
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is Compute/Fetch scheme in computer architecture?
This scheme is the common approach to accessing branch targets. First, the branch target address (BTA) is evaluated either by the pipeline or by a dedicated adder. Thus, the matching branch target instruction (BTI) is fetched. In current processors, this defines access to the I-cache, whereas in initial pipelined processors without an I-cache, the memory is accessed.
As shown in the figure, bits go into the details of the compute/fetch scheme. The instruction fetch address (IFA) is maintained in the instruction fetch address register (IFAR), which is usually called the Program Counter (PC) in a sequential environment. It can start the execution of a particular program, the IFA is set to its initial value, referred to as IIFA (initial instruction fetch address).
In the absence of branches, the IFA is incremented after each access to get the next sequential address. When a branch is encountered, the next sequential address is overwritten by the computed branch target address (BTA), and the corresponding instruction cache (I-cache) entry is fetched.
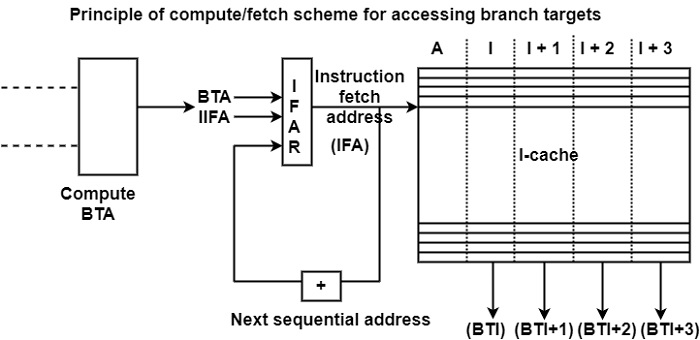
When a branch is detected, the branch target address (BTA) is evaluated. In this case, the next sequential address is overwritten by the BTA. Thus the BTA becomes the next instruction fetch address (IFA). Then in the next cycle, the corresponding branch target instruction (BTI) is read from the instruction cache (I-cache).
This scheme is employed in earlier scalar processors and in some recent scalar and superscalar processors, including Z80000 (1984), i486 (1989), MC 68040 (1990), Sparc CY7C601 (1998), SuperSparc (1992p), Power1 (1990), Power2 (1993), PowerPC 601 (1993), 603 (1993), α 21064A (1994), α 21164 (1995), R4000 (1992), R10000 (1996).
It can assume a cache with a cache line length of 16 bytes and capable of delivering four four-byte instructions in each cycle. It can presume a fast cache that delivers the contents of an address, given in cycle i, in the next cycle, that is, in cycle i + 1. Furthermore, it can assume branch target instructions (BTIs) to be aligned so that the first target instruction is always in the first position, that is, in the position, I is shown in the figure.
The calculate/fetch scheme is straightforward and does not need any additional hardware. This is the standard branch target accessing scheme used in all earlier and some recent scalar processors, such as the i486 and the R4000.
Several superscalar processors also employ this simple scheme, like the SuperSparc, Power1, Power2, and the first PowerPC implementations, such as the PowerPC 601 and PowerPC 603, and the α implementations α21064,α 21064A, and α21164.
The drawback of this method is the sequential manner of the BTA calculation and BTI access. This can cause a considerable taken-path access penalty, except when branches are detected and BTA calculations are performed early enough.

379 Views
