- SEO - Home
- SEO - What is SEO?
- SEO - Tactics & Methods
- SEO - On Page Techniques
- SEO - Off Page Techniques
- SEO - Web Site Domain
- SEO - Relevant Filenames
- SEO - Design & Layout
- SEO - Optimized Keywords
- SEO - Long-tail Keywords
- SEO - Title Tags
- SEO - Meta Description
- SEO - Optimized Metatags
- SEO - Optimize for Google
- SEO - Robots.txt
- SEO - URL Structure
- SEO - Headings
- SEO - Redirects
- SEO - Authority & Trust
- SEO - PDF Files
- SEO - Optimized Anchor
- SEO - Optimize Images
- SEO - Duplicate Content
- SEO - Meta Robots Tag
- SEO - Nofollow Links
- SEO - XML Sitemap
- SEO - Canonical URL
- SEO - Role of UI/UX
- SEO - Keyword Gap Analysis
- SEO - Get Quality Backlinks
- SEO - Adding Schema Markup
- SEO - Author Authority
- SEO - Fix Broken Links
- SEO - Internal Page Linking
- SEO - Clean Up Toxic Links
- SEO - Earn Authority Backlinks
- SEO - Core Web Vitals
- SEO - Update Old Content
- SEO - Fill Content Gaps
- SEO - Link Building
- SEO - Featured Snippets
- SEO - Remove URLS from Google
- SEO - Content is the King
- SEO - Verifying Web Site
- SEO - Multiple Media Types
- SEO - Google Passage Ranking
- SEO - Maximize Social Shares
- SEO - First Link Priority Rule
- SEO - Optimize Page Load Time
- SEO - Hiring an Expert
- SEO - Learn EAT Principle
- SEO - Mobile SEO Techniques
- SEO - Avoid Negative Tactics
- SEO - Misc Techniques
- SEO - Continuous Site Audit
- SEO - Summary
- SEO Useful Resources
- SEO - Quick Guide
- SEO - Useful Resources
- SEO - Discussion
SEO - Duplicate Content
Duplicate Content: What Is It?
Content identical or remarkably similar to content found on separate websites or distinct sections of a single webpage is called duplicate content. A website's search engine ranking may suffer if it has a significant amount of identical material. The term refers to a location with a specific website address (URL); therefore, duplicate content exists when exact content exists at many web addresses.
Consequences of Duplicate Content
There are several consequences in search engine results; sometimes, there are even monetary penalties when websites containing the same content are published. Among the most typical problems with duplicating material are −
Webpages that are displayed in SERPs have an inappropriate copied version.
Unexpectedly, original websites rank lower in search engine result pages (SERPs) or have indexing issues.
Changes or declines in key site metrics like traffic, rankings, or E-A-T standards.
Due to conflicting prioritization signals, search engine algorithms may take additional unanticipated measures against valid websites.

Why is it essential to avoid duplicate content?
For search engines, the same material can cause three problems in particular −
Lack of Technical Algorithm − They need more technical expertise to decide which versions to index and which ones to leave out. Due to various algorithmic factors, they often display duplicate or copied content material higher in SERP than the original content.
Statistical Issues − They need help allocating the connection statistics, such as trust, authority, anchor text, link equity, etc., among several content versions on different websites. When content gets similar across multiple sites, the evaluation and ranking factors get disturbed, and the consumer gets affected along with website owners.
Confusion between Different Editions − They struggle to determine which version or versions to prioritize for search engine results. Due to failed prioritization, they often display identical contents simultaneously, one after the other.
Owners of websites may experience losses in ranks and visitors when duplicated material is publicly accessible. These financial losses frequently result from two key issues −
Capital Losses − Since competing sites must decide between duplicate content, link equity, capital investment and returns and profits from links and advertisements may be significantly diluted. Inbound links divide linking capital among the duplicates by linking to numerous pieces of published material rather than just one, as opposed to all of the inbound links referring to a single item of content. Therefore, the online exposure of a piece of data may be affected since inbound links serve as a ranking component.
Lower SERP Rankings − Search engine algorithms rarely display numerous versions of comparable data to give users an optimal search experience; consequently, they are compelled to select the most probable version to produce the most accurate results. Each of the copies becomes less noticeable as a result. And the original content suffers from this online limitation or exposure.

Duplicate Content Problems: How Do They Arise?
Owners of websites typically do not purposefully produce duplicate content. That being said, it still might exist. According to specific projections, a quarter of the internet may include duplicate content.
Here are a few of the most typical unintentional instances in which duplicate data is produced −
Variants on URLs
Duplicate content problems can be caused by URL parameters like traffic management parameters, CTR trackers, analytical source codes and certain statistics codes. The sequence whereby these parameters occur in the URL itself may also pose an issue, in addition to the parameters themselves.
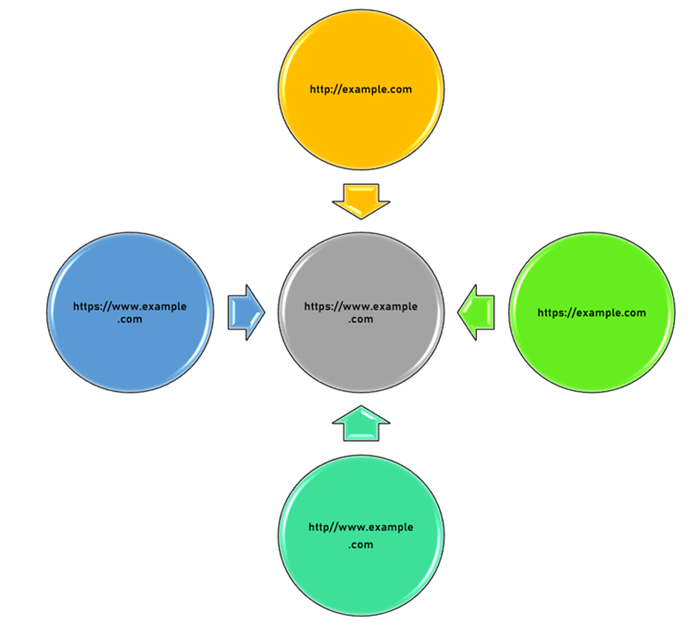
Protocol and Sub-Domain
If the identical material is present across both the website's editions at "www.example.com" and "example.com," you have duplicated each web page. The exact situation is for websites with both http:// and https:// versions.
Product Specifications
Product details sections are included in the content, journal entries and written content. The identical material ends up in several places on the internet if many websites selling the same products utilise the manufacturer's representations of these goods.

Fixing Duplicate Content Conflicts
Structure
It is advisable to take a broad look at the structure of your website as a place to begin. Whether you are working with a new, up-to-date or updated document, the first step is to mark up all the pages using a site crawl and give each one a distinct H1 and core keyword.
Redirect Code 301
Setting up a 301 link redirect to connect the "duplicate" webpage to the original material webpage works most effectively in many cases to avoid duplicate content.
rel=canonical attribute
Utilising the rel="canonical" feature is an additional option for handling duplicate content. This notifies search engine crawlers that a particular website must be regarded as duplicating a specific URL.
<meta name="robots" content="noindex,follow">
Usually combined with the parameters "noindex, follow," the meta tag meta robots can be beneficial when confronted with duplicated material. Any website that must be blocked from the search engine's indexing can have this meta robots tag in its HTML head.
Verify that the Website Redirects Are Done Properly
Your website's various versions should all land in a single address.
What Happens If My Content Is Not Copy-Righted?
If someone has replicated your work and you still need to mark it as the original piece with a canonical tag, this is a problem. Test these −
Find out how often the website is getting indexed using Search Console.
Request for acknowledgement or elimination of copyby contacting the website administrator that used your content without permission.
To guarantee that what you publish is acknowledged as the "authentic source" of the data, utilize self-referencing canonical tags on each new section of content you post.
Conclusion
Making distinctive, high-quality material for your website is the first step in preventing duplicate content. However, the procedures to reduce the chance that others may steal what you offer might be challengingthinking carefully about web design and concentrating on your users' experiences while on your website is the most effective method to prevent duplicate content problems. The strategies mentioned should lessen the risk to your website if content duplication happens due to technological causes.
