- NLP - Home
- NLP - Introduction
- NLP - Linguistic Resources
- NLP - Word Level Analysis
- NLP - Syntactic Analysis
- NLP - Semantic Analysis
- NLP - Word Sense Disambiguation
- NLP - Discourse Processing
- NLP - Part of Speech (PoS) Tagging
- NLP - Inception
- NLP - Information Retrieval
- NLP - Applications of NLP
- NLP - Python
- Natural Language Processing Resources
- NLP - Quick Guide
- NLP - Useful Resources
- NLP - Discussion
NLP - Information Retrieval
Information retrieval (IR) may be defined as a software program that deals with the organization, storage, retrieval and evaluation of information from document repositories particularly textual information. The system assists users in finding the information they require but it does not explicitly return the answers of the questions. It informs the existence and location of documents that might consist of the required information. The documents that satisfy users requirement are called relevant documents. A perfect IR system will retrieve only relevant documents.
With the help of the following diagram, we can understand the process of information retrieval (IR) −
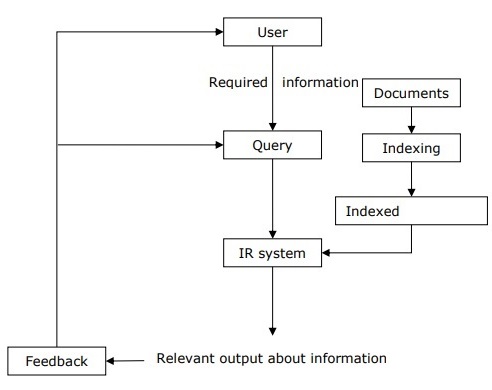
It is clear from the above diagram that a user who needs information will have to formulate a request in the form of query in natural language. Then the IR system will respond by retrieving the relevant output, in the form of documents, about the required information.
Classical Problem in Information Retrieval (IR) System
The main goal of IR research is to develop a model for retrieving information from the repositories of documents. Here, we are going to discuss a classical problem, named ad-hoc retrieval problem, related to the IR system.
In ad-hoc retrieval, the user must enter a query in natural language that describes the required information. Then the IR system will return the required documents related to the desired information. For example, suppose we are searching something on the Internet and it gives some exact pages that are relevant as per our requirement but there can be some non-relevant pages too. This is due to the ad-hoc retrieval problem.
Aspects of Ad-hoc Retrieval
Followings are some aspects of ad-hoc retrieval that are addressed in IR research −
How users with the help of relevance feedback can improve original formulation of a query?
How to implement database merging, i.e., how results from different text databases can be merged into one result set?
How to handle partly corrupted data? Which models are appropriate for the same?
Information Retrieval (IR) Model
Mathematically, models are used in many scientific areas having objective to understand some phenomenon in the real world. A model of information retrieval predicts and explains what a user will find in relevance to the given query. IR model is basically a pattern that defines the above-mentioned aspects of retrieval procedure and consists of the following −
A model for documents.
A model for queries.
A matching function that compares queries to documents.
Mathematically, a retrieval model consists of −
D − Representation for documents.
R − Representation for queries.
F − The modeling framework for D, Q along with relationship between them.
R (q,di) − A similarity function which orders the documents with respect to the query. It is also called ranking.
Types of Information Retrieval (IR) Model
An information model (IR) model can be classified into the following three models −
Classical IR Model
It is the simplest and easy to implement IR model. This model is based on mathematical knowledge that was easily recognized and understood as well. Boolean, Vector and Probabilistic are the three classical IR models.
Non-Classical IR Model
It is completely opposite to classical IR model. Such kind of IR models are based on principles other than similarity, probability, Boolean operations. Information logic model, situation theory model and interaction models are the examples of non-classical IR model.
Alternative IR Model
It is the enhancement of classical IR model making use of some specific techniques from some other fields. Cluster model, fuzzy model and latent semantic indexing (LSI) models are the example of alternative IR model.
Design features of Information retrieval (IR) systems
Let us now learn about the design features of IR systems −
Inverted Index
The primary data structure of most of the IR systems is in the form of inverted index. We can define an inverted index as a data structure that list, for every word, all documents that contain it and frequency of the occurrences in document. It makes it easy to search for hits of a query word.
Stop Word Elimination
Stop words are those high frequency words that are deemed unlikely to be useful for searching. They have less semantic weights. All such kind of words are in a list called stop list. For example, articles a, an, the and prepositions like in, of, for, at etc. are the examples of stop words. The size of the inverted index can be significantly reduced by stop list. As per Zipfs law, a stop list covering a few dozen words reduces the size of inverted index by almost half. On the other hand, sometimes the elimination of stop word may cause elimination of the term that is useful for searching. For example, if we eliminate the alphabet A from Vitamin A then it would have no significance.
Stemming
Stemming, the simplified form of morphological analysis, is the heuristic process of extracting the base form of words by chopping off the ends of words. For example, the words laughing, laughs, laughed would be stemmed to the root word laugh.
In our subsequent sections, we will discuss about some important and useful IR models.
The Boolean Model
It is the oldest information retrieval (IR) model. The model is based on set theory and the Boolean algebra, where documents are sets of terms and queries are Boolean expressions on terms. The Boolean model can be defined as −
D − A set of words, i.e., the indexing terms present in a document. Here, each term is either present (1) or absent (0).
Q − A Boolean expression, where terms are the index terms and operators are logical products − AND, logical sum − OR and logical difference − NOT
F − Boolean algebra over sets of terms as well as over sets of documents
If we talk about the relevance feedback, then in Boolean IR model the Relevance prediction can be defined as follows −
R − A document is predicted as relevant to the query expression if and only if it satisfies the query expression as −
(( ) )
We can explain this model by a query term as an unambiguous definition of a set of documents.
For example, the query term economic defines the set of documents that are indexed with the term economic.
Now, what would be the result after combining terms with Boolean AND Operator? It will define a document set that is smaller than or equal to the document sets of any of the single terms. For example, the query with terms social and economic will produce the documents set of documents that are indexed with both the terms. In other words, document set with the intersection of both the sets.
Now, what would be the result after combining terms with Boolean OR operator? It will define a document set that is bigger than or equal to the document sets of any of the single terms. For example, the query with terms social or economic will produce the documents set of documents that are indexed with either the term social or economic. In other words, document set with the union of both the sets.
Advantages of the Boolean Mode
The advantages of the Boolean model are as follows −
The simplest model, which is based on sets.
Easy to understand and implement.
It only retrieves exact matches
It gives the user, a sense of control over the system.
Disadvantages of the Boolean Model
The disadvantages of the Boolean model are as follows −
The models similarity function is Boolean. Hence, there would be no partial matches. This can be annoying for the users.
In this model, the Boolean operator usage has much more influence than a critical word.
The query language is expressive, but it is complicated too.
No ranking for retrieved documents.
Vector Space Model
Due to the above disadvantages of the Boolean model, Gerard Salton and his colleagues suggested a model, which is based on Luhns similarity criterion. The similarity criterion formulated by Luhn states, the more two representations agreed in given elements and their distribution, the higher would be the probability of their representing similar information.
Consider the following important points to understand more about the Vector Space Model −
The index representations (documents) and the queries are considered as vectors embedded in a high dimensional Euclidean space.
The similarity measure of a document vector to a query vector is usually the cosine of the angle between them.
Cosine Similarity Measure Formula
Cosine is a normalized dot product, which can be calculated with the help of the following formula −
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
Vector Space Representation with Query and Document
The query and documents are represented by a two-dimensional vector space. The terms are car and insurance. There is one query and three documents in the vector space.
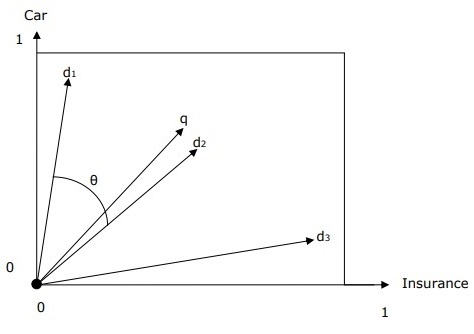
The top ranked document in response to the terms car and insurance will be the document d2 because the angle between q and d2 is the smallest. The reason behind this is that both the concepts car and insurance are salient in d2 and hence have the high weights. On the other side, d1 and d3 also mention both the terms but in each case, one of them is not a centrally important term in the document.
Term Weighting
Term weighting means the weights on the terms in vector space. Higher the weight of the term, greater would be the impact of the term on cosine. More weights should be assigned to the more important terms in the model. Now the question that arises here is how can we model this.
One way to do this is to count the words in a document as its term weight. However, do you think it would be effective method?
Another method, which is more effective, is to use term frequency (tfij), document frequency (dfi) and collection frequency (cfi).
Term Frequency (tfij)
It may be defined as the number of occurrences of wi in dj. The information that is captured by term frequency is how salient a word is within the given document or in other words we can say that the higher the term frequency the more that word is a good description of the content of that document.
Document Frequency (dfi)
It may be defined as the total number of documents in the collection in which wi occurs. It is an indicator of informativeness. Semantically focused words will occur several times in the document unlike the semantically unfocused words.
Collection Frequency (cfi)
It may be defined as the total number of occurrences of wi in the collection.
Mathematically, $df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
Forms of Document Frequency Weighting
Let us now learn about the different forms of document frequency weighting. The forms are described below −
Term Frequency Factor
This is also classified as the term frequency factor, which means that if a term t appears often in a document then a query containing t should retrieve that document. We can combine words term frequency (tfij) and document frequency (dfi) into a single weight as follows −
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
Here N is the total number of documents.
Inverse Document Frequency (idf)
This is another form of document frequency weighting and often called idf weighting or inverse document frequency weighting. The important point of idf weighting is that the terms scarcity across the collection is a measure of its importance and importance is inversely proportional to frequency of occurrence.
Mathematically,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
Here,
N = documents in the collection
nt = documents containing term t
User Query Improvement
The primary goal of any information retrieval system must be accuracy − to produce relevant documents as per the users requirement. However, the question that arises here is how can we improve the output by improving users query formation style. Certainly, the output of any IR system is dependent on the users query and a well-formatted query will produce more accurate results. The user can improve his/her query with the help of relevance feedback, an important aspect of any IR model.
Relevance Feedback
Relevance feedback takes the output that is initially returned from the given query. This initial output can be used to gather user information and to know whether that output is relevant to perform a new query or not. The feedbacks can be classified as follows −
Explicit Feedback
It may be defined as the feedback that is obtained from the assessors of relevance. These assessors will also indicate the relevance of a document retrieved from the query. In order to improve query retrieval performance, the relevance feedback information needs to be interpolated with the original query.
Assessors or other users of the system may indicate the relevance explicitly by using the following relevance systems −
Binary relevance system − This relevance feedback system indicates that a document is either relevant (1) or irrelevant (0) for a given query.
Graded relevance system − The graded relevance feedback system indicates the relevance of a document, for a given query, on the basis of grading by using numbers, letters or descriptions. The description can be like not relevant, somewhat relevant, very relevant or relevant.
Implicit Feedback
It is the feedback that is inferred from user behavior. The behavior includes the duration of time user spent viewing a document, which document is selected for viewing and which is not, page browsing and scrolling actions, etc. One of the best examples of implicit feedback is dwell time, which is a measure of how much time a user spends viewing the page linked to in a search result.
Pseudo Feedback
It is also called Blind feedback. It provides a method for automatic local analysis. The manual part of relevance feedback is automated with the help of Pseudo relevance feedback so that the user gets improved retrieval performance without an extended interaction. The main advantage of this feedback system is that it does not require assessors like in explicit relevance feedback system.
Consider the following steps to implement this feedback −
Step 1 − First, the result returned by initial query must be taken as relevant result. The range of relevant result must be in top 10-50 results.
Step 2 − Now, select the top 20-30 terms from the documents using for instance term frequency(tf)-inverse document frequency(idf) weight.
Step 3 − Add these terms to the query and match the returned documents. Then return the most relevant documents.
