instance, referencing the INFORMATION_SCHEMA looks like this −

It will fetch the following output −
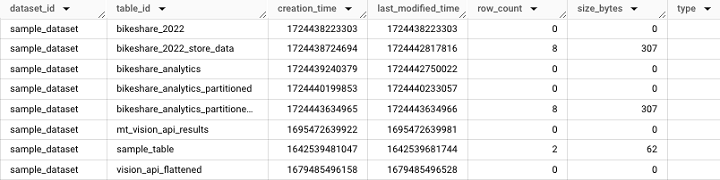
TABLES View
The TABLES view provides information at a table-level, such as table creation time and the user who last accessed the table. It is important to note that the TABLES view is accessible at the dataset level.

It will fetch the following output −
Creating a Schema Based on an Existing Table
One helpful use case for INFORMATION_SCHEMA.COLUMNS is the ability to create a schema based on an existing table using this query −

