- BigQuery - Home
- BigQuery - Overview
- BigQuery - Initial Setup
- BigQuery vs Local SQL Engines
- BigQuery - Google Cloud Console
- BigQuery - Google Cloud Hierarchy
- What is Dremel?
- What is BigQuery Studio?
- BigQuery - Datasets
- BigQuery - Tables
- BigQuery - Views
- BigQuery - Create Table
- BigQuery - Basic Schema Design
- BigQuery - Alter Table
- BigQuery - Copy Table
- Delete and Recover Table
- BigQuery - Populate Table
- Standard SQL vs Legacy SQL
- BigQuery - Write First Query
- BigQuery - CRUD Operations
- Partitioning & Clustering
- BigQuery - Data Types
- BigQuery - Complex Data Types
- BigQuery - STRUCT Data Type
- BigQuery - ARRAY Data Type
- BigQuery - JSON Data Type
- BigQuery - Table Metadata
- BigQuery - User-defined Functions
- Connecting to External Sources
- Integrate Scheduled Queries
- Integrate BigQuery API
- BigQuery - Integrate Airflow
- Integrate Connected Sheets
- Integrate Data Transfers
- BigQuery - Materialized View
- BigQuery - Roles & Permissions
- BigQuery - Query Optimization
- BigQuery - BI Engine
- Monitoring Usage & Performance
- BigQuery - Data Warehouse
- Challenges & Best Practices
BigQuery - Partitioning & Clustering
Since both "partitioning" and "clustering" have been used in this tutorial already, it's helpful to provide additional context.
What are Partitioning and Clustering?
Both terms are used to describe two methods of optimizing data storage and processing.
Partitioning is how a developer segments data, typically (but not always) by a date element like year, month or day. Clustering describes how data is sorted within the specified partition.
To use either storage method, you must define a desired field. Only one field may be used for partitioning but multiple fields may be used for clustering.
It's important to note that to apply either partitioning or clustering, you must do this at the "create table" stage of your build. Otherwise, you will be required to drop/recreate the table with the updated partitioning/clustering specs.
How to Apply Partitioning or Clustering to a Table
To apply partitioning and/or clustering to a table upon creation, run the following −
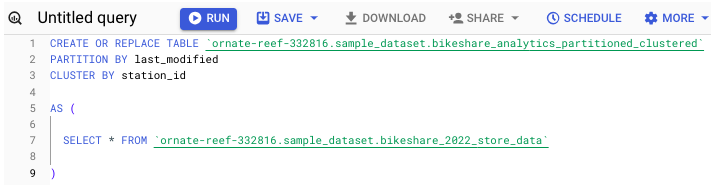
You can also specify these directions within the UI. Before hitting "create table", take a moment to fill in the fields found directly below the schema creation box.
If you apply the partitioning / clustering properly, it can significantly reduce both long-term storage cost and processing time, especially when querying a large table.
