
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What are the techniques to avoid hotspots in computer architecture?
In multistage network-based shared memory systems, thousands of processors can try for a similar memory location. This location is called a hotspot and can significantly enlarge latency in the interconnection network. When two processors attempt to access the same memory location, their message will conflict in one of the switches no matter which interconnection network is used (crossbar or multistage). They come at two multiple inputs to the switch but need to exit at the equivalent output.
Queuing Network temporarily influences the second message in the switch by using a queue store able to hold a short number of messages. Despite the switch queues, queuing networks are quite vulnerable to network saturation. Experiments showed that even if only a very small percentage of all accesses are aimed at a particular memory location, the presence of the hotspot will affect not only the processors requesting access to the hotspot but also the other processors trying to use the network.
Waiting messages hold switch resources, restricting the availability of such resources for a message coming from other processors. As a consequence, additional messages are blocked, holding yet more resources, and hotspot saturation propagate back through the network in a tree-like fashion is shown in the figure.
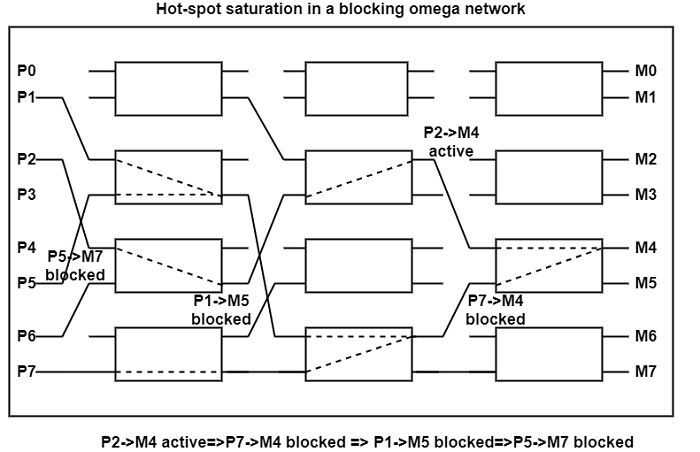
Non-Queuing Networks refuse the second message so that ineffective messages retreat and leave the network free. It gives other messages requiring different paths a chance to get through the network. The rejection of conflicting messages decreases the network bandwidth to O (N/logN).
In a queuing network message, P7→M4 is blocked, and hence message P1→M5 is prevented from getting through. This results in the blocking of message P5→M7. This case demonstrates that processors attempting to access different memory modules are delayed by the hotspot. In a non-queuing network, the P5→M7 message has no obstacle since P1→M5 would be rejected by the network.
There is another way of reducing the effect of hotspots in a switching network is to introduce combining switches. These identify that two messages are directed to a similar memory module and in such cases, they can merge the two messages into one.
This method is specifically advantageous in the execution of synchronization tools like semaphores and barriers which are generally accessed by several processes running on specific processors. Switching networks that employ combining switches are called combining networks.
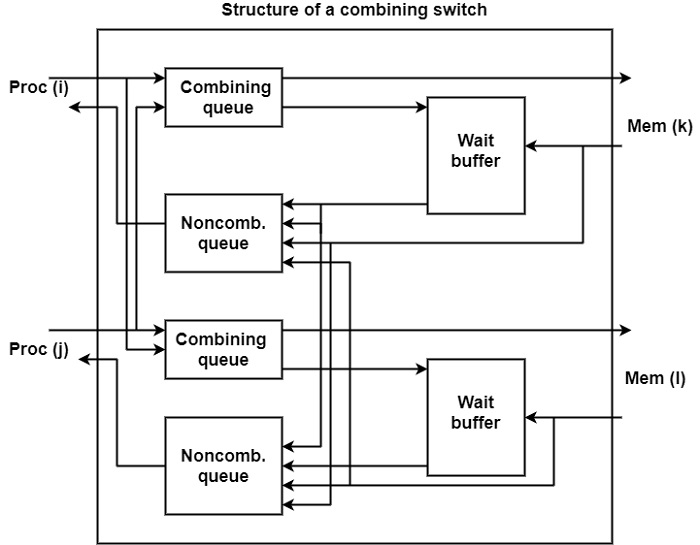
The structure of the combining switch used in the NYU Ultracomputer is shown in the figure. The memory requests from Pi and Pj enter two combining queues, one for the Mk and one for the Ml memory block. If two requests refer to the same memory address the corresponding combining queue forwards one request to the memory block and place the second request in the associated wait buffer.

418 Views
