
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is Parallel Decoding in Computer Architecture?
A scalar processor has to decode only a single instruction in each cycle as shown in the figure. In addition, a pipelined processor has to check for dependencies to decide whether this instruction can be issued or not. In comparison, a superscalar processor has to perform a much more complex task.
As shown in the figure, it has to decode multiple instructions, say four, in a single clock cycle. It also needs to check for dependencies from two perspectives: First, whether the instructions to be issued are dependent on the instructions currently in execution. Second, whether there are dependencies among the instructions which are candidates for the next issues.
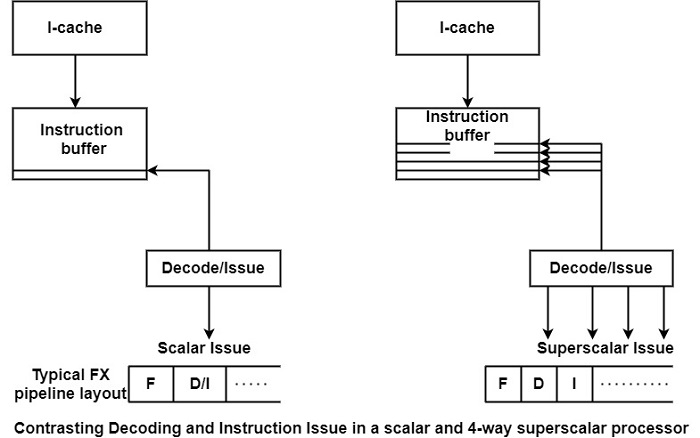
Since a superscalar processor has more EUs than a scalar one, the number of execution instructions is far higher than in the scalar case. This means that more comparisons have to be performed in the course of dependency checks. The decode-issue path of the superscalar processor is a much more critical issue in achieving a high clock frequency than that of scalar processors.
Superscalar processors tend to use two, even three, or more pipeline cycles for decoding and issuing instructions. For instance, the PowerPC 601, PowerPC 604, and UltraSparc need 2 cycles, while the α 21064 requires 3 cycles and the PentiumPro even needs 4.5 cycles. One way to cope with this problem is through pre-decoding.
Predecoding shifts a part of the decoding task up into the loading phase of the on-chip instruction cache (I-cache) as shown in the figure.
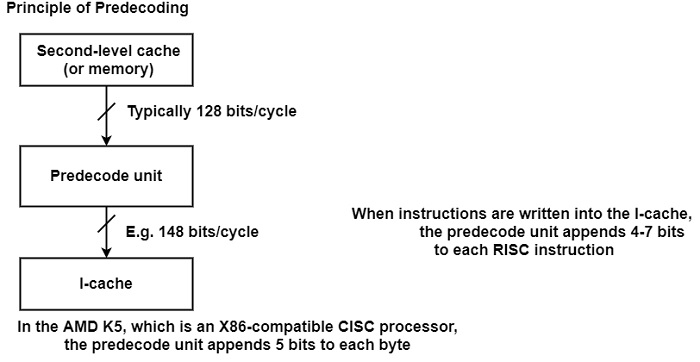
Here, while the I-cache is being loaded, a dedicated unit is called the predecoded unit. It executes partial decoding and joins several decode bits to each instruction. In the case of RISC processors, for example, 4-7 bits are usually attached which indicate −
the instruction class
the type of resources that are required for the execution and
in some processors even the fact that branch target address has already been calculated during pre-decoding like in the Hal PM1 or the UltraSparc.
The number of the pre-decoded unit are shown in the table.
Number of pre-decode bits used
| Type/year of first volume shipment | Number of pre-decode bits appended to each instruction |
|---|---|
| PA 7200 (1995) | 5 |
| PA 8000 (1996) | 5 |
| PowerPC 620 (1996) | 7 |
| UltraSparc (1995) | 4 |
| HAL PM1 (1995) | 4 |
| AMD K5 (1995) | 5 |
| R10000 (1996) | 4 |
For a CISC processor such as the AMD, K5 pre-decoding can determine where an instruction starts or ends, where the opcodes and prefixes are, and so on. This requires quite a large number of extra bits. The K5 adds five extra bits to each byte. Thus, in this case, more than 70% additional storage space is needed in the instruction cache.
Predecoding is used either to shorten the overall cycle time or to reduce the number of cycles needed for decoding and instruction issues. For instance, pre-decoding the PowerPC 620, R10000, and Hal’s PM1 require only a single cycle for decoding and issue.

2K+ Views
